


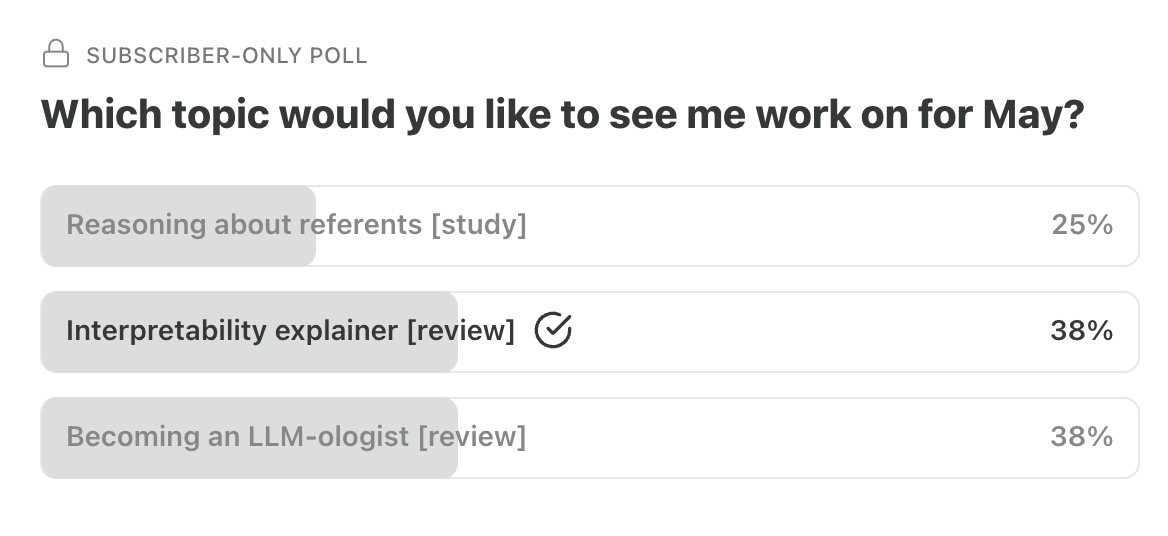
This month’s poll presented three options:
An empirical study assessing GPT-4’s ability to reason about visual referents in a communication game (based on a famous “tangrams” task).
An explainer on mechanistic interpretability.
A guide to “becoming an LLM-ologist”.
Each option enjoyed some support, but the explainer and the guide ended up with an equal share of votes (38% each).
I thought a bit about how to proceed, and given the interest in both, I think it makes the most sense to just do both! So my plan is to write pieces on both of these topics in the next few months. (As I mentioned in my last post, June will likely be a slow month for me.) Of course, there’ll also be some other posts mixed in as usual.
Additional news and updates
In my last update, I mentioned an exchange I’d had with Benjamin Riley of Cognitive Resonance over email. Part two of that discussion is now published, which includes my thoughts about the role of empirical methods in trying to understanding LLMs.
I’m also pleased to announce that I have two more published papers out this month. The first is a collaboration with Cameron Jones (who’ll be presenting it in Italy this week), investigating whether multimodal LLMs show evidence of “sensorimotor grounding”—a topic of great interest to psycholinguists, and of increased relevance to LLM-ology given the rise of multimodal systems like ChatGPT-4o. The second is a collaboration with Hagyeong Shin, a graduate student in the Linguistics department here at UCSD, investigating pragmatic understanding in Korean language models. As I’ve written before, lots of contemporary research on LLMs is pretty English-centric, so I was really excited to conduct research on a language other than English.
As always, thanks for reading!