

Ingredients, flavor networks, and the "essence" of cuisine
Trying to understand culinary diversity in terms of common ingredients and flavor networks.

There’s an old idea—dating back at least to Elisabeth Rozin’s 1973 The Flavor-Principle Cookbook1—that any given cuisine is associated with a handful of characteristic ingredients, which constitute that cuisine’s core flavors. For example, key ingredients in Southern Italian cuisine might include tomato, olive oil, sweet pepper, and oregano, while Chinese cuisine might rely more heavily on soy sauce, ginger, and rice wine.
Of course, Rozin isn’t claiming that these are the only ingredients in a cuisine, or that there’s no overlap across cuisines. She’s also not claiming that flavor is the only distinctive part of a cuisine: cuisines are also distinguished by their cooking techniques (e.g., using a wok or a barbecue pit) and by their social and historical context. Rather, the claim (as I understand it) is something like: It is possible to identify2 dishes from a given “cuisine”—a collection of food preparation techniques, typically specific to a culture or region—by relying on a relatively small number of commonly used, distinctive ingredients.
I first came across this idea years ago on a cooking forum, and I was intrigued but also wasn’t sure whether it actually bore out in practice. More recently, I’ve gotten interested in the study of food and culinary evolution from a Cognitive Science perspective, so I dove into the relevant empirical literature. In this post, I’ll summarize some of what I found.
Over-represented ingredients?
The first thing I wanted to know was whether any researchers had actually tried to formalize this claim.
What makes an ingredient “distinctive” to a cuisine? “Distinct” can’t just be commonly used, because that ingredient could be commonly used across all cuisines. Presumably, an ingredient is “distinctive” if it’s used commonly in a given cuisine and not used much (or at all) in other cuisines. This is the same logic behind text processing approaches like tf-idf, which help classify or sort documents by their distinctive words: words like “the” are very frequently used across lots of documents, so they don’t tell you much about the identity of the document in question—whereas words like “metabolism” might be used frequently in articles on nutrition or biology, but not in many other documents.
I found a few papers on this topic, each of which used roughly the same metric for calculating the distinctiveness of an ingredient to a cuisine (sometimes called over-representation or authenticity). Here’s how this idea was operationalized in a 2011 paper published in Scientific Reports, led by first-author Yong-Yeol Ahn:
First, collect a bunch of recipes with their ingredients listed. The authors used over 50K recipes from a variety of geographic regions, using three recipe websites.3
Divide those recipes into cuisines; this could be either fairly specific (e.g., Gujarati cuisine) or quite coarse geographic regions (e.g., North American).
For each ingredient in each cuisine, calculate that ingredient’s prevalence: the proportion of recipes for that cuisine in which that ingredient is used. For example, an ingredient used in every recipe would have a prevalence of 1 (100%).
Finally, calculate that ingredient’s prevalence in every other cuisine and subtract that value from the number calculated in (3). Their difference—the relative prevalence—is what the authors call authenticity.

Is this a perfect measure? Definitely not—no measure is. But intuitively, it seems “face valid”: it seems to capture something like what we mean when we say an ingredient is “distinctive” to a cuisine. Ingredients that are used in lots of recipes from one cuisine but not others will get high distinctiveness scores, while ingredients that are used in lots of recipes across all cuisines will get low distinctiveness scores.
The authors applied this measure to their coarse cuisine groupings (e.g., Western European vs. East Asian) and the results make intuitive sense: distinctive ingredients in “Western European recipes” include milk, vanilla, butter, and thyme—while distinctive ingredients in East Asian cuisines include soy sauce, ginger, and scallion. Interestingly, this analysis also allows the authors to figure out which coarse geographic regions share the most overlap in their most distinctive ingredients: perhaps unsurprisingly, North American and Western European cuisine have a lot in common (e.g., milk, wheat, butter), as do Southern European and Latin American cuisine (e.g., tomato, garlic, onion).
A finer-grained analysis
An immediate objection some readers might have to these results is the coarse level of analysis. What exactly is “North American” cuisine—or “East Asian”, for that matter?
A handful of other papers have taken a more fine-grained approach.
For example, this 2019 paper by Rudraksh Tuwani and others coded recipes according to their “region”; in some cases “region” appears to refer to countries (like France), and in other cases, multiple countries (like the Caribbean)—there were 25 of these regions total. The authors also considered a larger set of recipes (over 150K) sourced from more recipe websites.4 Finally, they applied roughly the same analysis as above to figure out which ingredients were most distinctive in each region.
To give you a sense of what they found, here are the most over-represented ingredients in a sample of the regions they considered:
China: soy sauce, sesame, ginger, corn, chicken.
France: butter, egg, vanilla, milk, cream.
Greece: olive, feta cheese, oregano, lemon juice, tomato.
Indian subcontinent: cayenne, turmeric, cumin, cilantro, ginger, garam masala.
Mexico: tortilla, cilantro, lime, cumin, tomato.
This seems mostly reasonable, though a few things stand out.
First, I was a bit surprised by the apparent prevalence of corn in recipes for Chinese food, but I guess baby corn is a relatively common stir-fry ingredient (and maize supposedly found its way from the New World to Asia during the Ming Dynasty). For that matter, is chicken really over-represented in Chinese cuisine? I also would’ve predicted that wine would be a more distinctive ingredient for French cuisine—the ingredients listed basically seem like pastry ingredients—but maybe that’s the result of French cooking techniques influencing other styles.
Another thing is that some of these ingredients feel more like the main part of a dish (e.g., chicken) than the key flavoring ingredients (e.g., soy sauce). And when we turn to the Indian subcontinent, some of these are individual spices (like cumin), while others are spice blends (like garam masala, which usually contains cumin).
This last issue points to an interesting difficulty in any data-driven analysis of recipes, which is that the notion of an “ingredient” is necessarily a question of abstraction. Is “garam masala” an ingredient or is it a set of ingredients? The answer, of course, is both: humans use abstractions where it is effective and efficient to do so. But it does raise challenges when your goal is counting the number of recipes in which a given ingredient is used. If you don’t count “garam masala” as an instance of cumin (and other spices), then you might be underestimating the prevalence of cumin in recipes. But most ingredients are compounds in some way—how granular should we get?
Further, as I noted above, ingredients contribute in different ways to the dish itself. In fact, this was part of Rozin’s original point. A “dish” consists of at least three components: the staple food (e.g., chicken), the techniques for processing and preparing the dish (e.g., how it’s cooked), and the flavorings (e.g., cumin and cayenne pepper; or soy sauce and ginger). But where does the boundary between staple food and flavoring lie?
A flavor database?
These questions have occurred to other researchers as well—motivating the creation of FlavorDB, a database mapping individual flavor molecules to common ingredients, spanning different categories (e.g., beverage, herb, nut, etc.). Here’s the description from the website:
FlavorDB comprises of 25595 flavor molecules representing an array of tastes and odors. Among these 2254 molecules are associated with 936 natural ingredients belonging to 34 categories.
This database is very cool, and the creators have made a handy interface for exploring the relationship between molecules, ingredients, and ingredient categories.
For example, the flavor network tool allows users to click on a given ingredient and see its similarity in flavor-space with other ingredients. Here’s the network for onion:

Alternatively, you can use the Flavor Pairing tool to see which ingredients have the most shared flavor molecules (and how many).
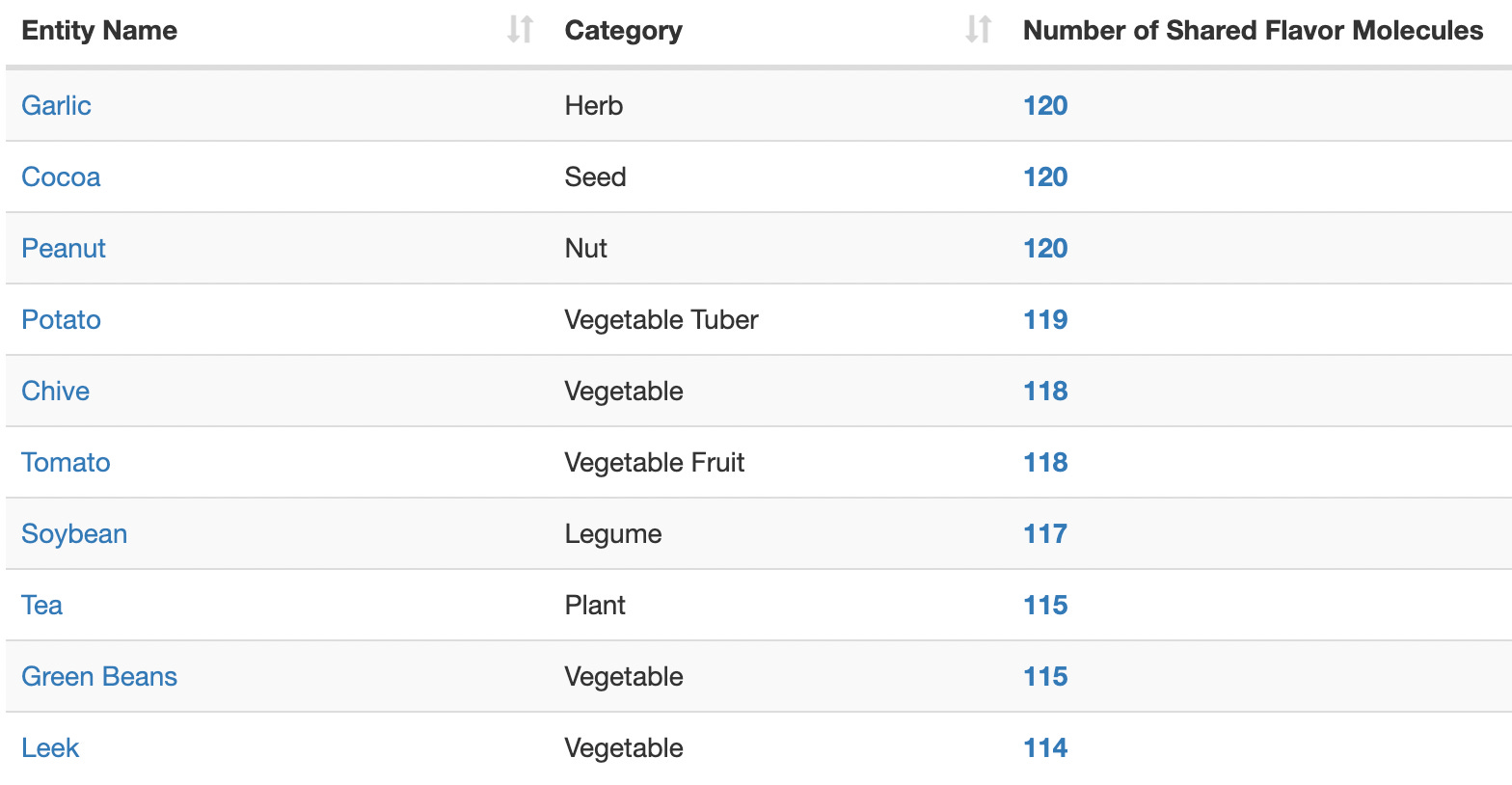
The issue of flavor pairing is actually a major research question within the study of cuisine—it’s the primary topic of that 2011 Ahn paper I referenced earlier. I’ll turn to that research literature in just a moment, but first I’d like to highlight another paper investigating distinctive ingredients.
Even more granularity
Distinguishing “French” and “Italian” cuisine—as well as “Thai” and “Chinese”—certainly provides a more granular lens than “Western European and “East Asian”. But even talking about specific countries or geographic regions obscures a huge amount of fascinating variation.
Consider India, for example: a country with hundreds of languages, diverse geography, and incredible variation in its cuisine. This 2015 paper by Anupam Jain and others applied the same distinctiveness analysis to recipes listed on tarladalal.com, a large repository of recipes for Indian cuisine. Focusing on eight regional cuisines (including Gujarati and Punjabi), the authors identified the most distinctive ingredients in each. According to this analysis, Gujarati cuisine was associated with (among other things) the use of asafetida, green bell pepper, and black mustard seed oil—while Punjabi cuisine was associated with (among other things) the use of garam masala, wheat, and onion.
I suspect a fine-grained analysis of other vast and varied geographic regions would reveal similar diversity. As food historian Fuchsia Dunlop has pointed out, Chinese cuisine is incredibly varied, even though many Americans have historically only been exposed to a variety of Cantonese cuisine. If you’re interested in that topic, I highly recommend this interview with Dunlop on Conversations with Tyler.
Is flavor pairing universal?
An old idea is that ingredients with shared flavors go well together. This is called flavor pairing. Flavor pairing has motivated the pairing of new recipes, such as the now-famous pairing of white chocolate and caviar at the Fat Duck restaurant. It’s also an interesting candidate for a culinary universal. That is, while cuisines obviously differ in which ingredients they use, maybe they’ve all converged on similar combinatory principles—namely, flavor pairing. But is this true?
One of the first major empirical studies on this topic was, in fact, that same 2011 Ahn paper I referenced earlier. The authors constructed a flavor network (like the one on FlavorDB) mapping each ingredient to every other ingredient, with the strength of the connection determined by the number of shared flavor compounds. Then, for each culinary region (e.g., North America, East Asia, etc.), the authors calculated the mean number of shared flavor compounds per recipe. If none of the ingredients in the recipe shared any compounds, this number would be zero—but the more compounds are shared, the higher that number. For each cuisine, the authors compared this statistic to a random baseline. This baseline controlled for the underlying frequency of different ingredients in a given cuisine, but randomly permuted which recipes they appeared in. This tells us roughly how much flavor pairing to expect by chance.
The authors found that some cuisines—like North American and Western European—showed clear evidence of flavor pairing. That is, ingredients in North American recipes tend to share more flavor compounds than you’d expect by chance. But other cuisines—like East Asian—actually had less flavor pairing than you’d expect by chance. And the other cuisines (Latin American and Southern European) were somewhere in between these extremes.
Altogether, then, these results suggest that the degree of flavor pairing varies across regional cuisines. Some cuisines use ingredients with similar flavors, while others appear to avoid them. Interestingly, these differences across cuisines were driven by a handful of ingredients in each case. When the authors removed the biggest contributors to flavor pairing in North American cuisine from their dataset (e.g., milk, butter, cream), the flavor pairing effect disappeared; when they did the same thing with the East Asian dataset (e.g., beef, ginger, cayenne), the avoidance of flavor pairing also disappeared. In other words, the most prevalent ingredients in these cuisines are primarily responsible for the observed tendencies towards or against flavor pairing.
Other, more recent work is consistent with the idea that some cuisines actually show “negative food pairing”. This 2015 paper by Anupam Jain and others, for example, found a tendency to avoid ingredients with similar flavor compounds across multiple regional varieties of Indian cuisine. Further, this effect was once again driven by a handful of key ingredients, namely spices like cumin or cayenne:
We analyzed the reason behind this characteristic pattern and found that spices, individually and as a category, play a crucial role in rendering the negative food pairing… (pg. 11).
Finally, a 2017 paper by Tiago Simas and others adopted a slightly different perspective, asking not only about flavor pairing but what they call flavor bridging. The premise behind “flavor bridging” is that while two ingredients may not share any flavor compounds directly, they may both share flavor compounds with a third food—which can therefore be seen as a “bridge” between those initial two ingredients. By way of illustration, the authors write:
[Flavor bridging] assumes that if two ingredients do not share a strong molecular or empirical affinity, they may become affine through a chain of pairwise affinities. That is, apricot and whiskey gum may not be affine, but if we join (or bridge) them with tomato they may become affine—assuming that tomato is affine with apricot and whiskey gum, thus creating a chain of affinities.
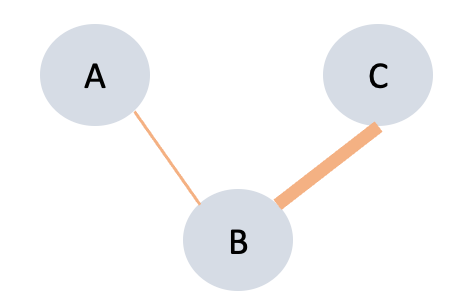
Concretely, this can be measured using a flavor network—much like the one I described above. For each pair of ingredients, the authors calculate the shortest paths between those ingredients in the network. They then calculate the average strength (i.e., flavor overlap) of the connections in those paths. In the example below, the shortest path path between “A” and “C” runs through “B”; we would thus calculate the average of the connection strength between “A —> B” and the connection strength between “B —> C”.
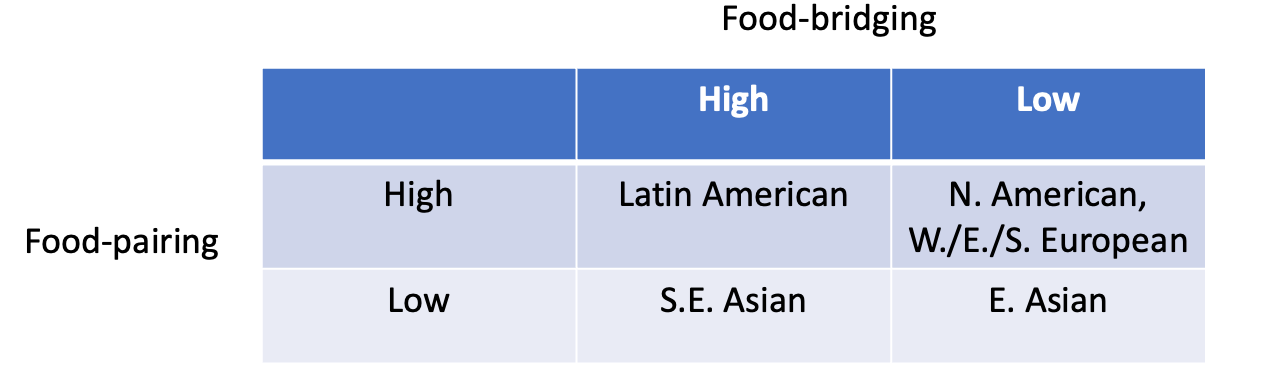
As with that 2011 Ahn paper on flavor pairing, the authors considered seven coarse-grained geographic regions as their “cuisines” (e.g., Southeast Asian, Latin American, etc.). They then calculated the average degree of both food/flavor pairing and food/flavor bridging in each cuisine.
Like Ahn and others found, some cuisines (like North American or Western European) do a lot of food-pairing, and others (like East Asian) do less. But they also found a somewhat orthogonal split when it came to food-bridging. Some cuisines were high in both food-bridging and food-pairing, others were low in both, and still others were high on one and low on the other. Crucially, because food-bridging is somewhat independent from food-pairing—at least as operationalized here—it suggests that it might be useful to study cuisines from both perspectives, i.e., that both principles might operate in the use and integration of ingredients.
Is there an “essence” of cuisine?
I started out this post by asking whether cuisines can be usefully characterized in terms of their most distinctive ingredients or flavors. This idea dates back at least to Elisabeth Rozin’s The Flavor-Principle Cookbook.
Empirically, we can identify distinctive ingredients for each cuisine by asking which ones are most over-represented in a given cuisine. A procedure for doing this—reminiscent of tf-idf—yields results that are, for the most part, pretty reasonable and also aligned with Rozin’s original intuitions. Chinese cuisine’s distinctive ingredients include things like soy sauce, sesame, and ginger, while Greek cuisine’s distinctive ingredients include olives, feta cheese, and lemon juice. This is a nice proof-of-concept that the technique “works”, to an approximate extent. Further, cuisines differ in whether they tend to use ingredients with similar flavors (flavor pairing) or whether they avoid this principle.
Of course, these results depend on the quality and representativeness of the data. I’ve already written about how important representativeness is before, e.g., for training large language models, and this principle applies to any empirical work. Are the recipes available in online sites representative of the kinds of foods that people generally eat in a given cuisine? I can’t really speak to this question—I’m sure some foods are over-represented and others are under-represented. One fruitful approach could be to complement this work with a more qualitative study or even a survey, soliciting input from actual people about what they tend to make. This would give a sense for what dishes people actually make (and how often), as well as how that relates to variables like social class or location. These results could then be compared to the results produced using online recipe aggregators.
For me personally, one question I’m really fascinated by is change over time. How has the prevalence of different ingredients in a cuisine shifted over the centuries, and how does this relate to “on-the-ground” factors such as climate, availability, and trade? (For example, chili peppers originated in the Americas, and were only brought to Europe and Asia somewhere between the 14th-16th centuries.) This might be very difficult to address using only online recipe sites, but maybe researchers could converge on an answer using a combination of historical cookbooks (or literature), evidence about trade routes, evidence of what plants and animals were available where, and theoretical models of culinary evolution.
This relates to another question, which Pam came up with, which is what exactly leads to the apparent divergence in flavor pairing researchers have observed. The results suggest the differences are driven by a handful of prevalent ingredients. But what drove the use of those particular ingredients? Was it geographic availability, trade, or something more intentional (and intangible)? Another way of putting this is: are differences in flavor pairing due primarily to contingent, relatively exogenous factors (like which ingredients were historically available in a region), or are there factors endogenous to a cuisine itself that act as “selection pressures” for or against the use of particular ingredients in concert with other ingredients?
These are big questions, to be sure, and they’ll require interdisciplinary answers—which, as a cognitive scientist, is part of what appeals to me so much about this topic.
Thanks to Pam Rivière for reading and editing this article.
The idea of a “cookbook” or even a dietary manual urging the use of particular ingredients (e.g., for health, character, etc.) is quite old. For example, this category might include Proper Habits of Food and Drink (14th-century dietary manual by Hu Sihui, a court nutritionist during the Yuan Dynasty) and Avicenna’s The Canon of Medicine (a medical encyclopedia that includes discussion of proper nutrition). But as far as I can tell, Rozin was one of the first to apply this principle to actually categorizing a variety of world cuisines by their ingredients.
Or evoke, as when cooking.
Two of these were American websites and one was Korean, though the recipes spanned a much larger variety of cuisines.
In case you were wondering, the authors also mapped each ingredient in each recipe to a common database of ingredient names.