

Results from poll #2
"Modifying readability with LLMs" is a winner

This month’s poll for paying subscribers presented four options:
A short follow-up to my empirical study looking at how well large language models (LLMs) estimate the readability of different texts.
A longer (>1 month) follow-up to that same readability study asking how well LLM can modify the readability of a text.
An empirical test of the so-called “winter break hypothesis”.
An empirical study on whether movies these days are more frequently about the past than they used to be.
The winner—by a narrow margin—was (2): a more intensive follow-up looking at how well LLMs can modify the readability of a piece of text. I’m excited to work on this!
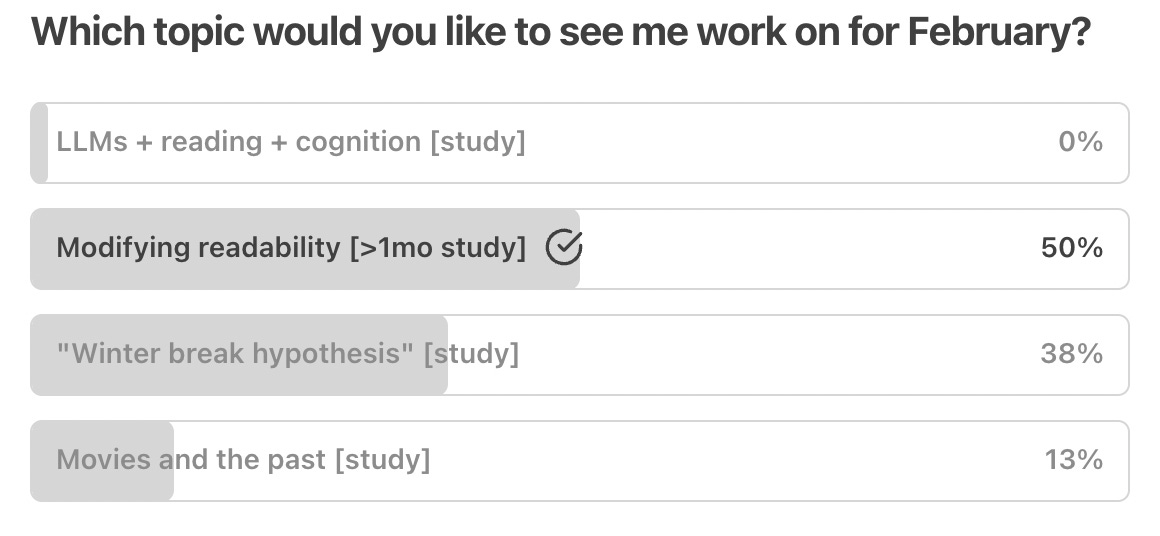
This was a pretty close one. Sorry to those of you who were rooting for the winter break hypothesis. Because that one was close behind, I’ll likely include that option in a future poll.
What to expect
Like I mentioned in the original poll, this readability study will be a little more involved. The primary reason for this is that I’d like to collect human judgments to assess how successfully LLMs modify the readability of a piece of text. I could also calculate this using readability formulas or another LLM (and I will), but I’m not quite ready to give up on humans as the “gold standard” just yet, since “readability” is ultimately a human construct.
But that does mean that I’ll run into complications that wouldn’t arise if I were just using LLMs. Just to give you a sense of what I’m envisioning, here’s what I wrote in the original description of the project:
I’d select a subset of texts (e.g., 100-200 texts) from the CLEAR corpus as my experimental materials.
Then, I’d ask GPT-4 Turbo to generate an “easier” version of each of these texts (or possibly a few easier versions); I might also try the opposite direction too (e.g., create a less accessible version).
Then, I’d run an online human study (e.g., on Prolific) asking people to judge the readability of those new texts. Realistically this would probably involve comparing the original text to the new one and asking which is easier to read.
Optimistically, I’d also like to run a parallel study asking people to judge whether the modified version loses any information or whether it’s still just as informative as the original.
Just for fun, I might ask GPT-4 to do the same task as the humans and see how well its judgments stack up against the human judgments.
Finally, I’d ask whether the modified texts are, on average, judged to be easier than the originals—and also whether they’re judged as losing any information.
There are a number of decision points throughout, but the studies with human participants will definitely be the biggest investment. To keep it tractable (and affordable), I’ll need to limit the number of texts I consider in my sample—particularly since I’d like to get multiple people to make judgments about each text to improve reliability.
My rough estimate is that this will take at least 2 months from start to finish (i.e., including the write-up), and possibly a third. As I mentioned in the February poll, that means there won’t be an additional poll in March. But that doesn’t mean there won’t be any posts! Here’s what you can expect:
Periodic (~1x per month) updates while this project is still ongoing. That includes: planning decisions, exploratory data analysis, and more.
Plenty of the usual content, including some upcoming posts on external validity, negation in LLMs, and so-called “good-enough processing” in human language comprehension.
As always, thanks for reading and for the support.
"but I’m not quite ready to give up on humans"
Speaking as a human, very grateful! (avoiding the apocalyptic <--> utopian hype found elsewhere)
"Then, I’d ask GPT-4 Turbo to generate an “easier” version of each of these texts (or possibly a few easier versions); I might also try the opposite direction too (e.g., create a less accessible version)."
The easier-to-less accessible spectrum is very interesting! I'm interested to see what develops. This is especially pertinent to even the simplest of 'customer service' forms and transactions; owner's manuals; etc.
I don't need to work with GAI, but I amuse myself sometimes by asking GPT4 to rewrite some staid text in the style of a decidely non-staid author -- wonderful results! Here's its title and opening paragraphs of the US Constitution preamble as if written by noir author Raymond Chandler; it takes an unhelpful paradoxical turn, but nails Chandler's tone --
"The Big Preamble
You know, pal, it was a dark and stormy night when they put pen to paper and wrote down the rules. The kind of rules that make a man sit up straight and take notice, like a dame walking into a smoke-filled room with legs that go all the way up to the Bill of Rights.
We, the people, in order to form a more perfect union, decided to lay it all out on the table. We weren't playing games, see? We were serious as a heart attack, and twice as deadly.
We figured we needed some ground rules, like a private eye needs a stiff drink after a long day of tailing suspects. So we said, "Listen up, folks. We're gonna establish justice, insure domestic tranquility, and provide for the common defense. And if anyone tries to mess with us, they'll be swimming with the fishes. ..."
Good luck with this larger study! Looking forward to your progress notes and other posts...