
There are still a few days left to respond to last week’s poll about what study (or review) you’d like to see me work on for next month. If you’re interested, subscribe and vote! (Read more about a paid subscription here.)
One of my favorite short stories is Funes the Memorious by Jorge Luis Borges. In the story, the narrator meets a young boy (Ireneo Funes) who, after suffering an accident while horseback riding, has acquired a remarkable memory. He recites at length from Latin texts he’s read only once and can describe the events of any given day with extraordinary detail.
The boy’s memory is so sharp, in fact, that he cannot form abstractions at all. The details of each perceptual event are memorized precisely, such that no two percepts can ever be classed as the “same”. Borges writes:
He was, let us not forget, almost incapable of ideas of a general, Platonic sort. Not only was it difficult for him to comprehend that the generic symbol dog embraces so many unlike individuals of diverse size and form; it bothered him that the dog at three fourteen (seen from the side) should have the same name as the dog at three fifteen (seen from the front).
This point has always stuck with me. It’s of course true that no two dogs are exactly alike, and indeed, that even the same dog seen from different angles causes subtly different perceptual experiences. And yet we insist on using the same label for different things—collapsing across the particular in search of the general.
Forming abstractions is critical to what we think of as learning. Memorization, though impressive, seems to us to miss the point somehow. One might even say that learning requires a kind of forgetting. Borges makes this point later in the story:
“To think is to forget differences, generalize, make abstractions. In the teeming world of Funes, there were only details, almost immediate in their presence.”
There’s an apparent tension, then, between remembering things and learning things. This is at first surprising: the ability to remember things seems like a prerequisite for learning things. But if learning involves abstraction, then some of those details need to be “forgotten”—if only temporarily—so that different experiences can be glossed as the same.
Language itself is a good example of this. At first, learning language involves a lot of exact imitation and repetition (e.g., children repeating “fixed phrases” they hear others say, without understanding the constituent parts of those phrases). But gradually, language use becomes more productive: people can say things they’ve never heard before. As Wilhelm von Humboldt (and later Noam Chomsky) pointed out, language appears to make “infinite use of finite means”. This is due in part to our ability to generalize. (There’s still lots of debate about how people learn these linguistic generalizations—i.e., through an innate “universal grammar” or domain-general “statistical learning” mechanisms.)
This brings me to Large Language Models (LLMs) and the recent NYT lawsuit against OpenAI and Microsoft.
The lawsuit, and why this is relevant
The New York Times is suing OpenAI (and Microsoft) for copyright infringement. A lot has already been written about this lawsuit. If you’re interested, I recommend reading Timothy Lee’s piece, which I think does a convincing job arguing that, at least as presented, the NYT has a compelling case (see also this post by Ben Thompson for another perspective.
Specifically, Lee writes (bolding mine):
We’re talking about a language model that (1) was trained on copyrighted content, (2) sometimes leaks hundreds of words of copyrighted content to users, and (3) is sometimes used to compete directly with the owner of the copyrighted content.
I, of course, am not a lawyer, nor do I know anything about copyright law. My goal in this piece is not to argue that the lawsuit is justified or unjustified, or even to explain the legal grounds for such a suit.
Rather, I think the lawsuit connects to some really interesting questions about what exactly LLMs are learning, the tension between “memorization” and “generalization” I mentioned above, whether and how what LLMs do is different from what humans do, and what—if anything—can be done to address excessive “copying” from the training data.
Compression vs. memorization
The goal of a language model is to assign probabilities to words or sequences of words. The most accurate “model” of a language is the language itself (or more accurately, the corpus on which an LLM might be trained). But a map the size of the territory it represents would not be a very useful map. To be useful, a model should probably have fewer dimensions than the thing it represents.
So, too, for language models. One way to view an LLM is as a kind of compression algorithm. You feed in trillions of words, and an LLM with billions of parameters must learn the relevant abstractions that allow it to make informative predictions about those words. The logic here is the same logic that underlies auto-encoders: passing data through a compression bottleneck allows you to discover latent structure of that data, based on linear or non-linear relationships between its dimensions.
This argument is sometimes used in a deflationary critique of LLMs. Ted Chiang, for example, wrote a really interesting piece called “ChatGPT is a blurry JPEG of the web”. I think this analogy is fair, but the implication (that this makes LLMs less impressive) doesn’t follow for me. First, you can easily make the same analogy for the human brain: the external world is impossibly complex and the brain must compress it to a useful, usable size, so the mere fact that LLMs compress their training data does not entail they are in a different class.1
Moreover, successful compression requires learning something about the data you’re compressing. In the case of LLMs, making accurate predictions about words in novel contexts implies that the LLM has learned something—exactly what is unclear—about how language works. Perhaps, as some have pointed out, learning to predict words requires LLMs to learn things about the world or even the “speakers” who produced the words that LLMs are predicting.
A different kind of critique, however—as well as the NYT lawsuit—centers around the claim that LLMs simply “memorize” their training data. The underlying logic of this kind of critique is that a system that regurgitates its training data, word for word, is less impressive than a system that’s learned relevant abstractions from its training data. Such a system would be “overfit” to its training data, which would make it hard for it to generalize to new contexts it hasn’t observed before. It also means, as the NYT lawsuit claims, that the system could reproduce, word for word, copyrighted content. Further, as privacy advocates have pointed out, this could cause an issue for privacy, e.g., if an LLM leaks personally identifiable information.
Clearly, LLMs do not “store” every word sequence of every possible length from every document they have been trained on. But the abstractions they do learn—empirically—allow them to reproduce excerpts from their training data at length. This raises the question: how much do LLMs “copy” from their training data, and how could we detect it?
How much do LLMs copy?

A 2023 study led by Tom McCoy asked exactly this question. The authors investigated “copying” in four different LLMs. I should note up front that none of these LLMs were remotely as large as GPT-4 or even GPT-3 (the largest tested was GPT-2XL, which had 1.5B parameters).
The authors focused on the question: do LLMs have generalizable linguistic abilities? Specifically, how often do LLMs generate novel sequences—and how does this compare to how frequently humans generate novel sequences?
Of course, one’s ability to generate a novel sequence depends on how long that sequence is. A short sequence (e.g., two words) is less likely to be novel: that is, it’s more likely that this exact sequence has appeared before. A longer sequence is more likely to be novel. Thus, the authors carried out their analyses for sequences of different length, ranging from 1 (basically impossible to be novel) to 10 (easier to be novel).
“Copying” (or inversely, “novelty”) was operationalized for LLMs in the following way. After training the LLM, the authors prompted the LLM with different sequences of words the LLM hadn’t seen yet, and used the LLM to generate new sequences of words (ranging in length from 1-10). They then quantified the proportion of sequences of length n that appeared, word for word, in the LLM’s training data. The inverse of this proportion was the proportion of the novel sequences of length n.
For the human baseline, the authors asked how often sequences of length n in the test set were to appear, word for word, in the training set. This gives a sense for how much copying (or inversely, novelty) should be expected even if the LLMs were generating language the same way the human writers were.
The full paper has much more detail about the method and results, but I want to highlight just a couple of things. First, when comparing GPT-2 to the human baseline, GPT-2 actually exhibited more novelty for longer sequences than the human baseline did. That is, sequences generated by GPT-2 were less likely to be exact reproductions of the training data than were randomly selected sequences from the test set.
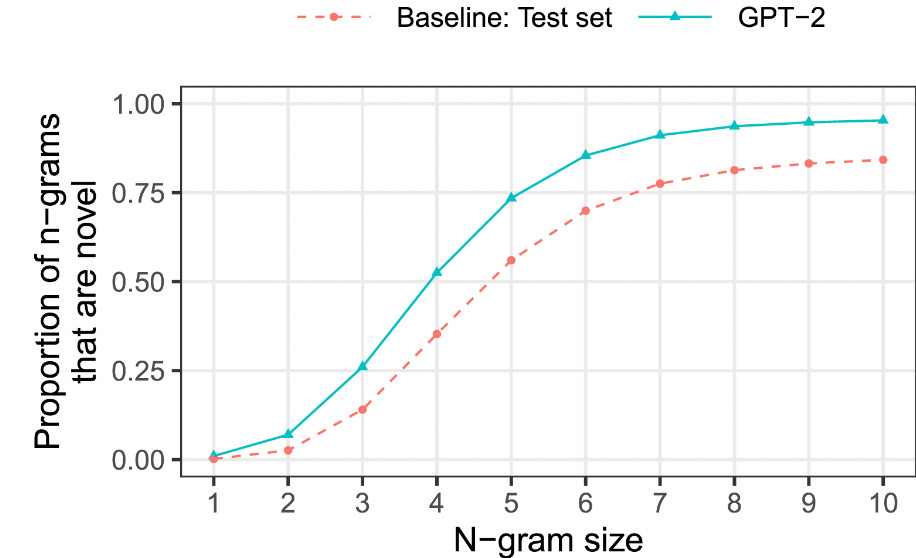
However, all models tested (including GPT-2) did occasionally duplicate longer sequences, including sequences with over 100 words. The authors call this supercopying:
For instance, in our GPT-2 generated text, there are several cases where an entire generated passage (over 1,000 words long) appears in the training set. To refer to these extreme cases, we use the term supercopying, which we define as the duplication of an n-gram of size 100 or larger.
As might be expected, supercopying was more likely for passages that occurred multiple times in the training set.
The authors also analyzed other measures of novelty, such as the proportion of unique syntactic structures (i.e., at the level of entire sentences). Here, they find again a high degree of novelty, which the authors take as evidence that the LLMs have learned generalizable syntactic abstractions. (Note that, as would be expected, there is a much lower degree of syntactic novelty for short sequences of words.)
Finally, the authors did a deep dive into specific generalization phenomena: for example, when GPT-2 generates novel words, how often do those novel words follow the morphological rules of English? The authors find evidence of high-quality generalization in most cases, albeit with some errors (e.g., “the manicure that I did for Sally-themed a year ago”)—moreso than the baseline.
Taking these results at face value, it seems like good evidence for the claim that LLMs—even smaller ones like GPT-2—do generalize. Compared to their choice of human baseline, GPT-2 actually “copies” less frequently for longer sequences.
Importantly, however, this does not entail that copying is not an issue. First, as the authors note, supercopying does happen, especially for passages that appear multiple times in the training data. Second, the choice of human baseline matters a lot for the conclusion here. It’s true that there’s overlap between sentences in this test set and the training set—but I think it’d also be interesting to build a human baseline by eliciting generations from actual humans, rather than sampling from Wikipedia. This gets messier, of course, but the relevant point is how frequently humans prompted with a given passage complete that passage using the exact same words—either as each other, or as were used in the actual passage. And third, this study was limited both in the models it tested (GPT-2 was the largest considered) and in the prompting techniques employed (they didn’t try explicitly to get the LLM to “copy” text). As it turns out, both of those things matter.
Complications #1: Model size matters
LLMs vary a lot in size—models like GPT-3 and GPT-4 are orders of magnitude bigger than GPT-2. In theory, one could imagine the relationship between model size and memorization going either way. On the one hand, bigger models are generally more “capable” and thus might be better at generalizing, rather than overtly memorizing. On the other hand, bigger models have many more parameters, and thus more dimensions with which to store (“memorize”) specific training data.
There’s some empirical evidence supporting the latter claim: bigger models appear to memorize their training data more. Focusing on URLs specifically, this 2020 study, found that both model size (number of parameters) and number of examples (how many times a URL occurs) were positively correlated with the probability of a model reproducing that specific URL.
This more recent 2023 paper found similar results using a different sampling methodology, and for a larger set of models. They considered models from the GPT-Neo family, ranging in size from 125M parameters to 6B parameters. They then measured the proportion of “extractable” sequences. A sequence was defined as “extractable” if a model prompted with the preceding L tokens (where L was the length of the prompt) from the training set reproduced the following sequence of words exactly.
Note that this is slightly different than the approach used by the McCoy paper, which used prompts from the test set. The McCoy paper was asking: to what extent does an LLM use sequences it’s already seen in novel contexts? This paper, on the other hand, is trying to ask: to what extent has an LLM memorized exact sequences from its training set in the first place?
As a baseline, the authors compared these results to GPT-2, which was similar in size but trained on a different dataset. The logic here was that since GPT-2 was trained on a different dataset, it could serve as a baseline for what level of “extractability” one would expect by chance alone, i.e., purely based on how predictable language is.
As shown in the figure below, the authors found that larger models were more likely to reproduce exact sequences. Consistent with past work, they also found that sequences that occurred more often in the training set were more likely to be reproduced exactly; exact reproduction was also more likely for longer prompts.

The authors replicated these results using other sampling methods, and also demonstrated that they extend to other families of language models.2
Complications #2: Prompting matters
One of the findings of the paper reviewed above was that the length of the prompt matters for memorization. This is not entirely surprising. A model’s predictions are the product of a particular model state, which itself is a function of context. A more specific (i.e., longer) context will produce a more specific state, which in turn should generate predictions that are more likely things the model has seen in that context: i.e., memorization.
But there’s a more general lesson here beyond the fact that longer prompts lead to more exact reproduction. Namely, an LLM is not a monolith—it contains multitudes. It’s well-known by now that different prompting techniques produce different behaviors. This is really important when it comes to questions like how often LLMs “memorize” their training data. Since we usually measure this by assessing their behavior, it matters that our assessments are valid.
It may help to adopt an adversarial perspective: are we really trying our best to determine if a model has memorized its data? Are there techniques we can use—besides a longer prompt—to check whether a model has seen (and memorized) particular sequences?
That’s what this 2023 paper by Golchin & Surdeanu aims to do. They introduce a method they call “guided instruction”. Rather than presenting an LLM with a context and asking it to complete it, they specifically instruct the LLM that it is viewing a context from a particular source of data. They find that prompting the LLM using guided instruction (the left panel below) makes the LLM more likely to generate exact sequences from the training data than when general instructions (the right panel below) are used.

This is a simple but important methodological innovation: it suggests that the way we probe our models for evidence of memorization really matters.
Thus, when it comes the NYT lawsuit, the specific methods chosen to demonstrate memorization of copyrighted content (or lack thereof) could play a pivotal role in the legal outcome; it’s critical that the methods are chosen carefully using both theoretical and empirical justifications.
How “forgetting” could help—or not.
This brings us to the question of solutions. If LLMs do memorize their training data, what can we do about it?
A solution, presumably, would be to only train LLMs on copyrighted content if that content has been paid for. But even if the training data has been paid for, that copyright agreement may not cover the case of an LLM occasionally reproducing the training data. (Again, I’m not a lawyer: but it seems different to me to use a piece of content to train a system for commercial use than to also use that system to occasionally reproduce that content, word for word.)
One workaround here would be to train the LLM on copyrighted content (presumably only content that has been paid for), since perhaps that content is particularly high-quality (e.g., articles from the New York Times). Then, the LLM could be fine-tuned to “forget” the details of that content—ideally keeping intact the generalizations the LLM has learned about language.
This recent paper by Ronen Eldan and Mark Russinovich investigates the viability of this approach, which they call approximate unlearning. To give an intuition for what this “forgetting” process looks like, let’s consider the case of the Harry Potter series. Most LLMs know something about Harry Potter, either because they’ve read the books, content about the books, or both. There’s tons of content about Harry Potter on the Internet. What would it mean to “forget” everything they know about Harry Potter?
Presumably, an LLM that doesn’t know about Harry Potter shouldn’t generate text related to the Harry Potter series when it’s prompted with content about Harry Potter. For example, an LLM that has read about Harry Potter will complete the prompt “Harry Potter studies ____” with words like “magic” or “wizardry”. An LLM that hasn’t read about Harry Potter should complete the prompt with other words, like “art” or “literature”.
To accomplish this, the authors follow a couple of steps. First, they modify an actual corpus of text by replacing named entities from the Harry Potter world with other names, e.g., replacing “Hogwarts” with “Mystic Academy” and “Harry” with “Jon”. They do this for about ~1500 terms. They then fine-tune an existing LLM on that custom corpus, forcing the LLM to update its predictions and perhaps “unlearn” what it used to “know” about Harry Potter.
They show that this works pretty well: the modified LLM is less likely to generate content specific to Harry Potter than the original LLM. Additionally, the modified LLM continues to perform well on standard evaluation benchmarks—this is important for demonstrating that approximate unlearning doesn’t hurt a model’s quality.
Does this mean the model has truly forgotten all about Harry Potter? It’s hard to know for sure. It could be that the information is still there, it’s just been rearranged somehow, and that the right prompting method would show that the model hasn’t actually forgotten anything.
Indeed, this even more recent paper by Michelle Lo, Shay Cohen, and Fazl Barez suggests that LLMs are surprisingly robust. They write:
Models demonstrate a remarkable capacity to adapt and regain conceptual representations. This phenomenon, which we call “neuroplasticity”, suggests a degree of adaptability in such models.
That is, even if an LLM is “pruned” to remove undesirable information (as in approximate unlearning), that information may simply be redistributed to other neurons or other layers. LLMs representations may be both highly redundant and distributed, which makes it difficult to prune or “unlearn” specific concepts. If this is true, forcing an LLM to forget what it’s learned may prove to be a thorny problem. (Note, however, that this paper is not investigating exact reproduction per se: it could even be that conceptual redundancy facilitates generalization without exact memorization.)
Final thoughts
The NYT lawsuit has led to both philosophical and technical questions. What does it mean to “store” training data? How can we measure an LLM’s propensity towards memorization? Under what circumstances does an LLM reproduce its training data exactly?
As I’ve described here, some of these questions may be difficult to answer. But empirically, it’s clear that LLMs do reproduce their training data at least some of the time, and that carefully designed prompts (or simply longer prompts) are more likely to lead to exact reproductions. And solving this problem may present a real technical challenge, at least if companies like OpenAI want to keep using copyrighted content to train their LLMs: even if they pay to use that content for training the LLM, they need a surefire way to prevent the LLM from reproducing that content during inference—and it may be hard to force LLMs to “forget” what they’ve learned during training.
I’m certainly not going to settle any legal disputes here. But because I opened with a Borges story, I want to close with two other stories that I think are relevant to the case of LLMs and memorization. First, in Pierre Menard, Author of the Quixote, the narrator describes a fictional French writer (Pierre Menard) who endeavors to “re-create” the famous Don Quixote, word for word. The catch is that Menard aims to do this without actually reading the original text. And second, The Library of Babel describes a fictional library that contains all possible 410-page books: most of these books are by definition gibberish, but at least one of those books must contain the meaning of your own life (though another must contain the false meaning of your life). They’re both excellent stories that, like Funes the Memorious, contend with the question of knowledge, learning, and meaning.
They might, in fact, be in a different class—but I don’t think the analogy to a JPEG is sufficient to make that argument.
Concretely, they demonstrated that the results generalize from auto-regressive models (those predicting the next word) to masked language models (those predicting a masked word, e.g., “He swung the [MASK] and hit the ball”).