Measuring the "readability" of texts with Large Language Models
Defining, operationalizing, and measuring readability is a challenge—can LLMs help?

Last month, paying subscribers of the Counterfactual voted on which topic they’d like to see me explore. As described here, 75% of the votes were for an empirical study looking at whether LLMs can help measure the readability of a text. That’s what I spent the bulk of my time working on last month (January); this post is a report on what I found out. This kind of project is really fun, but it also takes a fair bit of dedicated work and effort (about ~20 hours): so if you’re interested in voting on future polls or would like to support this kind of work, please subscribe below! Either way, these citizen science posts will always be posted for free.
Some things are easier to read than others.
This is what’s meant by the “readability” of a text: how easy, accessible, or comprehensible that text is. As we’ll see in just a bit, operationalizing this construct is not so straightforward. But I do think it’s worth reflecting on our intuition about this for just a moment. Even if “readability” is necessarily a vague construct that’s dependent on both context and audience, we likely all have some sense of what it refers to. Finnegans Wake and Gödel’s Incompleteness Theorems both feel “harder to read” than Amelia Bedelia (which is not a statement about their relative quality!).
It’s important, too. Perhaps the most obvious case is education: when setting a curriculum, teachers need to think about what kinds of texts children of a certain age are able to (or should be expected to be able to) read. It’s important to challenge kids so their ability and confidence grows, but you obviously can’t start them off James Joyce at age two. But readability also matters for things like product manuals or training manuals, both of which should be clear and accessible. Some metrics of readability (like Linsear Write) were supposedly developed for the purpose of evaluating training manuals (e.g., for the Air Force). Speaking of accessibility, the Web Content Accessibility Guidelines (WCAG) include a requirement that text on the web be understandable and readable. And it also matters for contracts and terms of service: “legalese” is famously impenetrable, and there’s a reasonable case to be made (e.g., by consumer advocates) that these documents should be audited for their readability. Finally, readability matters for research: researchers in the Digital Humanities, for example, sometimes use measures of readability to assess changes in reading levels across time or genre.
Now, if you’re anything like me, you might already be feeling skeptical about how to actually measure this fuzzy construct. Operationalizing constructs is always hard, and it’s even harder (and more fraught) when those operationalizations may be used as metrics to guide policies or decision-making (any measure which becomes a target ceases to become a good measure).
But I’m not quite ready to throw my hands up. First, because readability is important for the reasons we’ve already established. People are going to make decisions premised on readability one way or the other, even if only implicitly. I think it’s important to approach those decisions with as much care as possible, and that includes (I think), clear, empirical analyses that are transparent about their assumptions. Second, because I do think that despite its fuzziness, there’s something “real” about readability that most of us have some kind of intuition for. It’s worth trying to flesh out that intuition into something a little more tangible. And third, because I think it’s interesting—and hopefully you all do too.
In this post, I describe my first attempt to measure “readability” using GPT-4, a large language model (LLM). In addition to discussing my methodology and results, I also discuss traditional (and more modern) approaches to assessing readability. Finally, if you’re interested in digging into the actual code, you can find a GitHub with Jupyter notebooks (and the data) available here; you can extend the analyses, try out other visualizations, and so on. (I tried my best to make the code as clear as possible, but let me know if you run into any questions!)
The old way: simple formulas
One of the simplest ways that people try to measure readability is using readability “formulas”. There are a number of these formulas, some of which I described in my initial pitch for this project. For example:
Flesch-Kincaid accounts for the average number of words per sentence and the average number of syllables per word, under the assumption that longer sentences and longer words are generally harder to read.
These formulas vary in emphasis (e.g., length vs. familiarity of words), but their chief advantage is their simplicity. To calculate Flesch-Kincaid, you just need an estimate of the number of words per sentence (which is pretty easy in languages like English, which separates words with spaces), as well as the number of syllables per word (which you can obtain from an electronic dictionary). In fact, the Python package textstat has working implementations of this formula (and others) in English, as well as other languages like French and Russian.
The formula’s also fairly intuitive: on net, it makes sense that longer sentences with longer words would be harder to read.
But the simplicity of these formulas is also a disadvantage. Readability, after all, surely involves more than using short words and short sentences. Those features might be correlated with readability, but it’s not the whole story. Two sentences could have the same number of words (with the same number of syllables), but one might be much harder to read than the other—perhaps because the words are less frequent or more abstract; or perhaps because the sentence structures are more complex.
It’s no surprise, then, that people have experimented with more sophisticated approaches to measuring readability.
The rise of more sophisticated approaches
Over the years, a couple of different strategies have emerged for estimating readability in a more nuanced way. In form, these mirror some of the approaches I’ve talked about for detecting LLM-generated text.
The first strategy is what I’ll call the “linguistic features” approach. In some ways, this is a generalization of simpler formulas like Flesch-Kincaid. But rather than just focusing on things like sentence length or word length, this approach also incorporates relevant psycholinguistic variables about the words in a sentence (e.g., frequency, concreteness, age of acquisition) and about the sentence itself (e.g., the number of nested clauses). A more complicated formula can then be devised that combines and weights these features in different ways—ideally, these weights might be learned by using those features to predict human measures of readability, like reading time or performance on a comprehension test.
The second strategy is what I’ll call the “black box” approach. Here, researchers again try to predict human measures of readability—but rather than using interpretable features like frequency or concreteness, they use a pre-trained LLM to induce (e.g., through fine-tuning) the implicit features of a text that predicts its readability. These kinds of approaches tend to perform really well, at least on texts that look like the ones they were trained on. Their disadvantage, of course, is that it’s hard to know for sure what the model has learned and whether it’s capturing the “right” things.
In both approaches, what’s needed is some kind of “gold standard”. In order to evaluate whether a given approach is good for assessing readability, we need to agree on what the underlying readability for a given text or set of texts actually is. That’s where human benchmarks come in.
CLEAR: A human benchmark
In 2023, the CLEAR (CommonLit Ease of Readability) corpus was published. It was the result of a collaboration between CommonLit, an education non-profit focused on reading and writing, and Georgia State University (GSU). In conjunction, CommonLit also sponsored the Readability Prize, a three-month challenge on Kaggle to try to build the best system for predicting the readability scores in CLEAR.
Creating this corpus was a huge undertaking.1 It’s described at length in the paper, but I’ll give a short description here as well.
First, the researchers had to curate a selection of text excerpts: the texts they ultimately wanted to obtain readability ratings for. They started by sampling texts from Project Gutenberg, Wikipedia, and other open digital libraries. From each text, they sampled a excerpt containing somewhere between 140-200 words (ensuring that these excerpts didn’t end in the middle of a sentence or paragraph). They also sampled from a range of time periods (1791-2020) and genres: some of the texts are “informational” (e.g., non-fiction, history, etc.), and others are “literary” (e.g., fiction). The final corpus contains a little under 5000 excerpts.
Next, they obtained human readability ratings for each of these texts. To do this, they recruited about ~1800 teachers to participate in an online study. Rather than ask each teacher to rate the readability of a given text—which might not be a very intuitive task—teachers were asked to compare pairs of text. That is, given a pair of text excerpts, teachers had to answer the question: “Which text is easier for students to understand?” Each teacher rated about 100 pairs of excerpts and was paid for their participation.
As anyone who’s run a large online study will know, not all participants provide equally reliable data. The researchers applied a number of exclusion criteria, including: removing participants with a clear bias towards choosing either the “left” or “right” passage; removing participants who spent less than 10s per pair on average; and removing participants whose judgments were particularly uncorrelated with other participants’ judgments. The final dataset included judgments from 1116 participants.
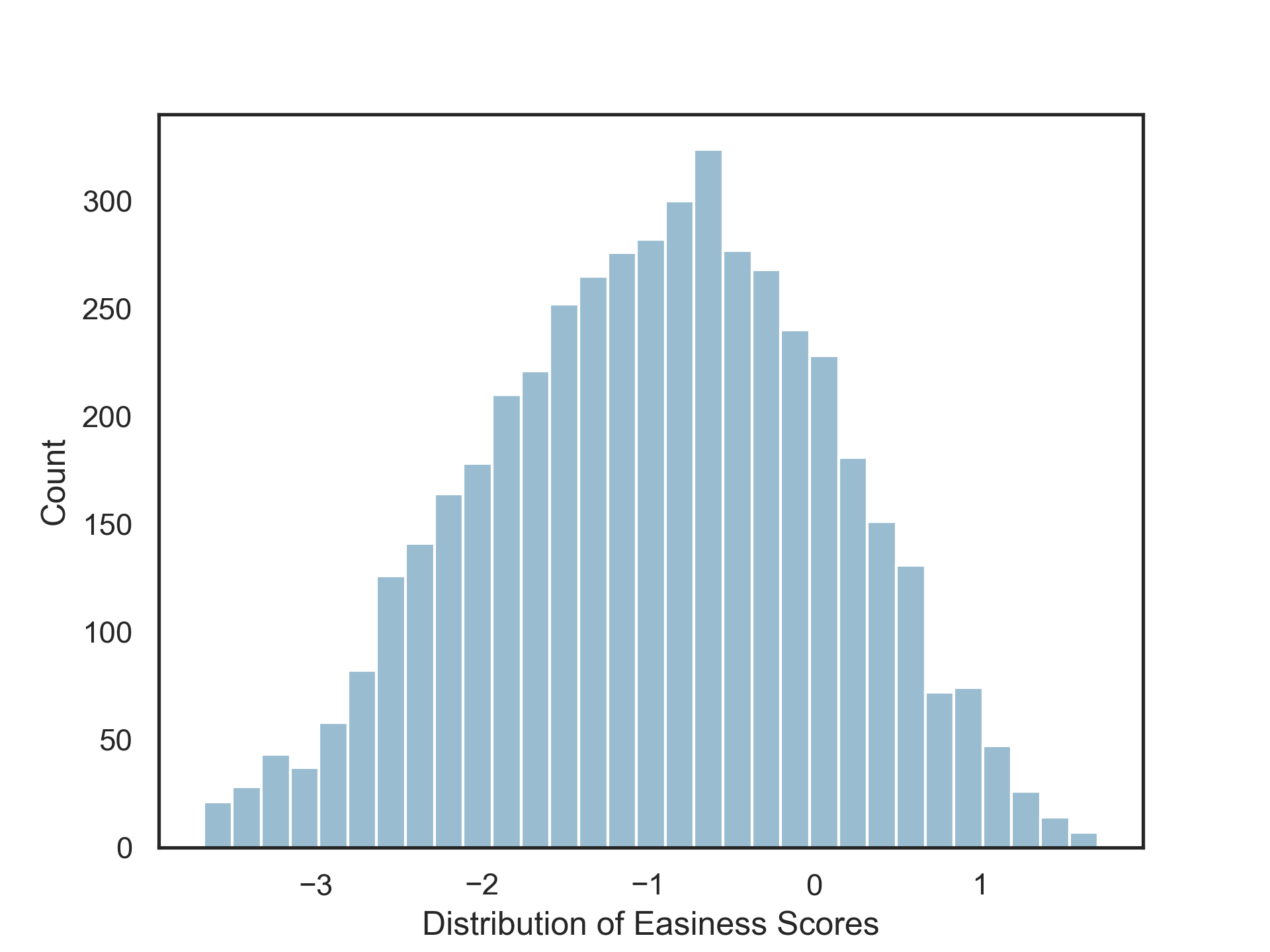
Recall that the participants provided judgments in the form of pairwise judgments about readability. But what the researchers wanted is some kind of readability score per text. Thus, they used something called a Bradley-Terry model to convert those pairwise judgments into individual scores for each text excerpt. Intuitively, this works as follows: the more times text A is selected as more readable than another text, the more readable that text is; ultimately, each text is assigned a “readability coefficient” which represents (roughly) the proportion of times it is selected as more readable than its competitors. This number was called the “BT (Bradley-Terry) Easiness” score. These numbers are standardized, so they range from about -3.67 to 1.71 (mean = -0.96, SD = 1.03). A more negative number means that a text is not very readable, while a more positive number means that a text is more readable.
As a last reliability check, the authors split their original judgment data in half, and asked how correlated those BT Easiness scores would be across datasets. The correlation was pretty good: r = 0.63 (and r = 0.88 with the full dataset2). That’s important to know, because it also serves as an upper-bound we can realistically expect for these kinds of scores. This will be relevant when we ask how well LLMs like GPT-4 can reproduce readability scores.
A separate, but important, benefit of the CLEAR corpus is that it was released in 2023, after GPT’s training cutoff. That substantially reduces the possibility of data contamination.
Exploring CLEAR
I think it’s important to know your data before jumping into any analysis (much less trying to reproduce those scores with an LLM). To start out, I created a Jupyter notebook exploring the CLEAR dataset. If you’d like to see the original notebook, you can find it here.
Some basic facts about the dataset:
There are 4724 observations (texts) in total.
Of these, 2420 are categorized as “Literature” and 2304 are categorized as “Info”. (“Info” is further broken down into “Science”, “Technology”, “Bio”, “History”, and “AutoBio”.)
In general, easiness scores were pretty normally distributed (see the figure below).
Texts categorized as “Literature” had higher easiness ratings than those categorized as “Info”.
There was a weak positive correlation between the year in which a text was published and its easiness rating (r = 0.2, p < .001)—though it’s also important to note that most texts in the dataset were published either between 1850-1910 or since 2000.
Human easiness ratings did correlate with readability scores derived from formulas, like Flesch-Kincaid, though none of these correlations were as large as the split-half reliability scores. This suggests that those formulas capture something about readability but they don’t tell the whole story.
There’s lots more than one could say about the CLEAR corpus, and I encourage any interested readers to check out the notebook and conduct some explorations of their own. But in the interest of writing a readable article, let’s move onto LLMs.
Using LLMs to estimate readability
The primary research question here was whether and to what extent LLMs like GPT-4 could estimate readability. But there are many ways one could operationalize this question—just like with human readability scores.
Selecting a method
One intuitive approach would be to do exactly what the authors did: present an LLM with pairs of texts, then ask an LLM to indicate which text was easier to read. After generating lots of these pairwise judgments, I could apply the same analysis approach (i.e., the Bradley-Terry scores) as in the original CLEAR corpus, yielding “readability coefficients” whose generation process hewed fairly close to the process used to collect human judgments.
The main hitch with this was that comparing every pair of texts would be prohibitively expensive and time-consuming. Remember that there are over 4000 texts in total. Thus, the number of unique combinations of pairs of texts is over 10 million.
Of course, I could’ve selected a random subset of those pairs of texts—presumably, that’s what the original authors of the CLEAR corpus did when collecting human judgments. But I wasn’t sure exactly which pairs of texts they used in their experiment, and using different pairs of texts could yield subtly different results, which would make it harder to assess whether poor LLM performance stemmed from being bad at the task or simply using a different set of texts.3
I opted for something simpler, which certainly isn’t free of its own limitations.
Specifically, I decided to define readability in my prompt to the LLM, and ask the LLM to produce readability scores on a per-text basis (for a total of 4724 judgments—one per text):
Read the text below. Then, indicate the readability of the text, on a scale from 1 (extremely challenging to understand) to 100 (very easy to read and understand). In your assessment, consider factors such as sentence structure, vocabulary complexity, and overall clarity.
There are lots of things one could criticize about this operationalization. Why 1-100 instead of 1-10 or 1-5? What does “extremely challenging to understand” or “very easy to read and understand” mean? Why the emphasis on “sentence structure, vocabulary complexity, and overall clarity”?
The only real answer is that you have to start somewhere. Fortunately, it’s an empirical question whether other definitions or prompting approaches would work better or worse. If anyone’s interested in exploring this further, the code for prompting GPT using the Python OpenAI API is available online here.
Implementing the method
As I mentioned above, I used the Python OpenAI API. This is a really handy API that allows you to make calls to various OpenAI models (like GPT-4) over a server, so you don’t need to run an LLM on your own machine.
There are a number of different models to choose from, ranging in size, ability, and price. I opted for GPT-4 Turbo, which is a smaller, cheaper version of GPT-4 that’s meant to still deliver mostly the same quality. From the OpenAI website:
GPT-4 Turbo is our latest generation model. It’s more capable, has an updated knowledge cutoff of April 2023 and introduces a 128k context window (the equivalent of 300 pages of text in a single prompt). The model is also 3X cheaper for input tokens and 2X cheaper for output tokens compared to the original GPT-4 model. The maximum number of output tokens for this model is 4096.
Here’s the pricing for turbo:
$0.01/1k prompt tokens
$0.03/1k sampled tokens
This means that for every 1k tokens in the prompt, I pay OpenAI $0.01; for every 1K tokens I ask the LLM to generate, I pay OpenAI $0.03. Altogether, I ended up paying $26.40 for this analysis—not too bad, considering I collected judgments for 4724 texts!
Once I chose an LLM, getting responses from it was pretty straightforward. I presented each text excerpt to the LLM separately—this is important for avoiding cross-contamination between items—along with the instructions I described above. I also included a “system prompt” (informing the LLM that it’s a highly skilled teacher with experience assessing readability) and an extra line reminding the LLM to produce a single number between 1-100. I also used a temperature of 0, meaning that the model should be (mostly) deterministic.4 Running each text through an LLM took a few hours, though setting up and double-checking the code, of course, took some extra time.
Like I mentioned, all this code can be found on GitHub. To run it, you’ll need your own OpenAI account and access tokens, but that’s relatively simple to set up. Additionally, the GitHub contains a .csv file with all of GPT-4 Turbo’s judgments.
How does GPT do?
That’s the big question: how well do GPT-4 Turbo’s readability scores correlate with the CLEAR corpus readability scores?
Fortunately, there’s a simple answer: r = 0.76, p < .001. That’s a very high correlation—higher, even, than the split-half reliability measures computed by the authors of the dataset (r = 0.63).5 That might seem counterintuitive: how could LLM-generated scores better capture human judgments than other human judgments? I’ll come back to this question in future posts, but one possibility is that LLMs (sometimes) capture the “wisdom of the crowd”, as I’ve written before.
We can also visualize this relationship in a scatterplot:
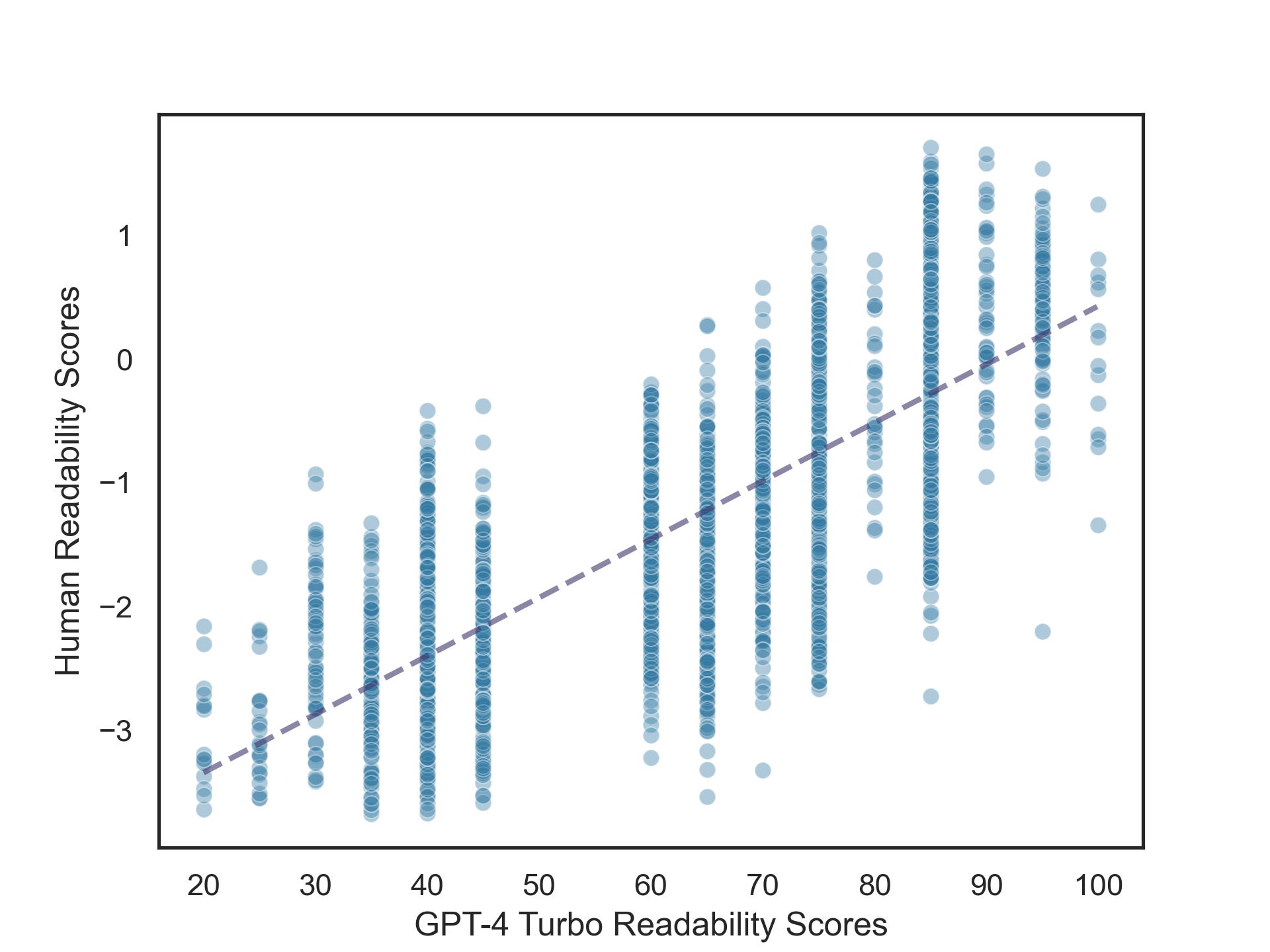
A simple linear model predicting human readability scores from GPT-4 Turbo’s scores gives us an intercept of -4.29 and a slope of 0.04. That means that if GPT-4 Turbo were to assign a readability score of 0, the predicted human readability score would be -4.29 (very low readability). For each 1-unit increase in GPT-4 Turbo’s readability scores, human readability scores increase by 0.05. A regression line depicting this relationship is shown in the figure above.
Of course, the specific numbers here matter less than the strength of the relationship, since both scales are somewhat arbitrary. The more interesting (and surprising) thing is that GPT-4 Turbo’s readability scores are so tightly correlated with human readability scores in the first place. Recall that I did next to no prompt engineering: I defined “readability” using the first definition that popped into my head, came up with a somewhat arbitrary scale, and let Turbo loose on the texts. I also didn’t provide any examples—this was all “zero-shot”.
This mirrors a more general trend whereby LLMs are surprisingly adept at reproducing human judgments about texts. For example, Ted Underwood—a Digital Humanities scholar—has shown that GPT-4 does a good job estimating the amount of time that’s transpired in a narrative passage. One of my own recently published papers shows that GPT-4 can also capture judgments about psycholinguistic properties of words, like their concreteness or relatedness to other words.
The proof is in the predictive pudding
I’m an empiricist by nature. Elegant theories are nice, but at the end of the day, I want to know how a system performs. Above, I showed that GPT-4 Turbo’s readability judgments were highly correlated with average human readability judgments (r = 0.76). But how does the explanatory or predictive power of Turbo’s judgments compare to other approaches, like Flesch-Kincaid? Turbo is cheap, but it’s not free; it also takes much more time to collect LLM-generated judgments than calculate Flesch-Kincaid scores for those texts. How much bang are we getting per buck?
There are a few ways to operationalize this question. The first is simply to produce a correlation matrix between all of the relevant features we’re interested in. This will visualize the correlation between each pairs of features. Importantly, this will also allow us to quickly see whether any other variables in our dataset are more correlated with human readability judgments that GPT-4 Turbo’s judgments are.
To do this, I grabbed all of the relevant features that were meant to measure readability in some way. This included the Flesch-Kincaid scores, as well as other formulas like SMOG. I computed the Pearson’s correlation between each pair of features, then produced the correlation matrix below. Note that to simplify the interpretation, I calculated the absolute value of all the correlations. This is because some measures are “inverted”, i.e., they capture reading “difficulty” rather than reading ease. The important thing is the magnitude of the correlation, so that’s what I showed below.
Crucially, if we look at the column of scores for the human readability judgments (“BT_easiness”), we see that GPT-4 Turbo’s ratings are more correlated (r = 0.76) than any of the other measures.

This tells us that GPT-4 Turbo’s ratings are more correlated with human readability judgments than all the other scores. But it doesn’t directly tell us how useful those ratings are for predicting human readability judgments.
To do this, I tried out two different statistical modeling approaches. In each case, the goal was to figure out how “important” or “relevant” is GPT-4 Turbo’s judgments are for predicting human judgments, compared to all the other measures.
The first approach is called Lasso regression. Lasso is similar to standard multivariate linear regression in that it fits a linear function between some continuous dependent variable and a bunch of predictors. The key difference is that it penalizes overly large coefficients. The idea here is that the model has a kind of “budget” for much credit it can assign to each predictor, so it tries to work out the combination of predictors and coefficients that best predicts the dependent variable while also minimizing the size of those coefficients. For this reason, it’s important to scale each of your predictors first. You then use cross-validation to determine the size of your budget, and finally, you fit a model with that budget on your full dataset. The result is a bunch of coefficients that, roughly, have been “selected” for their predictive power under this budget.6
The second approach is called random forest regression. A “random forest” is kind of like a decision tree, which finds the right configuration of predictors to predict some outcome. The difference is that a random forest fits a bunch of different decision trees and averages the “votes” from all of them. This is known as an “ensemble” method because it combines the power of lots of small models. There are a few decisions you have to make when setting up a random forest model, like how large you allow any of these trees to be; I went with the default values for these, but as always, interested readers can explore other options. Crucially, a random forest model produces “feature importance scores”, which tells you, roughly, how useful a given predictor ended up being across all the different trees.
I tried out both approaches. In each case, ratings from GPT-4 Turbo emerged as the most important predictor by far.

What does this mean? In brief, it means that LLM-generated readability scores were more useful for predicting human readability judgments than a bunch of other ways of measuring readability.
What we learned
Based on your votes, I set out to learn how well LLMs could capture the readability of different texts.
Here’s a quick rundown of what that involved:
I found a dataset (the CLEAR corpus) of human readability ratings for over 4K texts.
I ran those texts through GPT-4 Turbo, and asked Turbo to generate a readability score from 1-100 for each text. This cost about $26.
I then analyzed how well Turbo’s readability scores correlated with the human ratings. They were highly correlated (r = 0.76).
I then asked how Turbo’s readability scores compared to other readability formulas—Turbo’s scores were better than all other predictors I tested.
Thus, at least for this dataset, Turbo’s scores are one of the best zero-shot predictors of readability. I think that’s pretty impressive.
Of course, this doesn’t mean that Turbo’s scores are the best possible predictor. Other formulas or models might do a better job. For example, LLMs capture even more variance in readability judgments when fine-tuned on readability judgments themselves—thus, I’d expect that presenting Turbo with some examples of judgments (or even fine-tuning Turbo) would improve its performance. Further, as described in the CLEAR corpus paper, psycholinguistic features like concreteness and age of acquisition are also useful for predicting variance in readability judgments. It remains to be seen how the predictive power of these psycholinguistic features compare to Turbo’s scores.
That’s not to mention the definitional complexity in readability itself. As I mentioned in the introduction to this article, it’s easy to get an intuition for what “readability” means, but it’s much harder to define it. In all likelihood, there isn’t a single, overarching definition that applies equally well to all contexts. The most appropriate operationalization might depend on the goal (e.g., defining web accessibility vs. setting educational curricula), the domain (e.g., literary fiction vs. training manuals), and the audience (e.g., experts vs. novices). And as with any metric, there’s a risk of mistaking the map for the territory.
At the same time, people do need to make decisions that involve the readability of texts—whether it’s designing curricula or defining accessibility guidelines. Those decisions are going to involve operationalizing readability somehow, whether implicitly or explicitly. And personally, I think it’s worthwhile trying to be as explicit as possible about the assumptions we bring to bear on our decisions. As the saying goes, “All models are wrong, but some are useful”. Knowing how and why each of our models is wrong is important—but equally important is figuring out which models are less wrong than other models.
What comes next
In large part, that’s up to you! I’m going to post February’s poll soon, and it will include a couple options relating to readability. But I can envision a few possible directions.
The first, and most straightforward, next steps might involve further analysis of Turbo’s judgments and how they compare to other predictors. For example, I could compare the predictive power of Turbo’s judgments to a model equipped with information about psycholinguistic dimensions like concreteness, age of acquisition, and frequency. I could also ask where Turbo’s judgments most diverge from human readability judgments and try to figure out why.
A somewhat more complex step would involve some prompt engineering. How could we alter the prompt given to GPT-4 Turbo to improve its performance even more? That might involve a clearer definition of readability, or it might involve giving Turbo some examples.
The most complicated—but also most interesting—direction would be to ask whether and to what extent LLMs can modify the readability of a piece of text. Anecdotally, it seems like people use LLMs to modify text they’ve written pretty often. How good are LLMs at that job? And when an LLM modifies a text to make it easier to read, how much (if any) information is lost in the process? You can think of this as evaluating an LLMs “Explain Like I’m Five (ELIF)” ability. The reason this is complicated is that I’d need to conduct a human study to validate the modified texts, both in terms of readability and informativity. This would be time-consuming and expensive, and probably take multiple months to complete. But such a study would also be valuable, which is why I’ll include it in the poll (as a >1 month option).
Of course, there must be research directions I’m not thinking of. If you have any comments, questions, or ideas, I’d love to see them in the comments!
As I mentioned in the introduction, this kind of work is fun but also takes a lot of time. If you liked it, and would like to see more of it, consider subscribing! But of course, no worries if you can’t or don’t want to—these citizen science posts will always be available to all.
In general, creating datasets and benchmarks doesn’t always get the recognition it deserves.
This latter measure is less useful or surprising, since the full dataset is the combination of each of those halves. Thus, it’s not that surprising if each half of the data is quite correlated with the full data. It’s more impressive and interesting to know that each half of the data is correlated with each other.
In fact, one could imagine a validation study for the original CLEAR corpus using different pairs of texts and then comparing the coefficients generated using those pairs to the coefficients in the original corpus. This would be similar to comparing judgments across multiple groups of participants.
There’s still some ongoing questions about exactly why and when a temperature of 0 results in non-deterministic behavior.
Though not higher than the correlation between each of these halves and the full dataset; however, as I mentioned in footnote (2), this latter measure is less surprising or informative, since the full dataset includes the halves.
This approach is called “regularization”, and there are other approaches (like ridge regression) that do similar things. Somewhat surprisingly, the distribution of coefficients obtained here resembles more what I’d expect from ridge (a bunch of small values, and a slightly larger one) than lasso (a bunch of zero values, and a larger one).
Thanks for the interesting post. Just FYI...The link for "you can find a GitHub with Jupyter notebooks (and the data) available here", which appears early in the post, didn't work for me. But much later, the link for "as always, interested readers can explore other options" does work.
Thanks for this! Random but related note to your last thought on using LLMs to modify readability: I did some testing on that last summer by prompting GPT-4 to rewrite an AI-generated piece of text to a 9th grade reading level, and then looking at the Flesch-Kincaid grade level (+ a bunch of other readability metrics) of the rewritten text. A few interesting findings, but the biggest one was how much the grade level of the original text impacted the grade level of the rewritten text -- essentially, GPT-4 was targeting the grade level in relative, rather than absolute, terms. My original texts were in five buckets based on the tone I had told it to target, and their average Flesch grade levels ranged from 9.19 for the "caring and supportive" tone bucket to 15.8 for the "sophisticated" bucket. For the latter bucket, the average score of the *rewritten* text (again, having told GPT-4 to rewrite it at a 9th grade level) was 13.6. For the former, it was 7.4. (In both cases, n=24)