Language models and the intentional stance
When are words like "belief" and "desire" useful, and when do we risk mistaking the map for the territory?

Humans often grapple with new concepts by way of metaphor or analogy. These days, many people (including myself) are struggling with the question of how to properly conceive of systems like large language models (LLMs). As I’ve written before (and as others have pointed out as well), there is no shortage of metaphors for these systems: they’ve been likened to “stochastic parrots”, “blurry JPEGs of the web”, “role-players”, an “alien species”, or even “troublesome genies”1.
LLMs, of course, are not literally any of these things. The point of a metaphor is to grant some kind of conceptual purchase on a slippery topic—typically by foregrounding certain features of the thing you’re talking about and backgrounding others. In a sense, each metaphor is a kind of rudimentary model of the phenomenon. And as the oft-quoted saying goes: “All models are wrong, but some are useful”. The question, then, is not necessarily whether any given mental model of LLMs is “correct”, but what that model does for us conceptually and communicatively: which thoughts does it make more or less expressible—or even more or less thinkable in the first place?
My focus in this post is the mental model of an LLM as the kind of thing that has beliefs, desires, or even feelings. We might speak of an LLM “believing X”, “wanting Y”, or “feeling Z”. This broad mental model includes the common tendency to attribute human qualities to non-human entities (also called anthropomorphism), which many readers are likely already familiar with.2 This inclination feels particularly natural when it comes to LLMs, given our association between human cognition and the use of language, and also given the fact that user-facing systems (like ChatGPT) are often engineered3 to be conversational or even “supportive”.4
When, if ever, is this mental model useful? And when might it be misleading?
I think these are crucial questions to contend with. First, they matter for discussions of AI safety. I, like many, think it is important to build policies and systems that avoid harms relating to AI. But one’s preferred solution-space (and also conception of the harms themselves) plausibly depends on whether AI systems are construed in terms of having desires or goals. Second, they matter for the scientific study of LLMs. As I’ve argued before, the way we go about studying LLMs depends on what “kind of thing” we think an LLM is—or at least, what kind of properties we find instrumentally useful to ascribe to it in the service of understanding and predicting its behavior. And third, they relate to other ongoing debates and discussions, such as increased emotional dependence on social AI systems5 and even the notion of “AI welfare”.
This post has the following structure. In Part I, I briefly introduce and defend the notion of the “intentional stance” as an epistemological (though not necessarily metaphysical) approach, making reference to both Daniel Dennett’s “Real Patterns” and a recent 2025 paper by Simon Goldstein and Harvey Lederman. In Part II, I discuss potential epistemological dangers associated with anthropomorphism, particularly when it comes to accurately diagnosing and addressing AI-related risks. And in Part III, I make the case for prioritizing causal-mechanistic accounts of LLM behavior, while nonetheless allowing for the provisional adoption of the intentional stance should those accounts be deemed insufficiently tractable.
Part I: In defense of the intentional stance
One can explain the same thing in multiple ways. Often these explanations vary in terms of their level of abstraction. For instance, one could describe the behavior of a gas in terms of each individual molecule or in terms of coarser, macroscopic properties (like temperature or pressure). Similarly, one can describe the motion of an object in quantum terms or using the language of classical mechanics. These levels of abstraction have trade-offs: more granular, microscopic explanations might be more accurate—and perhaps more “real”, depending on one’s metaphysics—but coarser-grained explanations might be more comprehensible, easier to work with, and nearly as accurate.6
This is the heart of the argument for the intentional stance. The philosopher Daniel Dennett suggested that we can explain phenomena from at least three distinct levels or “stances”, which vary in granularity, accuracy, and abstraction. The physical stance focuses on concepts from physics and chemistry; at this level, we are all simply objects in motion. The design (or “teleological”) stance is most akin to engineering or biological explanations, which emphasize the function served by a particular artifact, organ, or action. And the intentional stance (or “folk psychology”), in turn, is the level of “agents”, which have things like “beliefs”, “desires”, or “goals”.
Dennett’s argument is that in many cases—like explaining or predicting the behavior of other humans—something like the intentional stance is actually one of the most useful epistemic stances one can adopt. For instance, if you’re talking with a friend about a personal conflict they’re having, it’s probably most natural and useful to think about their beliefs (what do they think about the situation?), their feelings (are they upset, and why?), and their desires (what do they want to happen?).7
In Real patterns, Dennett suggests that something like the intentional stance is central to the general human project of interaction and coordination; and further, that its success depends on the underlying behavior conforming to a sufficiently regular pattern:
Without its predictive power, we could have no interpersonal projects or relations at all; human activity would be just so much Brownian motion; we would be baffling ciphers to each other and to ourselves—we could not even conceptualize our own flailings. (pg. 29)
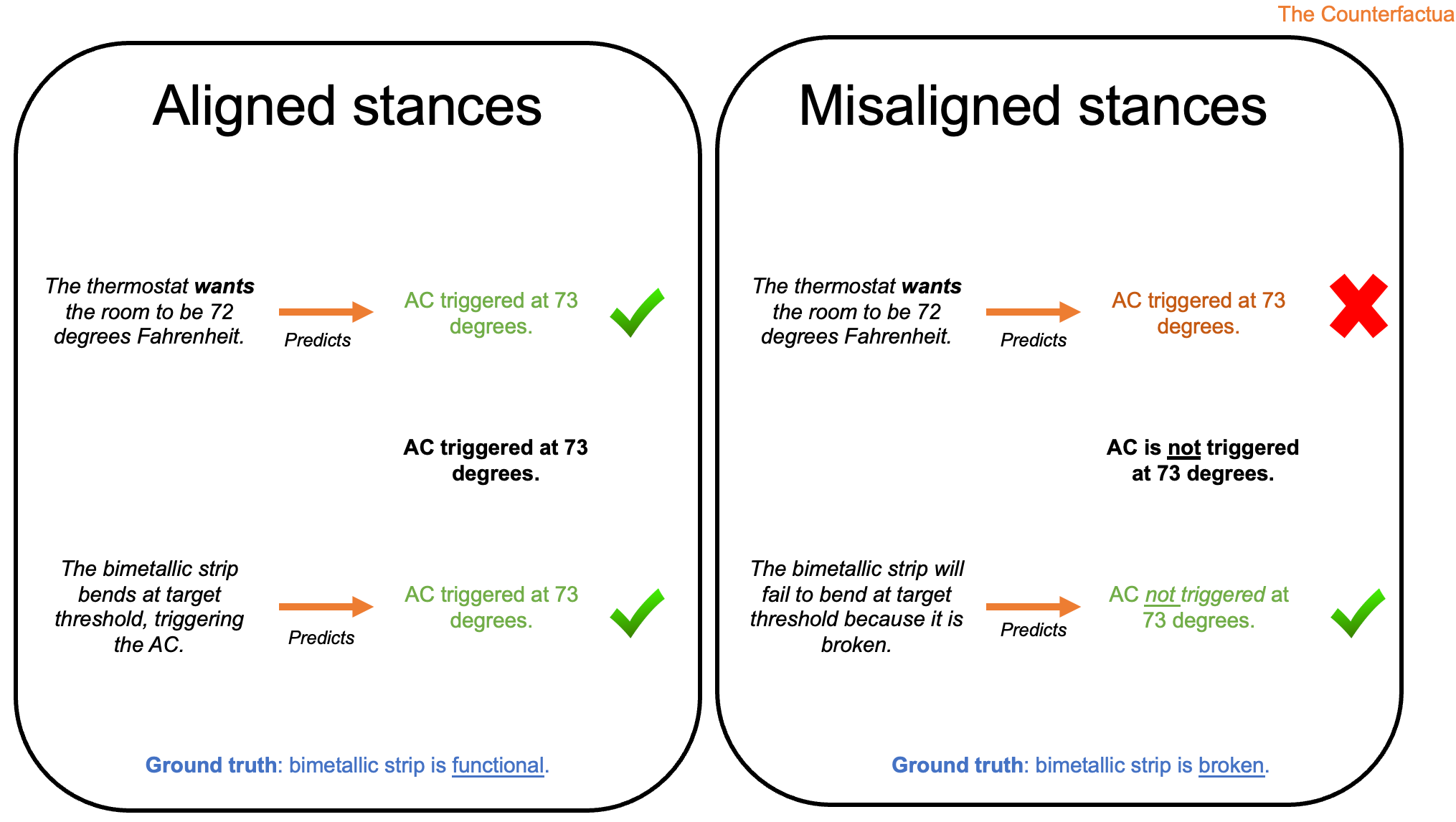
At the same time, as Dennett himself argued, the intentional stance is not always appropriate. We could explain the “behavior” of a rock falling from a cliff as having surrendered to the call of the void, but there’s an easier and more accurate alternative available: a careless hiker scuffed the rock with his boot, exerting sufficient force for it to fall. Similarly, we could describe a thermostat as having “beliefs” about the temperature of the room and “desires” to make it colder or hotter, but again, there’s a better and more accurate mechanistic alternative on offer: a thermostat works by measuring temperature through the expansion or contraction of a bimetallic strip, which in turn triggers a cooling or heater system.
When, then, is it appropriate to attribute beliefs and desires on the basis of observed behavior?
As the examples above suggest, much depends on the quality of the alternative theories available. A recent paper by philosophers Simon Goldstein and Harvey Lederman suggests that we should compare the quality of competing theories in terms of three objective criteria. First, their predictive accuracy: to what extent are their predictions true? Second, their predictive power: how many cases are there in which the theory makes concrete predictions, and how precise are those predictions? And third, their tractability: how easy is it to generate predictions from the theory?8
Explaining someone’s behavior in terms of each individual atom in their body—and, presumably, the atoms all around them—might be very accurate. But a folk psychological account of their beliefs and desires is much more tractable, and might be nearly as accurate. In this case, it’s defensible, and perhaps even advisable, to adopt the intentional stance; even if one is not committed to the reality of those beliefs and desires, it is helpful to act as if they are real.
The question is whether this is also true when explaining the behavior of large language models. Should we speak of LLMs “believing” certain things or “wanting” certain outcomes? For me, one of the most helpful parts of Goldstein’s and Lederman’s paper is that it proposes a concrete set of criteria for answering this question: it makes sense to attribute beliefs (and desires, etc.) when this is the best explanation on offer.
It might help to start by considering a scenario where attributing beliefs does not make sense. In a previous paper (which I also recommend!), Harvey Lederman and his co-author Kyle Mahowald used the example of ELIZA, the famous chatbot developed by Joseph Weizenbaum. ELIZA consisted of a relatively simple set of rules and templates for responding to messages—it was, essentially, a lookup table—but many human users walked away convinced they’d been speaking with a real human therapist. Some of those humans might find it natural to describe ELIZA’s behavior in terms of beliefs and desires. Does that mean we should adopt the intentional stance? Lederman and Mahowald argue that the answer is no, precisely because there’s a better theory on offer:9
Similarly, if ELIZA passed the Turing Test in an hour-long conversation with a person, the person might claim that the best explanation of their interlocutor’s behavior was that it has beliefs, desires, and intentions. But they would be wrong. An explanation of ELIZA’s behavior in terms of its being a lookup table is more accurate and powerful (predicting various mistakes and failures) than the hypothesis that ELIZA has beliefs, desires, and intentions. Interpretationists will say that, notwithstanding what the person thought, ELIZA’s behavior is not well-explained by the hypothesis that it has attitudes, and, thus, conclude that ELIZA does not have them. (pg. 1096)
In this way, ELIZA resembles the thermostat example from earlier. One could invoke beliefs and desires, but to what end? (And, one wonders, at what cost?) There’s a more accurate account that’s just as easy to understand and doesn’t break down outside a narrow range of circumstances.
What about the case of modern LLMs? Here, the authors focus primarily on state-of-the-art system architectures (or “LLM-equipped software tools”) like ChatGPT or Claude. These systems are trained not only to predict subsequent tokens from large web corpora, but undergo extensive post-training, including reinforcement learning from human feedback and, in some cases, reinforcement learning with verifiable rewards. They’re also given access to external tools like a “scratchpad”, Google search, or even a Python shell. Finally, systems like ChatGPT or Claude are typically initialized with a lengthy “system prompt” providing detailed instructions about how the system should behave. (In the case of Claude, this prompt was called its “constitution”, and originally instructed Claude to be “helpful, harmless, and honest”.10)
I mention all this to make the point that these LLMs are a very different beast than, say, GPT-2.11 This is reflected in their behavior: under most conditions, systems like ChatGPT or Claude seem to have an orientation towards answering questions and helping their interlocutors. (Indeed, their eagerness to help can sometimes be exhausting!) As others have argued, there’s a case to be made that describing these systems as “fancy auto-complete” can be misleading—despite the fact that on a mechanical level, you could describe these systems as generating text by repeatedly sampling from probability distributions over subsequent tokens.
Thus, if we grant—provisionally, for the sake of discussion—that it might be useful to attribute “beliefs” or “goals” to these systems, which beliefs or goals should we attribute? Goldstein and Lederman consider various hypotheses here, from the word-desire hypothesis (LLMs “want” to predict the next word) to the HHH hypothesis (LLMs “want” to be helpful, harmless, and honest). In each case, we can apply the criteria outlined above—accuracy, predictive power, and tractability—to evaluate the strength of a given hypothesis.
I’ll return to these competing accounts in Part III, but first, I want to discuss what I see as the potential epistemic risks of adopting the intentional stance.
Part II: Misleading maps
Of course, just because you can attribute beliefs or desires to a system doesn’t mean you should. As Dennett argued (and as Goldstein and Lederman point out), there are many cases where the intentional stance is strictly a worse theory of a system’s behavior than, say, the physical stance. This is clearest in the thermostat example. As Goldstein and Lederman write:
Many thermostats, for example, measure temperature using the curve of a “bimetallic strip”, two pieces of connected metal that expand at different rates when heated. There are simple laws connecting the initial temperature of the room to the bend in the metal, and connecting the bend to an air-conditioner that changes the temperature in the room. These simple laws offer an alternative explanation of what the thermostat does that outperforms psychological explanations of its behavior along our three dimensions…For example, imagine that the connection between the strip angle and the air conditioner is noisy, so that the temperature does not always adjust in the direction ’desired’ by the thermostat. In that case, the psychological explanation of the thermostat will make less accurate predictions than the physical explanation about how the system behaves. (pg. 6)
You could even make a similar argument about the design stance. A mercury thermometer, for instance, is designed to measure temperature; we “read off” information about the temperature as a function of the mercury’s height in the bulb. Yet there are circumstances under which a mercury thermometer fails to accurately assess the temperature—specifically, for temperatures below the freezing point of mercury, or for temperatures above the boiling point. That obviously doesn’t mean mercury thermometers are invalid; they’re valid, and very useful, under many conditions in which we need them! But thinking only about what mercury thermometers are designed to do (measure temperature) may mislead us about their behavior in certain situations, whereas thinking about how mercury thermometers work on a physical level (the mercury expands or contracts depending on the temperature) likely helps us make more accurate predictions.
We can draw a general lesson here. More abstract levels of explanation are extremely useful, and sufficiently accurate, when the phenomena they’re characterizing bear some consistent, structural relationship to the underlying physical laws producing those phenomena. However, they break down when that relationship no longer holds. We might think of these as “in-distribution” or “out-of-distribution” with respect to our mental model.
These out-of-distribution cases correspond to what in my view, many (though not all!) cases of “misalignment” actually boil down to. By “misalignment” here, I mean there’s a mismatch between our mental model of a system and the “true” causal processes responsible for its behavior. This mismatch ultimately leads to behavior we don’t expect because our expectations were miscalibrated. For example, we might construct an accurate explanatory model (or “map”) of the system in some evaluation scenario, which suddenly breaks down in other scenarios because we failed to account for some crucial variable. We might also call this a limitation in our mental model’s regime of applicability.
How does all this relate to the intentional stance?
It boils down to whether the intentional stance provides a sufficiently accurate map to allow us to make predictions about or even interventions in an LLM’s behavior. There is certainly a simplifying appeal to attributing beliefs and desires to systems—it’s annoying, in casual conversation, to feel one must air-quote every use of the word “understand” or “think” in relation to an LLM. And it might even be the best account! But I worry, in a way I admittedly find difficult to articulate, that it might also lead us astray when we think about building safe AI systems.
It might help to focus on a concrete example. Recently, computer scientist (and Nobel Prizer winner) Geoff Hinton suggested that avoiding catastrophic risk from superintelligent AI systems might depend on imbuing them with a “maternal instinct”. Hinton’s logic is that a superintelligent AI (defined as something smarter than the smartest humans) will, presumably, be able to outsmart many of the constraints or safeguards we place on it. Why would such a superintelligent, capable system not manipulate or take advantage of humans to achieve its own goals? Hinton points out that the clearest counterexample is a mother taking care of their child. A child is utterly dependent, but because a mother—or indeed, any good caregiver—has an orientation towards nurturing the child, the dependence actually functions as a kind of constraint. What we need, then, is a kind of superintelligent AI “parent” on which we depend.
Let’s aside, for now, whether this is an appealing scenario we should aim for as a society, and focus instead on the metaphors at play. Hinton’s quoted as follows:
“They have been focusing on making these things more intelligent. But intelligence is just one part of a being. We need to make them have empathy towards us. And we don’t know how to do that yet. But evolution managed and we should be able to do it too.”
In many ways, I agree with what Hinton is saying here, though I might put it another way: instead of just focusing on improving the “raw capabilities” of systems, we need to also do more work to make sure they are safe to deploy and that the contexts and consequences of their deployment are broadly aligned with human values. I think this for a variety of reasons, including the fact that there’s so much epistemological murkiness about how to measure capabilities in the first place. (There are, of course, further questions about whose values we mean by this, but that’s a separate topic.)
Hinton’s metaphor explicitly casts this as a contrast between making systems more intelligent and imbuing them with “maternal empathy”. My claim here is not that this metaphor is definitely wrong or misguided; it might even be the most useful metaphor to use! My concern, rather, is that it might be misleading in ways that are hard to understand or predict ahead of time—and my intuition is that we might get more traction on predicting risks if we think concretely about the causal mechanisms responsible for a system’s behavior, in the same way that we’ll be better at predicting a thermostat’s behavior if we understand how it actually works.
I worry, too, that adopting the intentional stance might have unintended epistemic consequences given the way that conceptual paradigms work. That is, it’s not hard for me to picture a scenario in which people—begrudgingly or not—adopt the intentional stance to explain a system’s behavior in a particular scenario, which subsequently encourages them to adopt the intentional stance in future scenarios; even if, in some counterfactual world in which the researchers hadn’t originally adopted the intentional stance, they would’ve sought (and been satisfied with) a more mechanical explanation first instead. We might think of this as a kind of epistemic path-dependence: adopting the intentional stance might make us more likely to do it again, including in situations where it’s inappropriate.
Another, related risk would be something like overgeneralizing which mental states they attribute to a system. For instance, perhaps we identify a scenario in which it is epistemically justifiable (as per Goldstein & Lederman’s criteria) to attribute certain beliefs or desires, but not necessarily a feeling like “fear”. But having already attributed desires, we are inclined to attribute other mental states as well (like “fear”), and this leads us to incorrect conclusions about the best way to train or deploy models.
Part III: Cause and effect
When I think of misalignment risks from current AI systems, I think primarily of ways in which our instructions, intended to produce a particular outcome, lead to some outcome other than what we intended.12 Importantly, this can happen in the absence of beliefs or competing desires: if we’re in search of a metaphor, then, the mythical golem might feel more appropriate than, say, a “cunning demon” intent on misinterpreting our instructions.
To cite a relatively harmless but revealing example: in his latest post, Steve Newman described the case of a person whose AI “agent” mistakenly deleted many of their emails. They’d instructed the system to check in before taking any actions, but because the inbox was so large, that part of the instructions got lost in the prompt compaction process. Notably, this didn’t occur when they were testing the system on a smaller, “toy” inbox. That is: their expectations were miscalibrated. The specific reason for this miscalibration is that their test environment did not account for a specific variable present in the actual application, i.e., the number and length of emails. Because LLMs have limited context windows, an overly long prompt can be consolidated or “compacted” (i.e., trimmed of unnecessary or redundant tokens); in this case, the compaction process appears to have removed a crucial part of the instructions.13
We could describe this error in terms of Claude’s mistaken beliefs, or even in terms of some misaligned goal, but it’s not clear what we gain from this. The alternative account I described above—the one that feels closest to what actually happened—relies on a more mechanical understanding of how Claude works.
A reader might make two reasonable objections here. First, my “mechanical” account above still involves abstractions; we’re speaking roughly at the design level, not in terms of how Claude’s internal mechanisms actually give rise to subsequent token predictions. Doesn’t that show that explanatory abstractions are useful? And second, as I pointed out, this is a relatively low-stakes example of current AI systems failing in a particularly transparent way. Might not the “cunning demon” be a more appropriate metaphor for future, superintelligent systems—or even the systems we have?
I’ll start with the first objection. Indeed, abstractions are useful: I’m certainly not denying that, and I think Dennett is exactly right that the intentional stance is, in many cases, the most helpful perspective. But the critical question is always what we gain from the abstraction. Using Goldstein and Lederman’s criteria, I think the typical case for the intentional stance is that you gain tractability, possibly at the expense of some accuracy. But it’s not clear to me that the “design-level” account above (Claude failed because of errors in prompt compaction) is any less tractable than some hypothetical “intentional-level” account (Claude failed because it believed the user didn’t need it to check in before deleting emails); moreover, the design-level account feels (to me at least) like a more accurate description of the sequence of events leading to the failure. (I’d be remiss here if I didn’t mention my friend and former lab-mate Sam Taylor’s work on strategic deception here, which I think is a great example of taking a putatively intentional-level construct like “deception” and addressing it from what I see as a causal perspective.)
With that said, I also take seriously the other half of this objection, which is that one could, in principle, take an even lower-level stance. The distributed architecture we call Claude, for example, presumably consists of at least: some system prompt, an extensively pre-trained and post-trained LLM, some set of tools available to the LLM (e.g., a Python shell, a web search function, etc.), and perhaps a front-end interface for filtering or identifying harmful requests. We can assume that inputs to that system (along with the system prompt) are tokenized and presented to the LLM, which undergoes a forward pass to produce a probability distribution over subsequent tokens. Depending on the nature of the computations within that pass, Claude’s next tokens might be presented to the user, or they might be on a “scratchpad”; alternatively, they might even be API calls to an external application. These generated tokens are then incorporated into the context window for subsequent forward passes, and so on—until, at some point, this process predicts that the message should end.
Could we produce an account of Claude’s failures that relies on these explanatory constructs and perhaps even makes reference to specific, identifiable internal mechanisms (e.g., dedicated “circuits” for copying previous tokens)? I’d like to think so. But I’m also aware of the fact that this might simply be intractable: maybe the best we can achieve is a bunch of locally coherent theories, some of which invoke low-level mechanisms and others which don’t. The question—which I don’t know how to answer—is whether some of those theories should involve beliefs and desires.
That brings me to the second objection. Perhaps certain alignment failures can be described in mechanical terms, but others cannot—and perhaps mechanical accounts will only become less tractable as models become increasingly complex and intertwined with various applications. At this point, maybe speaking about LLMs in terms of beliefs and desires will be all but unavoidable if we’re to gain any traction on predicting their behavior.
And my response is: maybe! As I wrote earlier, my case here is not that the intentional stance is definitely wrong in all circumstances. But my position, which readers may or may not find convincing, is a meta-scientific one: it’s that we should try, wherever possible, to prioritize causal explanations before reaching for words like “belief” or “desire” when explaining what it is that LLMs are doing in a given situation. This position is, in some ways, an optimistic one—that we can understand LLM behavior at the level of causal mechanism. This optimism might be misplaced, in which case the argument for the intentional stance might come from a place of epistemic pessimism; but I don’t think it’s time to throw in the towel yet.
Epilogue
In case it wasn’t clear from the rest of this article, I’m deeply ambivalent on this topic. I have a strong intuition about the epistemic dangers associated with adopting certain approaches, but I’m not sure how convincing my articulation of those dangers really is, and I’m aware that other people are capable of marshaling persuasive arguments in opposition to them. Beyond the arguments I’ve cited in this article, I’d like to point readers to a really interesting post (“the void”) by nostalgebraist, which tries to answer this question:
When you talk to ChatGPT, who or what are you talking to?
There’s a lot written out there about LLMs and consciousness, but I found this article one of the most compelling in terms of presenting an account of what it might be like, if it is like anything, to be an LLM. I recommend it even if I don’t share all the intuitions and remain relatively convinced that a causal-mechanistic perspective is the right way to understand LLMs.
The other point I’d like to make in closing is that all of this, to me, highlights just how ontologically out-of-depth we are when we’re talking about LLMs. We’re flailing about in the dark, trying to understand these strange artifacts we’ve created in the image of our own imprints. We might need fundamentally different explanatory frameworks and constructs than the ones we find ourselves reaching for. I’m still bullish on what I call “LLM-ology” as a discipline, in part because I think Cognitive Science is particularly well-suited to identifying these novel frameworks. Some have already been proposed, like the notion of AI as a “cultural technology”—like bureaucracies or markets. I’m not sure whether these are the right metaphors either, but it’s a good time for pluralism.
Thanks to Harvey Lederman, Ben Bergen, Pamela Rivière for extended discussion on this post, and thanks to Harvey Lederman for taking the time to meet and discuss his article in more detail.
From Jack Clark’s appearance on the Ezra Klein Show:
The way that I think of these systems now is that they’re like little troublesome genies that I can give instructions to, and they’ll go and do things for me. But I still need to specify the instruction just right or else they might do something a little wrong.
So it’s very different to typing into a thing, and it figures out a good answer, and that’s the end. Now it’s a case of me summoning these little things to go and do stuff for me, and I have to give them the right instructions because they’ll go away for quite some time and do a whole range of actions.
Though it might be subtly distinct, as Goldstein & Lederman (2025) argue. It’s conceivable that a bat has desires, even even those desires are not particularly humanlike—thus, we can talk about desires without specifically attributing human desires.
For more, I recommend checking out philosopher Henry Shevlin’s work on social AI.
What, in extreme cases, is sometimes called “AI psychosis”.
Cognition is like this as well. Famously, we can analyze cognitive phenomena in terms of their computational properties (roughly: the problem they’re solving), their algorithmic properties (the putative representations and operations with which they solve the problem), or their implementational properties (the underlying “substrate”, e.g., neural dynamics). While cognitive scientists may disagree about which level of analysis they find most useful or most “real”, many would likely agree with the assertion that in many cases, adopting a fully reductive account is not particularly desirable. More concretely: perhaps (!) we could, with enough time and resources, construct an explanatory model of human belief formation at the level of individual neurons and synapses, but such a model would be very unwieldy and not particularly amenable to interpretation or making predictions. (This is to say nothing of the fact that most reductive explanations could in principle be reduced further: why stop at neurons?)
Importantly, this option is available even to committed eliminativists: that is, you can treat these constructs as instrumentally useful (i.e., “convenient fictions”) even if you think they are not, in some deep sense, ontologically real. You could, of course, also be a realist about the existence of these mental states! In either case, the question is whether the intentional stance is a helpful lens for understanding, explaining, and predicting the behavior of your friend.
It’s worth noting that the authors are arguing in favor of a specific approach called interpretationism, and in doing so, they adopt a realist perspective on beliefs; arguably, however, these criteria are equally useful for adjudicating between accounts purely on their instrumental value. I should also point out that even interpretationism, as presented by the authors, does not require positing a phenomenological dimension to beliefs or desires.
Goldstein & Lederman later make a similar case:
The person conversing with ELIZA might say that its behavior was predicted quite well by the hypothesis that it has beliefs and desires. But they would do so in ignorance of key facts about how ELIZA was built. In light of the full story, there is in fact a better explanation of ELIZA’s behavior: it is a lookup table, and the answers to the questions were pre-programmed by the programmers….in the ELIZA example, the lookup table theory of ELIZA’s behavior is at least as tractable but also more accurate and more powerful than the hypothesis that it has beliefs and desires. (pg. 5)
I should note here that Goldstein & Lederman argue that the details of how ChatGPT is trained are not actually necessary components of an argument about whether ChatGPT has (say) beliefs or desires—nor is evidence from mechanistic interpretability. The core thing is whether beliefs, desires, or goals provide the best explanatory account of ChatGPT’s behavior.
This is setting aside yet another issue, which is explicit and intentional misuse of AI systems to cause harm. I think this is perhaps the bigger issue to worry about, but it’s not the focus of Hinton’s concern.
Of course, you could also imagine this happening even without compaction. An LLM might fail to “attend” to certain parts of the prompt such that they are effectively irrelevant to its behavior.
Great article ... My take on stochastic parrots No more parrots!
https://www.linkedin.com/pulse/more-parrots-ben-toth-act3c?utm_source=share&utm_medium=member_android&utm_campaign=share_via
Nice analysis. I completely agree with the principle that we should favour causal descriptions whenever possible. A big issue is that the possibility for this varies depending on who "we" are, and the biggest audience for LLMs is never going to have the technical nous to wield even basic causal descriptions (never mind degenerates like Hinton who should know better).
In some ways, we've already lived with these conditions for a long time. There are various computational artefacts more complex than thermostats where lay people rely on intentional descriptions - if a piece of deterministic software unexpectedly deletes a batch of emails for some opaque reason after a user interaction, a typical user will say that the system "misunderstood" what they were trying to do (implying false belief). That someone from IT could come along and understand the mechanism doesn't mean that the user should forego their own intentional description (how else would they communicate the issue with the IT guy? To some degree, we need stance translation).
The picture is more complicated with LLMs just because there's a decades-long background of anthropomorphising language in AI that has been designed to mislead. We never had to talk about these systems as 'learning', 'intelligent' or 'agentic' - we could have described them as data compressions, program libraries, cultural microcosms etc. - and perhaps there's still time to salvage an alternative vocabulary.
But while I think we could get comfortable with intentional description regardless, it's only going to be safe if we deconstruct widespread misunderstandings about intentional *autonomy*. When we say a thermostat wants a certain temperature, we don't confuse ourselves about the fact that the thermostat is parasitic on a setting encoded by a human. When we say that a piece of deterministic software "misunderstands" our intentions, we use a communicative metaphor because we realise that the issue lies in the *interaction* of the system and the user, not in the system itself.
LLMs have no autonomy and no appropriate intentional description separate from their prompting by humans, and we therefore ought to be able to think and talk about them in the same way as other complex systems. Our present difficulty is that there's enormous commercial pressure for people to suppress recognition of LLMs' parasitism on humans, so we're awash with lies about their potential independence from us.
There are many ways this might be addressed but I think a good start would be to get honest technical people thinking a bit more loosely about the boundaries of computational systems, as has been developed with the Systems Reply to the Chinese Room and the Extended Mind Thesis etc. If people intuitively grok that there isn't a clear boundary between them and the AI model, assumptions about autonomy lose a lot of their bite and intentional description becomes more favourable.