
How to evaluate statistical claims
How to evaluate statistical claims
Some core lessons from statistics and research methods.

Each year, I teach classes on statistics, research methods, and computational social science (among other things). There are lots of details packed into those ten-week courses, including math, theory, and programming. But I also encourage students to reflect on some key, high-level takeaways from those courses that—hopefully—they can carry with them throughout their lives as they encounter and evaluate various claims.
The goal of this post is to distill what I take to be the most important, immediately applicable, and generalizable insights from these classes. That means that readers should be able to apply those insights without a background in math or knowing how to, say, build a linear model in R. In that way, it’ll be similar to my previous post about “useful cognitive lenses to see through”, but with a greater focus on evaluating claims specifically.
Lesson #1: Consider the whole distribution, not just the central tendency.
If you spend much time reading news articles or social media posts, the odds are good you’ll encounter some descriptive statistics: numbers summarizing or describing a distribution (a set of numbers or values in a dataset). One of the most commonly used descriptive statistics is the arithmetic mean: the sum of every value in a distribution, divided by the number of values overall. The arithmetic mean is a measure of “central tendency”, which just means it’s a way to characterize the typical or expected value in that distribution.
The arithmetic mean is a really useful measure. But as many readers might already know, it’s not perfect. It’s strongly affected by outliers—values that are really different from the rest of the distribution—and things like the skew of a distribution (see the image below for examples of skewed distribution).
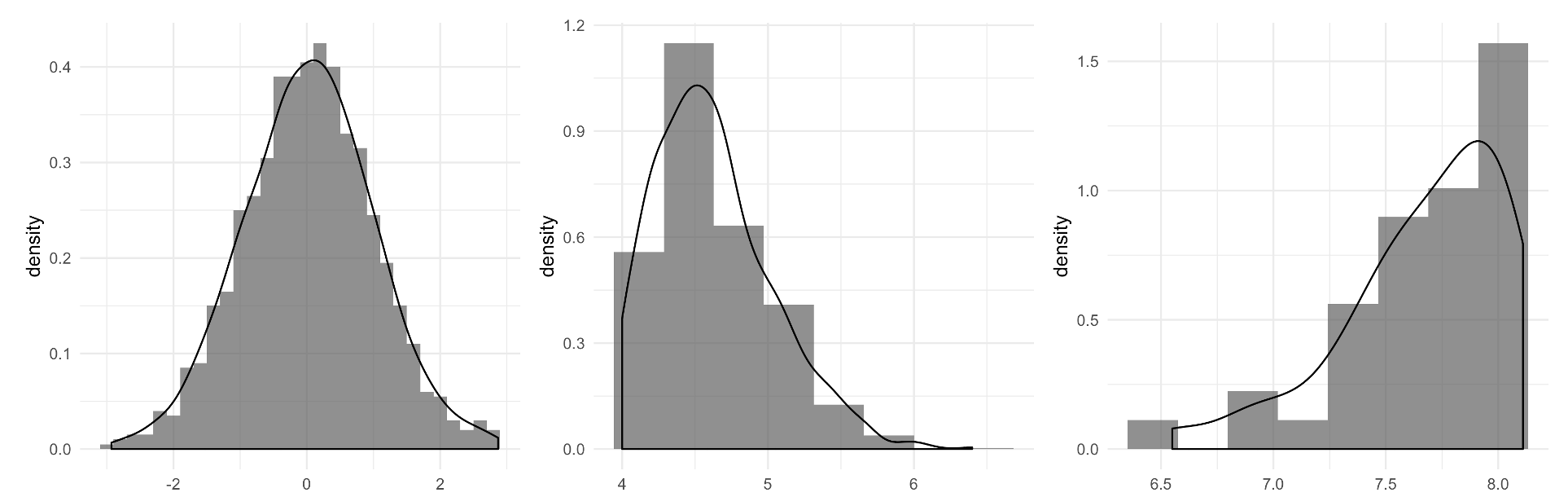
In particular, the mean is pulled in the direction of outliers or distribution skew. That’s the logic behind the joke about the average salary of people at a bar jumping up as soon as a billionaire walks in. It’s also why other measures of central tendency, such as the median, are often presented alongside (or instead of) the mean—especially for distributions that happen to be very skewed, such as income or wealth.
It’s not that one of these measures is more “correct”. As Stephen Jay Gould wrote in his article The Median Is Not the Message, they’re just different perspectives on the same distribution:
A politician in power might say with pride, “The mean income of our citizens is $15,000 per year.” The leader of the opposition might retort, “But half our citizens make less than $10,000 per year.” Both are right, but neither cites a statistic with impassive objectivity. The first invokes a mean, the second a median. (Means are higher than medians in such cases because one millionaire may outweigh hundreds of poor people in setting a mean, but can balance only one mendicant in calculating a median.)
I think everyone would benefit from keeping this distinction in mind. But I’d also go one step further: no measure of central tendency—not the mean, not the median, not the mode—tells the whole story about a distribution. Thus, it’s incredibly useful to think about the rest of the distribution as well.
By “think about the rest of the distribution”, I mean a couple things.
First, you could try to obtain measures of variance, including the distribution’s range (the difference between the minimum and maximum values) and standard deviation (a measure of the typical amount that values deviate from the distribution’s mean). But even these measures collapse across lots of interesting information.
Second, then, you could try to visualize the distribution itself. It’s become more common in academic papers to show things like histograms, which represent the frequency or probability of different values in a distribution (the three plots above are all examples). In my experience, this is less common in claims shared on social media. In the cases where visualizing the whole distribution isn’t possible, you can simply ask yourself: is there anything about my interpretation of this statistical claim that would change if I saw the whole distribution? What are the different ways that the distribution could look that might change the inferences I’d draw?
As Gould points out, a classic example here is something like income or wealth. If someone tells you the average income has gone up or down, that’s interesting—but it doesn’t tell you about whether that increase or decrease is driven by changes across the whole distribution, or whether it’s driven by a few outliers with an outsized effect.
Lesson #2: What’s the baseline?
As I’ve written before, numbers don’t stand on their own. Particularly in the context of numbers presented in news articles or social media posts, numbers are typically presented as part of an argument, and thus invite the reader—either explicitly or implicitly—to draw some sort of inference. But in order to draw an inference, it’s very important to think about the baseline (or baselines). By “baseline” I simply mean: a point of comparison, with which you can establish some expectation.
The simplest kind of inference (and baseline) concerns claims that are basically about whether a number is very large or very small. In a previous post, I used the example of the federal budget of the United States. If someone gives you a number (say, $33B), the only way to know whether that number is particularly big or particularly small is to have a point of comparison. That could mean other numbers in the federal budget, it could mean the amount (likely in relative terms) that other countries spend on the relevant line items, or it could mean something else altogether. The point is that you want to establish an expectation and draw a contrast.
Another kind of baseline is what sometimes gets called a control group in research design. If you want to know whether some intervention produces an effect—a vaccine, say, or a change in the tax code—it’s important to measure not only changes associated with the sample of individuals receiving the intervention but also some other sample of individuals who didn’t receive it (or received some other intervention). Without a comparison group, it’s impossible to know whether the outcomes you observe in the intervention (or “treatment”) group are due to the intervention itself or just what you’d expect even if you’d done nothing.
Baselines are also important for evaluating numerical claims, like “conditions A leads to different outcomes than condition B”. This kind of claim is really common in experimental psychology, but it’s also common in disciplines like public health and medicine (with treatment vs. placebo groups being a classic example of an experimental manipulation). Suppose we find some numerical difference in our outcome measure—whether that’s reaction time, accuracy on a comprehension assessment, or something else. How do we know whether that difference is a “real” difference? Because of sampling error—two independent samples from the same population are very unlikely to have the same exact mean or variance—it’s possible to find some numerical difference in an outcome measure between our conditions even if the manipulation didn’t really do anything. That’s why traditionally, researchers use something called null hypothesis significance testing (or “NHST”), in which a statistic calculated using your actual data is compared to some theoretical distribution of statistics you’d expect if the null hypothesis were true (e.g., the true difference between conditions was zero). You can think of these theoretical distributions as baselines.
Even if you’re not a fan of NHST—and lots of people aren’t—you still need some kind of statistical baseline. Some researchers use something called a permutation test, in which you randomly swap observations between your conditions and create your own null distribution.
Of course, sometimes the right baseline or “null hypothesis” isn’t that the effect is zero. Often, theoretical debates hinge on differences in magnitude. In these cases, you’ll want to be even more precise about the baseline or baselines you use to evaluate a claim.
I’ll give a brief example of how this could work. A 2012 paper argued that homophones like “river bank” and “financial bank” make language more efficient. One piece of evidence in support of this theory is that short words (which are generally presumed to be more efficient to produce and understand) tend to have more meanings, i.e., they are more ambiguous. This is what you’d expect if ambiguity were distributed efficiently, so the positive correlation between “length” and “ambiguity” was interpreted as evidence for efficiency at work.
But as I argued in a 2020 paper, you’d also expect a positive correlation between “length” and “ambiguity” even if there were no direct pressure for efficiency. Even if you constructed a language somewhat at random with no regard for efficiently reusing the shortest wordforms, you’d be more likely to “accidentally” duplicate short words—simply because they’re shorter. My co-author Ben Bergen and I showed that this was true by simulating a bunch of artificial languages—in essence, creating baselines—that we could then compare to actual human languages. We found that the distribution of ambiguity in real human languages was no more efficient—at least not by the original paper’s operationalization—than in the baselines.
Now, our own method and interpretation could be disputed or modified (and have); we made certain assumptions about how to model an “artificial language”, which amount to assumptions about the kind of baseline that should be used for asking a question like this. Critically, however, the dispute isn’t necessarily over whether a baseline is necessary. It’s about what the right kind of baseline should be. And answering that question is hard, because it requires thinking carefully about the various data-generating processes that could give rise to an empirical observation. Which brings me to the next point…
Lesson #3: What’s the data-generating process?
In my introductory statistics class, I tell students there’s a positive correlation between ice cream sales and number of shark attacks. I even show them that this is true with real data. Then I ask them to generate explanations for this relationship. Does ice cream make people more likely to go swimming? Are sharks more excited about eating people when they’ve just eaten some ice cream? Asserting a direct causal relationship here is plainly absurd—there’s probably a third variable we haven’t considered, like temperature. At least in coastal cities, higher temperatures probably lead to more ice cream sales; they also probably cause more people to go swimming, which could raise the incidence of shark attacks.
Notice that I’ve told a story here about how the empirical relationship we observed came to be, i.e., a story about the data-generating process: the “process” by which a given set of empirical observations (the “data”) was created (“generated”).
On some level, anyone making a claim about data—especially a causal claim—is implicitly or explicitly telling a story about the data-generating process. That story, in turn, might be relatively informal, as in a verbal description of a relationship; or it could be quite formal, as in a computational or statistical model. In either case, it’s impossible to know whether that story is right or wrong, since we never know the “ground truth”. But being explicit about what story we think we’re telling is important nonetheless, since it helps us recognize when there are gaps in the story—or when other, alternative, stories are more plausible.
Some of my favorite illustrations of the importance of modeling the data-generating process come from Richard McElreath’s Statistical Rethinking, a textbook about how to do statistics in an honest and clear way. In many cases, laying out our assumptions about the data-generating process means drawing some kind of causal diagram, sometimes called a “directed acyclic graph” (or “DAG”). This sounds fancy, but it really just means mapping out all the variables we’re interested in and then drawing arrows that represent the causal relationships we think might exist. Going through this process can help us identify things like confounds (temperature in the example above).
It can also help us diagnose more complex failure modes, like collider bias (also known as “Berkson’s Paradox”). Collider bias arises when the data under investigation have been subject to some kind of selection filter, which can produce spurious correlations between variables that are otherwise unrelated. For example, let’s suppose there’s a negative relationship between the “trustworthiness” and “newsworthiness” of a scientific finding (assuming we have a way to measure those things). One possible explanation is that trustworthy researchers work on more boring things, or that flashy researchers are less trustworthy. However, it’s also possible that these variables are unrelated, but that published findings are subject to a selection filter: namely, they must be sufficiently trustworthy or sufficiently newsworthy to be published. This could lead to a negative relationship between trustworthiness and newsworthiness among the published papers, since as the untrustworthy, boring results have been selected out of the dataset.
Once you know what it is, the potential for collider bias shows up everywhere. Let’s consider one last example, just to drive the point home: suppose all the burger joints in town have either really good milkshakes and bad fries, or really good fries and bad milkshakes. Why is this the case? Well, collider bias could be the culprit. All the restaurants with bad fries and bad milkshakes are more likely to go out of business. So if the only restaurants that survive this selection process are those with good milkshakes and bad fries, good fries and bad milkshakes, or good milkshakes and good fries, then there might be a (slightly) negative relationship between milkshake quality and fry quality among the restaurants still in business.
Lesson #4: Claims can be invalid in different ways
There are different types of claims. Some claims are about the frequency of an event (“5 out of 10 people text while driving”), some claims are about associations between things (“happiness and life expectancy are positively correlated”), and other claims are about causal relationships between things (“being happy makes you live longer”).
Just as there are different types of claims, any given claim can be evaluated on multiple grounds. To put it more technically: claims can be invalid in different ways. In empirical research, there are at least four “validities” you should consider when evaluating a claim: construct validity, external validity, internal validity, and statistical validity.
I’ve written about construct validity at some length before. Construct validity basically means: are the researchers actually measuring what they say they’re measuring? For example, is the “Happiness Scale 2.0” (something I just made up) a fair way to operationalize happiness?
I’ve also touched on external validity in my post about how GPT-4 is “WEIRD”. External validity refers to whether the sample used to make a claim is representative of the broader population of interest. A large proportion of behavioral and medical research is not representative, i.e., it was conducted on a biased sample. This means that generalizing from the sample to the population of interest is problematic.
Internal validity is most important for causal claims, and refers to the assurance that the causal relationship being tested is not influenced by any confounds. If I asserted that higher ice cream sales lead to more shark attacks, that’s an example of a causal claim lacking internal validity: I haven’t done my due diligence to rule out potential confounds, like temperature. Eliminating confounds is really hard, which is why randomized controlled trials (or “RCTs”) are so valuable: by randomly assigning people to one condition or another, we intrinsically control for potential confounds among our sample of participants, allowing us to isolate the effect of our key experimental manipulation. Of course, RCTs aren’t always practically or ethically possible, which is why researchers—especially in disciplines like economics, epidemiology, and sociology—have to rely on statistical modeling techniques that try to account for potential confounds. At the same time, opinions differ on the reliability of those techniques, which is why RCTs are generally considered the “gold standard” for establishing a causal effect.
Statistical validity refers to whether the claim being made is backed up by the proper use of statistics. If I just reported the difference in some outcome measure across my conditions, but didn’t give any measure of the variance in each condition or run any kind of statistical test, concluding that “the manipulation produced a difference” would not be supported by the statistics. People don’t always agree on what kinds of statistical analyses are most appropriate for a given claim, but at the very least, it’s important to consider what kinds of statistical evidence are being brought to bear on the claim at hand.
Finally, these different validities matter to different extents for different kinds of claims. Internal validity doesn’t really mean much for claims about the overall frequency of an event, but it’s absolutely essential for claims about causal relationships. External validity is arguably most important for claims about the overall frequency of something. But construct validity is always important, which is why (as I wrote before) it’s my favorite validity.
Evaluating claims is hard—but there are tools to guide you
Anytime you open up social media or a news article, there’s a good chance you’ll come across some kind of claim. As a consumer of information, it’s often hard to know how to evaluate these claims. We don’t have enough time or expertise to read all the requisite papers, dive into the data (if it’s even available), or reproduce the statistical analyses ourselves. The whole process can be dizzying and even lead to a kind of epistemic nihilism.
But it is possible to make some sense of it. At the very least, you can try to do a few things:
Think about whether the claim is revealing the entire distribution of data or whether it’s only tracking the central tendency.
Think about whether an adequate baseline has been established—what’s the comparison group?
If relevant, think about the plausible “stories” by which a given empirical relationship could come to be.
Think about all the ways that the claim could be wrong.
The goal here is careful consideration, not exhaustive analysis. I certainly fail to apply these guidelines all the time when I encounter claims. And there are, of course, other things I’ve neglected to mention here. My hope, though, is that each application of this template makes the next application a little easier, and over time it’ll be closer to something like second nature.
Related posts:
Beautifully written, nice insights!