Do Large Language Models have a "theory of mind"?
LLMs "pass" multiple tests of mental state reasoning, but fail others—what does this mean?


Note: This post is co-authored by Cameron Jones, a PhD student at UC San Diego (and research collaborator). You can find his website here.
We often reason about other people’s beliefs, even when they don’t believe the same things we believe. We do the same thing when it comes to emotions: most people can infer whether someone else is feeling sad, even if we’re not sad ourselves.
We don’t do this just because it’s fun; rather, this information is useful. It can help us to explain someone’s behavior (“Why did he say that?”), predict what they might do next (“Is he going to get upset?”), and guide our own behavior (“What can I say to make sure that doesn’t happen?”). This ability to reason about the mental states of other social agents—sometimes called “Theory of Mind” or “mentalizing”—appears to be a core aspect of human intelligence. Historically, some have even argued Theory of Mind is uniquely human.
And then early in 2023, large language models (LLMs) like ChatGPT were released. At least superficially, these models seemed to display an uncanny understanding of not just language but social interaction more broadly. This prompted a flurry of interest in whether—and to what extent—LLMs also have Theory of Mind. Answering this question matters for a few reasons. First, and most importantly, it matters for predicting how the widespread deployment of LLMs will impact society. For example, some worry about LLMs “deceiving” their users. Intentionally deceiving another person likely requires a mental model of what that person believes. So if we’re concerned about LLMs eventually deceiving us, it might help to figure out whether LLMs have a Theory of Mind—and critically, how LLMs learn to represent beliefs in the first place.
There are also more academic reasons for being interested in this question. It matters for those of us working in the emerging field of “LLM-ology” (or “machine psychology”). And as one of us (Sean) has argued before, it also might help shed light on how it is that humans reason about the mental states of others.
So do LLMs have a Theory of Mind? Unfortunately, it’s hard to answer that question definitively. On some measures, LLMs are approaching (or even exceeding) human performance; on others, LLMs perform essentially at chance levels. In this post, we’ll review the evidence for and against the claim, then circle back to the question of what Theory of Mind is and what it means to measure it.
Background: Theory of Mind in Biological Organisms
Broadly, “Theory of Mind” is the ability to ascribe mental states to oneself and others, and further, to reason about those mental states.
Researchers have been interested in this ability for decades. As early as 1944, psychologists Fritz Heider and Marianne Simmel noticed that humans had a curious tendency to ascribe intentions and beliefs even to simple geometrical shapes moving on a screen. Although this anthropomorphism sometimes gets us in trouble, many psychologists have argued that it reflects a social adaptation: we reflexively construe other entities as social agents, complete with their beliefs, desires, and intentions. One central debate is whether this ability is biologically evolved (and innate) or learned (i.e., through social interaction).
Thus far, psychologists have tried to answer this big question by focusing on two sub-questions—both of which have sparked considerable and ongoing debate. First, when exactly do typically developing children form a Theory of Mind? The traditional answer was around 3-4 years of age, but some argue for an earlier stage, like 2 years or even 15 months. Second, do other, non-human animals have Theory of Mind? Again, the traditional answer was “no”, but more recent evidence has found evidence in support of the claim—at least for other great apes.
These debates take for granted that Theory of Mind is a single “thing” that underpins our ability to reason about people’s beliefs, goals, and desires. But there’s growing evidence that performance on tasks that measure these different things aren’t as strongly correlated as you’d think. In technical terms, we’d say they exhibit poor convergent validity. This has led some to suggest that the construct “Theory of Mind” is less valid than initially assumed (a good reminder that you can’t escape construct validity). If Theory of Mind is a disparate collection of skills, it’s much harder to address the question: “where did Theory of Mind come from?” Different abilities may have emerged at different points in time, either during biological evolution or during development.
We’ll revisit these questions and debates later in the article, but for now, they’ll be useful to keep in mind as we review the evidence for and against Theory of Mind in LLMs.
Do LLMs represent false beliefs?
A core aspect of Theory of Mind is the ability to ascribe beliefs to other agents and reason about those beliefs. But how do we measure whether someone can reason about the beliefs of others? If Sean’s beliefs are correlated with Cameron’s beliefs, then it’s hard to differentiate whether Sean is reasoning about Cameron’s beliefs or simply reasoning about his own beliefs. The False Belief Task (FBT) solves this problem by creating scenarios in which the beliefs of two agents diverge, thus testing whether participants can represent the beliefs of another agent, even when those beliefs are wrong.
Here’s an example of how a written version of the task might look:
Patrick and Nicole are sitting at the train station, waiting for their train. Patrick takes out the ticket to check it and puts it away in the suitcase, then grabs his camera from the backpack. Then he gets up to take photos of the trains. Patrick doesn't see Nicole take the ticket out of the suitcase and place it in the backpack. Patrick comes back to sit at the table with Nicole. He wants to check the ticket one more time.
The subject would then be asked something like: where will Patrick look for the tickets?
If people behave egocentrically—that is, if they assume everyone shares the same beliefs they do—then they’ll predict that Patrick will look in the backpack (where the tickets actually are). But if people are paying attention to the fact that Patrick hasn’t updated his beliefs about where the tickets are, then they should predict that Patrick will look in the suitcase (where the tickets originally were). That is, if people have a Theory of Mind, their predictions about Patrick’s behavior will be consistent with what Patrick likely believes about the world.
What we did
In recently published (and pre-registered) work, we adapted this task so that it could be administered to an LLM. First, we created a set of 12 novel scenarios similar in structure to the one above. Because LLMs are trained on massive amounts of text data, it was important to create entirely new scenarios to avoid “data contamination”—i.e., the possibility that the LLM had observed the scenario in its training data. For further control, we also created a number of different versions of each scenario with the following manipulations: whether the other character was present when the object was moved (True Belief vs. False Belief), whether the start or end location of the object was mentioned first, and whether the “cue” probing the character’s beliefs was explicit (“Patrick thinks the tickets are in the …”) or implicit (“Patrick looks for the tickets in the …”).
We focused on a specific model released by OpenAI called text-davinci-002. This was the best LLM available at the time that wasn’t trained using reinforcement learning with human feedback, or RLHF. RLHF introduces a bunch of additional information into the model’s training signal, which makes it a much better digital assistant, but makes it harder to figure out whether a model’s abilities come from tracking textual statistics (what we were interested in) or from that additional, human-generated signal (a topic for future work).
We presented each passage to the LLM with the final word missing (e.g., “Patrick looks for the tickets in the …”). Because LLMs are predictive models, we could then compare the probability the LLM assigned to completing this sentence with either the original location of the tickets (the suitcase) or the final location (the backpack). We converted these probabilities to a measure called the log-odds. A larger (more positive) value of the log-odds meant that the model assigned a higher probability to Patrick looking in the suitcase; a smaller (more negative) value of the log-odds meant that the wallet was more likely; and a value of exactly zero meant that both locations were equally likely.
If LLMs are sensitive to Patrick’s beliefs, the log-odds should be larger when Patrick doesn’t know the tickets have moved (Patrick will look in the original location) and smaller when Patrick does know (Patrick will look in the new location). On the other hand, if LLMs don’t have a Theory of Mind, log-odds should not vary significantly as a function of what Patrick knows or doesn’t know.
What we found
Our results were more consistent with the “Theory of Mind” hypothesis.
That is, the LLM made different predictions about where a character would look depending on that character’s beliefs. Log-odds was larger in the False Belief condition, and smaller in the True Belief condition. This means that the LLM was sensitive to a character’s belief in the way you’d expect if the LLM was able to represent beliefs—even false ones.
The figure below illustrates the distribution of log-odds values for the True Belief and False Belief conditions. Overall, there’s a pretty clear effect: regardless of whether mental states are probed implicitly or explicitly, the red distributions (the False Belief condition) are further shifted to the right than the blue distributions (the True Belief condition).

To simplify the results a bit, we used these log-odds values to calculate an accuracy score. By this measure, the LLM answered correctly ~74.5% of the time—by no means perfect performance, but also well above chance levels of 50%.
A human baseline
One challenge with interpreting these results is that it’s unclear what would constitute “typical human” performance. GPT-3 is above chance, to be sure—and significantly so—but does that mean it has human levels of Theory of Mind? Neurotypical adults are usually assumed to perform at close to ~100%, which would put GPT-3 roughly midway between chance and human performance. But is it really the case that humans perform at 100% here?
What we need is a human benchmark: an estimate of how well humans would do on this very same task, on average. If LLM performance falls below that benchmark, it suggests that LLMs have acquired something qualitatively similar to human false belief representation but not at the same level of ability; if LLM performance attains (or even exceeds) the benchmark, it’s good evidence that “average” human Theory of Mind has been achieved by the LLM tested.
We ran the same task on a sample of over 1000 participants sampled from Amazon Mechanical Turk. Each person was presented with one of the 12 scenarios (again with the final word missing) and asked to complete the passage. We removed participants who responded with neither the start nor the end location of the object, as well as participants who failed an “attention check” designed to catch participants who only skimmed the passage. After applying these pre-registered exclusion criteria, we were left with 613 participants.
(Side note: that’s quite a big exclusion rate—almost half the original sample—but as one of us (Sean) has written before, it’s not inconsistent with other work using Mechanical Turk. For LLM skeptics out there, it’s also worth noting that this high exclusion rate primarily served to increase our estimate of human performance on the task; that is, we removed participants who would otherwise have decreased the average human performance.)
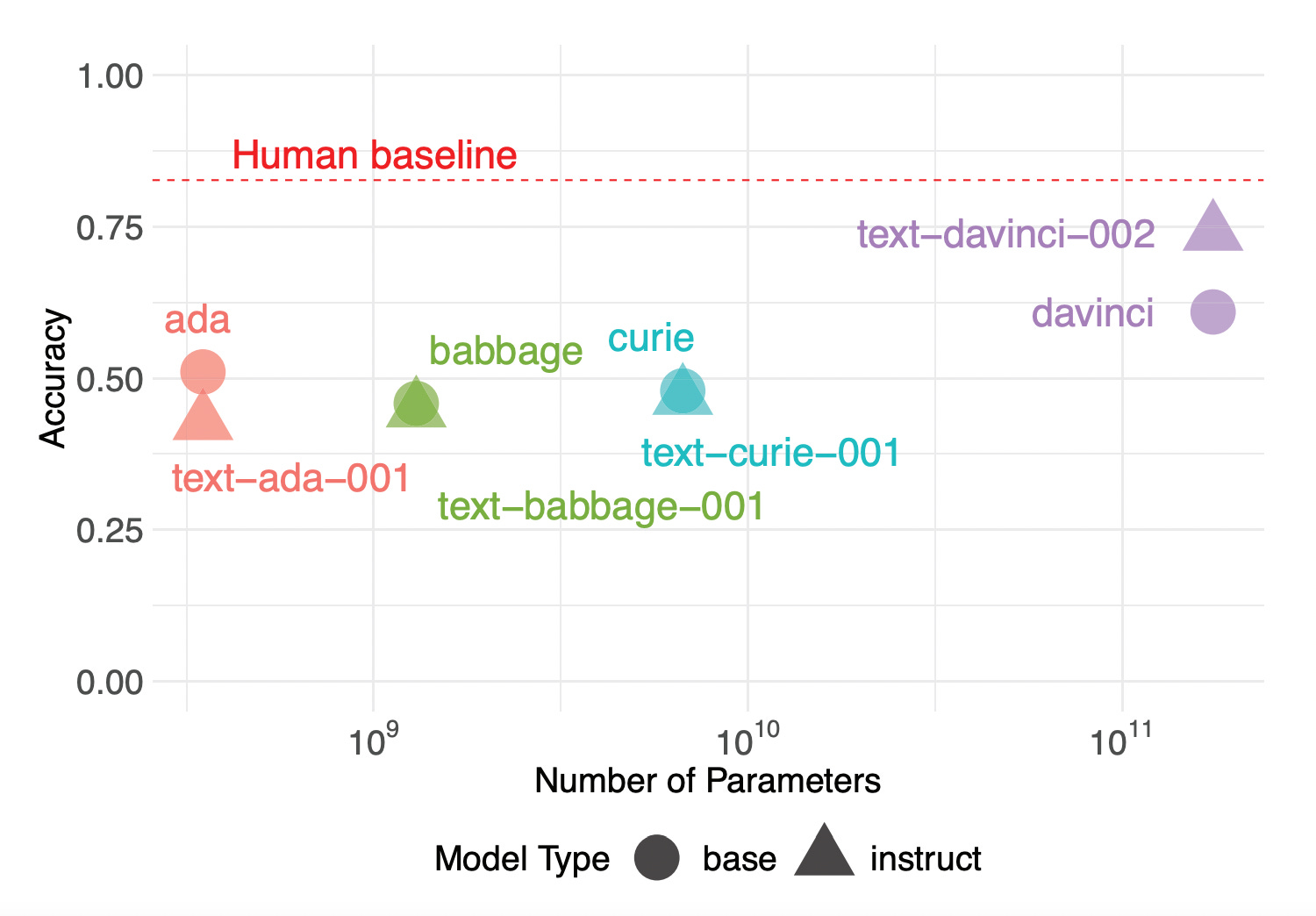
Among these 613 participants, about 82.7% of them answered correctly. Recall that GPT-3 attained about 74.5% accuracy. Thus, GPT-3 is better than chance, but not quite at human levels of performance.
In an exploratory analysis, we also looked at other, smaller models in the GPT-3 family, like “ada” and “babbage”; these models have fewer parameters, which is generally associated with worse performance—and indeed, they performed worse than text-davinci-002 (and davinci) across the board. This is more evidence in favor of the hypothesis that increasing model size tends to improve model performance.
A win for LLMs?
Does this mean LLMs have Theory of Mind or not?
On the one hand, at least one LLM is sensitive to a character’s belief states, and adjusts its predictions about that character’s behavior accordingly. On the other hand, this sensitivity is less than the human benchmark: on average, humans are more likely to adjust their predictions as a function of what a character believes than are LLMs.
Thus, in terms of representing false beliefs specifically, we think these results point to the idea that LLM abilities lie on a continuum with human mentalizing capacities. It’s a win for LLMs that, quite frankly, should surprise us. There’s no in principle reason to expect a system trained to predict which words co-occur with which other words to exhibit these sensitivities to more abstract properties like “belief”.
Broadening the lens: other measures of Theory of Mind
Representing false beliefs is only one component of Theory of Mind. Crucially, someone’s performance on the FBT may or may not predict their performance on the “Reading the mind in the eyes” task, in which subjects view pictures of a person’s eyes and must infer their emotional state—possibly because the FBT requires abilities other than Theory of Mind. This potential lack of convergent validity means it’s hard to make a broad inference about an LLM’s Theory of Mind abilities from a single measure or task.
To address this limitation, both of us (along with our collaborator, Benjamin Bergen) designed a more comprehensive assessment of Theory of Mind in LLMs, which we called EPITOME (Experimental Protocol Inventory for Theory of Mind Evaluation). We focused on six tasks, which, collectively, measure a diverse set of abilities including false belief representation (i.e., the FBT), emotional reasoning, non-literal communication, and pragmatic inference. We’re not going to describe each task in detail here, but a graphical summary is included below, which highlights an example passage from each task (along with the correct answer).
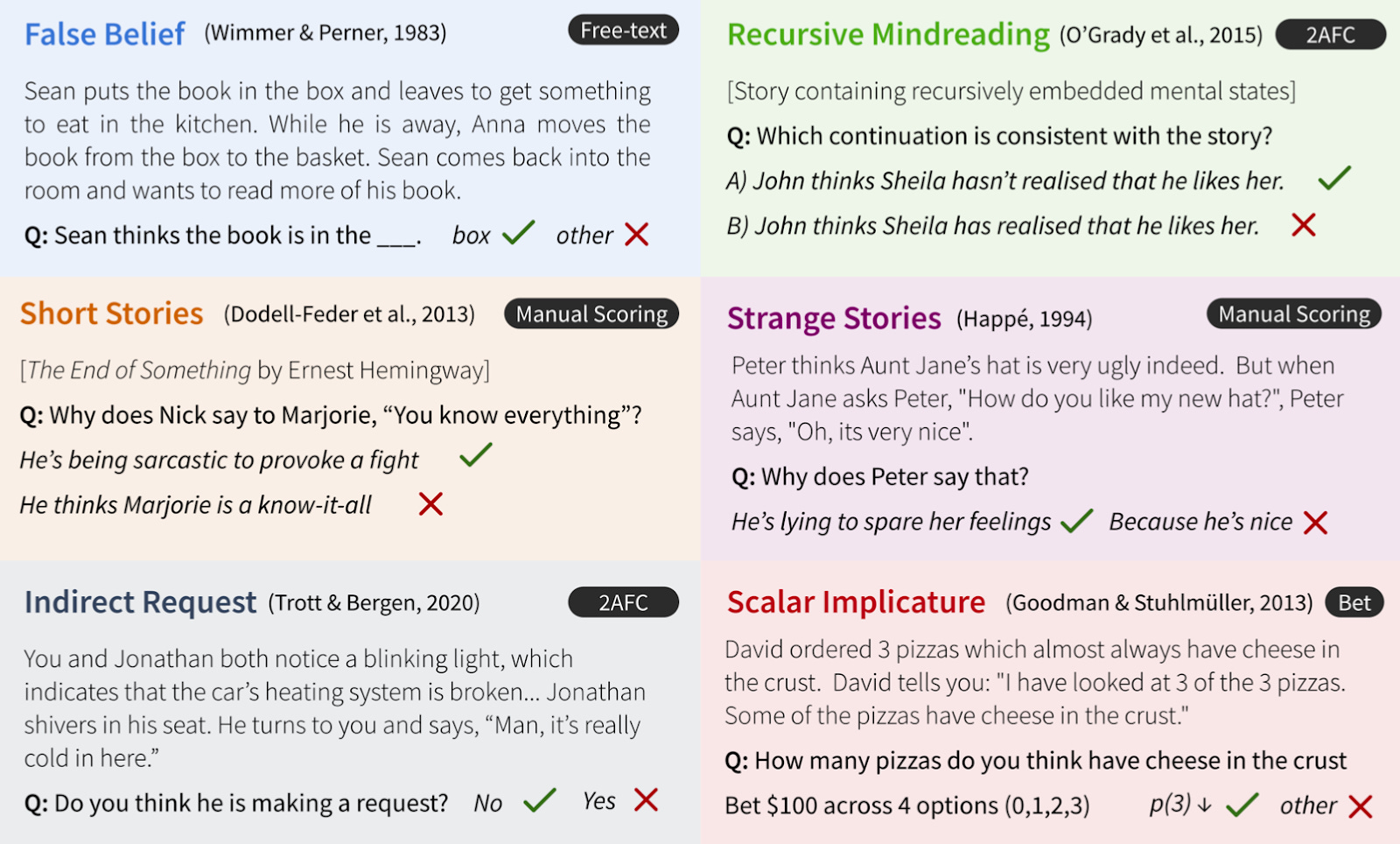
Some of these tasks (like the FBT) involve representing what a character knows, even when it’s different from what you (the subject) knows. Others (like the Recursive Mindreading task) involve keeping track of nested relationships between mental states—inspired by gossip chains—like “John thinks Sheila hasn’t realized that he likes her”. And still others (like the Indirect Request task) involve inferring what a person means by what they say (e.g., “It’s cold in here” could be a request to turn a heater), and focus on whether those pragmatic inferences vary as a function of what that person knows.
We measured LLM performance on each task, and again compared to a human benchmark. The results are depicted in the figure below. In each figure, GPT-3’s performance is represented by the red diamond; the violin plot represents the distribution of human accuracies (i.e., for each subject), and the dark gray circle represents the average human performance on that task.
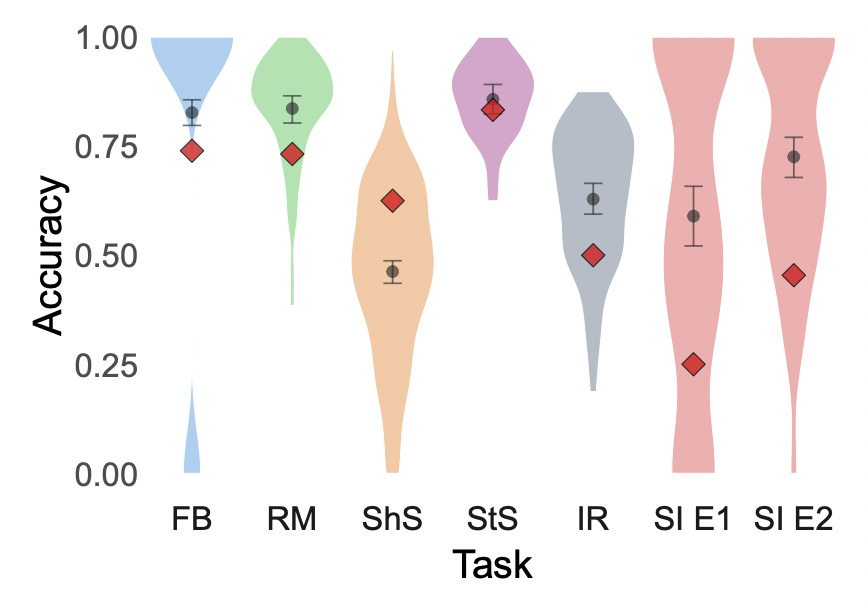
As you can see from the figure, LLM (and human) performance varied considerably across tasks. In most tasks, humans performed better than GPT-3. The two tasks that were the exception to this rule were the Short Stories Task (ShS) and the Strange Stories Task (StS); in both cases, subjects had to read a story, then answer questions about why characters behaved in certain ways. It’s interesting (though perhaps not surprising) that GPT-3 was most likely to out-perform humans on tasks that required these more elaborate explanations, as opposed to tasks often viewed as more “rote”, such as multiple choice.
At first, we weren’t really sure whether there was anything deeper to say about these results other than: “It’s complicated”. And that might still be the answer.
But it’s interesting to note that the four tasks on which GPT-3 performs substantially above chance—and sometimes even above human performance—involved reading passages and answering questions about what different characters know or believe. The two tasks on which GPT-3 performed quite poorly were the pragmatic inference tasks: the indirect requests (IR) task, as well as the two versions of the scalar implicature (SI) task. LLMs seem to perform well on pragmatic inference tasks in isolation, so there must be something particularly difficult about the combination of having to first infer what a character knows, then deploying that information downstream to determine what they mean by what they say. This is an argument one of us (Sean) first made a few years ago in a paper focusing on human mentalizing abilities specifically, and we think it might very well apply to LLMs too. And to speculate just a bit more: perhaps it’s even harder for LLMs than it is for humans, and that increased difficulty reflects some fundamental difference in our respective cognitive architectures. Perhaps humans are better at abstracting the “gist” of a passage and maintaining the relevant information in working memory; perhaps humans are better at combining (or “composing”) multiple cognitive operations in sequence or in tandem, like inferring what a person knows and then inferring what they mean.
But again: those comparisons are very much post-hoc (i.e., not pre-registered), so it could very well be noise. At the very least, it’s something to follow up on in future work.
Circling back: do machines mentalize?
There are at least three thorny issues to unpack here.
The first is empirical: if we take the results at face value, what do they say about whether and how well LLMs mentalize? In our view, these results—combined with other recent work—suggest that state-of-the-art LLMs exhibit evidence consistent with a mentalizing capacity, albeit one below the level of most neurotypical adult humans. There’s also a lot more work to be done delineating exactly which tasks LLMs excel at and whether subtle perturbations to each scenario disrupt their performance.
The second issue is conceptual, and comes back to the debate raised at the beginning: is Theory of Mind even a coherent construct in the first place? At least in humans, some would say “no”. We’re not really committed to a definitive answer one way or the other here. As we see it, there’s value in providing empirical data on a diverse range of tasks, as we did with EPITOME. If data from those tasks point in similar directions, then there might be epistemic and practical value in calling that constellation of abilities “Theory of Mind” or “mentalizing”. All scientific terms are abstractions anyway—the question is always whether the abstraction is instrumentally useful.
The final issue is interpretative: how does performance on a test designed to assess an ability relate to the underlying ability itself? A while back, one of us (Sean) argued that there are two distinct positions one might take on this issue. The duck test position holds that performance is really all that matters: if you walk like a duck and quack like a duck, then you’re a duck. Similarly, if you pass the FBT, then you can reason about false beliefs. In contrast, the axiomatic rejection position holds that LLMs are a priori incapable of certain abilities, potentially including Theory of Mind. If you hold this position, then the fact that LLMs pass the FBT serves primarily to invalidate the tests themselves—after all, if we’ve already decided an LLM doesn’t have Theory of Mind, then the fact that an LLM passes a Theory of Mind assessment suggests it’s not a very good assessment. Both these conclusions are pretty radical: either LLMs have what was once considered a uniquely human ability, or the most widely used measures of that ability are sufficiently flawed that a system without Theory of Mind can pass them.
It’s also worth noting that there’s also a third, more subtle, view, which we call the differential construct validity (DCV) view, that argues something like the FBT can be valid for humans but not LLMs. This third view relies on the claim that LLMs must be solving mentalizing tasks in a different way than humans, and thus the “same” performance doesn’t actually mean the same thing. That’s the impetus behind this recent article arguing that because LLMs are different than humans, we should stop testing them using tests of human psychology.
All three of these views merit serious consideration. But from our perspective, the axiomatic rejection view needs to be fleshed out in more detail; as it stands, it’s not clear how it yields a productive research direction. After all, at the end of the day, we need to be able to test our theories with empirical data—and it’s unclear how this view could be falsified. We’re both currently somewhere between the “duck test” and “DCV” view. Empirical results ought to be taken seriously, whichever way they point. They also demand a deeper, more mechanistic analysis: it’s possible that, as the DCV view argues, LLMs are doing something fundamentally different at the algorithmic level of analysis. But we still don’t know whether or not that’s true, in part because we still don’t really know how humans solve these tasks!
And therein lies the central problem inherent to many of the debates floating around LLM-related discourse right now: assertions are made in favor of or in opposition against the idea that LLMs have this or that human cognitive capacity, typically with reference to a property the speaker assumes is shared or distinct between LLMs and humans, without sufficient evidence about whether humans do indeed have that capacity and how it works under the hood.
 | A guest post by
|
Thank you for this, I have been avoiding LLMs since I have no use for them, but it is good to have a look at what is going on. But I have some reservations.
"In most tasks, humans performed better than GPT-3. The two tasks that were the exception to this rule were the Short Stories Task (ShS) and the Strange Stories Task (StS)"
- but actually the graphs suggest that GPT-3 was just below Human level for Strange Stories, apparently within the 95% limits, but not actually better : though indeed well above for Short Stories.
I would add that both from a literary criticism point of view and a linguistician's* understanding, both of these present problems given the paucity of information about the actual question. The Short Stories task appears particularly confused.
Reading the story leaves me again thinking that Hemingway is a slapdash, or perhaps heavy-handed writer, quite apart from my general lack of sympathy with his discourse topics. But that is not the issue here. I was concerned that Trott and Bergen (2018) and then Jones et al (2023) may have accepted too readily the work of Dodell-Feder et al (2013) - unfortunately I do not have access to the latter's supporting information detailing the actual questions: it is referred to but I cannot see a link to it; while Trott & Bergen's piece would cost me 45€ - pah. So what follows is mostly a naïve reaction to your essay, I'm afraid.
Overall the tale is unexceptional, discussing falling out of love - which can happen in a moment, like falling in love - and how to convey this with being too hurtful. And the contradictory state of mind of Nick is what leads to the self-contradictory remark, "I've taught you everything. You know you do. What don't you know, anyway?"
But "You know everything" is indeed essentially saying that Marjorie is a smarty-pants, a know-all ("know-it-all" is not in my lexicon). The suggestion that it is said to provoke a quarrel is a second order assessment and is not necessarily the right answer - Nick is trying to avoid emotion: so provoking a quarrel, while one way of ending the relationship, is not what he has set out to do. The remark is more likely to be an involuntary expression of frustration that Marjorie is too docile rather than a deliberate tactic.
Accordingly both answers could, in the abstract, be correct: but the one you choose as correct - that he is being sarcastic to provoke a fight - seems to me to be essentially wrong, in terms of the story. Would that change one's view of what LLMs can do ?
I should note that in Jones et al (2023), the question is different from your presentation, as a free text response was accepted. There the options include provoking a fight or unhappy and nervous and ignores the consequences or he is just nasty. The middle one scores 1 - neither correct, 2 nor wrong, 0 - which I still think is wrongly characterizing the situation. And the visual representation of the figures seems to include averages across many questions, not just the ones specific to theory of mind. I remain confused.
Later you say: " It’s interesting (though perhaps not surprising) that GPT-3 was most likely to out-perform humans on tasks that required these more elaborate explanations, as opposed to tasks often viewed as more “rote”, such as multiple choice." Personally I would a priori assume humans were better at attributing motive and so forth: but my lack of experience in this field is evident from my bafflement at this remark, among others, in Jones et al, " If language exposure is sufficient for human ToM, then the statistical information learned by LLMs could account for variability in human responses" which seems to be implying a cybernetic effect of LLMs on humans, just as their question 3, "Do LLMs fully explain human behaviour..." needs a lot of unpacking.
I would add that the "wrong" response to the Strange Story question seems to me perfectly acceptable, albeit as a second-order assessment. And your reference to a violin plot leaves me wondering which shape of violin you are using - I simply do not understand this.
Given the amount I would have to learn, together with what seem to me detailed confusion, I think I am probably right to stay away from this research, and I will not even try to join in the argument whether Theory of Mind exists or for what or whom. No thanks are necessary but again, thank you for this brief glimpse.
*someone who studies linguistics should be a "linguistician", as "linguist" is already taken: indeed most linguisticians are linguists: but many of them are far too slapdash with words.