GPT-4 captures judgments about semantic relatedness quite well
Where it diverges, it does so in interesting ways.

I’m a psycholinguist by training. One thing psycholinguists like to do is collect human judgments about words and phrases. For example:
How concrete is this word? (“Dog” is more concrete than “Freedom”.)
When is this word learned by children, on average? (“Mom” tends to be learned before “statistics”.)
How many people know this word? (More people know “table” than “heteroscedasticity”.)
Which aspects of sensorimotor experience (e.g., vision, hearing, etc.) are associated with this word? (“Lettuce” is associated with taste and smell, while “red” is associated with vision.)
How similar is this word to that word? (“Dog” and “wolf” are similar; “dog” and “tree” are much less similar.)
There are dozens of these databases for English alone. And although psycholinguistics (along with the rest of Cognitive Science) is English-centric, it’s also getting better: there is an increasingly large number of psycholinguistic datasets for languages like Chinese, Portuguese, Japanese, and more.
To an outsider, the utility of these datasets may seem unclear. But they’re important for a few reasons.
First, many of these variables (e.g., concreteness, frequency, age of acquisition, etc.) seems to be correlated with measures of comprehension and production: for example, people are generally faster at identifying and producing frequent words than less frequent ones.
Second, because these variables matter for language processing, psycholinguists often need to control for them in the design of their stimuli: a researcher designing an experiment needs to make sure the words in each condition are matched for frequency, lest they introduce an experimental confound.
Third, these datasets—especially when used in concert—can be used to answer more general questions about words in the lexicon: for example, words with “denser” phonological neighborhoods (the word “bat” is neighbors with words like “cat” and “bad”) tend to be learned earlier and more easily.
And fourth, some of these datasets are increasingly relevant for Natural Language Processing (NLP) practitioners. Most notably, datasets like SimLex999—which contain judgments about how similar different words are—can be used to test whether different language models do a good job capturing human semantic judgments.
All of which brings me to the central question of this post: how well does GPT-4—arguably the “state of the art” when it comes to LLMs—capture human judgments of similarity and relatedness?
Why would this matter?
GPT-4 has passed the bar exam: the question of whether it also knows “dog” is similar to “wolf” but not to “tree” may seem insignificant—even laughable—in comparison. And indeed, classic NLP benchmarks (like similarity judgments) feel less relevant these days, as LLMs can be applied directly to relevant tasks; perhaps we no longer need independent assessments of their general capabilities.
I think there’s a lot of truth to this claim. But I’m still interested in whether GPT-4 accurately predicts things like similarity judgments for at least three reasons:
It’s a useful lens for probing where LLMs converge and diverge from human performance; as I’ve written before, this is important for peeking inside the black box.
If LLMs do a good job, this could revolutionize the field of psycholinguistics—after all, psycholinguists are independently interested in judgments like similarity, concreteness, and so on; if GPT-4 can provide those judgments within a reasonable margin of error, psycholinguists could do their job more cheaply and efficiently.
More theoretically, the success of an LLM in such a task raises the question of whether models like GPT-4 capture something like the wisdom of the crowd.
From a conceptual perspective, I’m particularly interested in (3). There’s already ample research on how the average of many guesses tends to be better than any given guess—because GPT-4 is trained on data from lots of people, are its guesses closer to the “true” value than any given person?1
With that in mind, let’s see how GPT-4 stacks up.
Putting GPT-4 to the test
My current project involves putting GPT-4 to the test on all sorts of psycholinguistic datasets, including concreteness, similarity, and even iconicity—a measure of whether a word sounds like what it means.2
For now, I’m going to focus on two datasets: SimLex999 (similarity scores for 999 word pairs) and RAW-C (relatedness scores for 112 ambiguous words, in 4 contexts each).
I chose SimLex999 because similarity is a classic example of something language models struggle with: many words are related but not similar (e.g., “closet” and “clothes”), and that’s a distinction that (apparently) is often hard to learn from text alone, as “vanilla” language models must.
I chose RAW-C because it measures how related the same word is in two different contexts: for example, “marinated lamb” is more similar to “roasted lamb” than either is to “friendly lamb”. Lexical ambiguity is something that, again, language models have traditionally struggled with compared to humans.
Dataset #1: SimLex999
About the dataset
SimLex999 was created in 2015 by Felix Hill, Roi Reichart, and Anna Korhonen. As I mentioned, it contains judgments about the similarity of 999 English word pairs.
These judgments were made by approximately 500 participants, each of whom rated 119 pairs; altogether, each pair was rated by about 50 subjects. The participants were recruited via Amazon Mechanical Turk, an online platform for recruiting experimental subjects.3
Importantly, subjects were given fairly extensive instructions about their task, which included a definition of similarity (as opposed to relatedness). This image is an example of the instructions they saw:

The experiment looked like this:

The final dataset was created by averaging together the ratings from all subjects who rated a given word pair.
The authors also measured something called inter-rater reliability, which tells us how much different participants agreed for a given word pair. From the dataset’s website:
The average pairwise Spearman correlation between two human raters is 0.67. However, it may be fairer to compare the performance of models with the average correlation of a human rater with the average of all the other raters. This number is 0.78.
The first number means: on average, how much did any given pair of participants agree? The latter number (0.78) just means: on average, how much did any given participant agree with the mean of every other participant?
How did GPT-4 do?
Eliciting similarity judgments from GPT-4 was quite easy. Using the OpenAI Python API, I prompted GPT-4 first with the instructions above (explaining what “similarity” means), then presented each word pair in turn.
GPT-4, unlike older language models like BERT, seems very good at following instructions. That is, I can ask it to provide me a number from 1 to 7, and it produces a number. Perhaps this is not so mind-blowing, given that GPT-4 passes the bar exam, but I continue to find its ability to “figure out” the task you’re asking for pretty remarkable.
Prompting GPT-4 this way gave me a list of 999 numbers: one for each word pair. So how do GPT-4’s judgments stack up to what humans said?
Notably, there’s a range of possible outcomes here:
GPT-4’s ratings could be totally uncorrelated: this is what you’d expect if similarity scores were just totally unlearnable from text. It’s unlikely, given work with past, simpler language models, but still possible.
GPT-4’s ratings could be correlated with human judgments, but less so than humans are with each other: this is more or less what’s happened with past language models.
GPT-4’s ratings could be as correlated with human judgments at least as much as humans are with each other: this would suggest that GPT-4’s capturing similarity just as well as individual humans.
First, I calculated Spearman’s rho, a measure of the rank correlation between two distributions, and found that it was 0.86. (Astute readers will recall that the degree to which human judgments correlated with each other was, at best, 0.78. Does this mean GPT-4 is better at capturing similarity judgments than humans are? What would that even mean, given that the similarity judgments are themselves sourced from humans? I’ll return to this question later on.)
Second, I created a plot showing the relationship between GPT-4’s ratings and human judgments. As you’d expect from the correlation, this is a tight relationship with very little error.
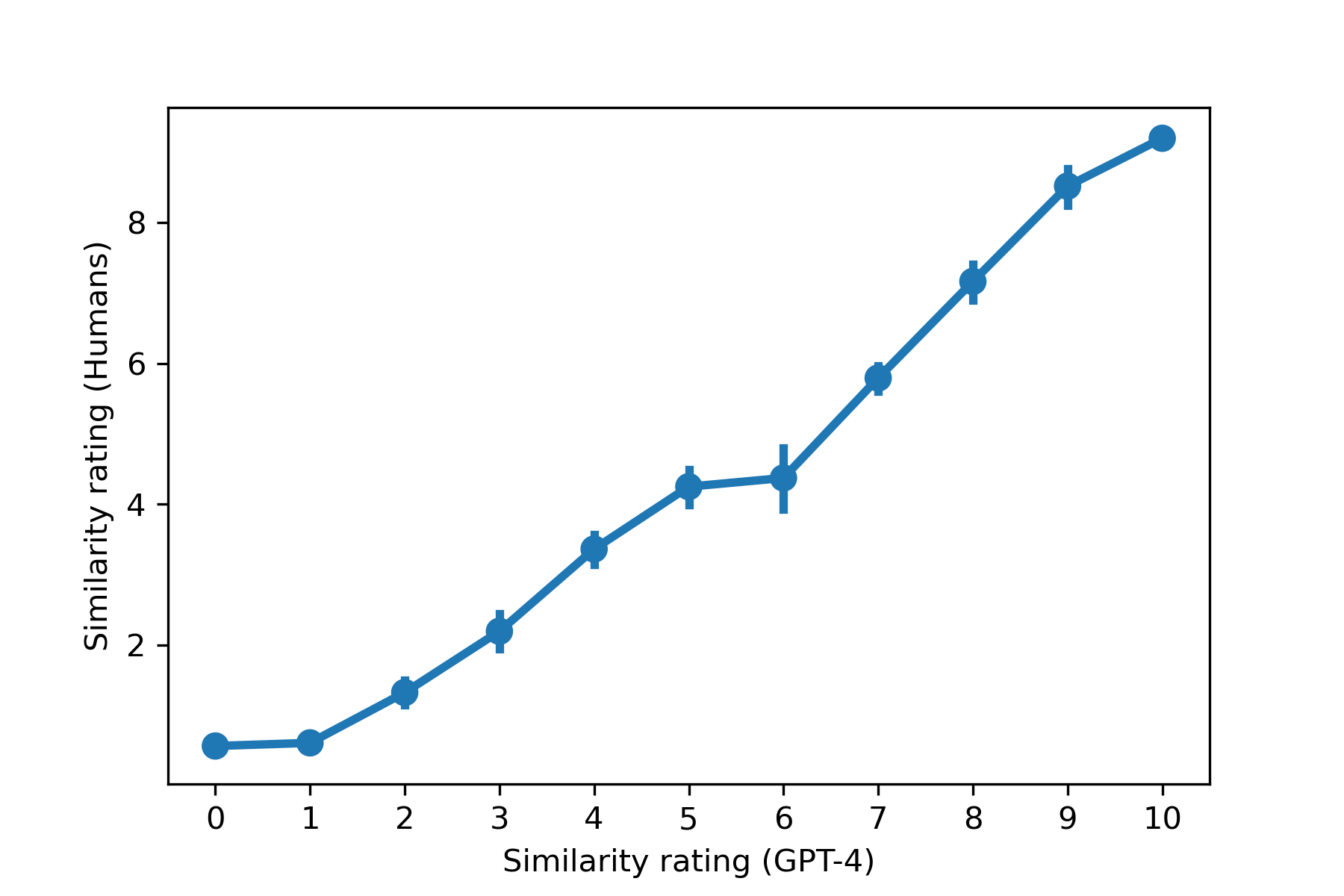
Notably, the authors of SimLex999 also coded whether two words were associated or not. Recall that two words can be associated (e.g., “closet” and “clothes”) without being similar. Traditionally, language models tend to overestimate the similarity of associated but dissimilar words.
Not GPT-4, it seems. The correlation between GPT-4’s ratings and human judgments was remarkably stable, regardless of whether the words were associated (0.86) or not (0.82). It’s possible the correlation was a little better when the words were associated, but in either case, the correlation is higher than even an optimistic judgment of human inter-rater reliability.
So in answer to the question heading this section: GPT-4 does quite well.
Where does GPT-4 go wrong?
It’s also instructive to look at which word pairs GPT-4 gets “wrong”. That is, which word pairs does GPT-4 think are more similar—or less similar—than people did?
To answer this, I ranked word pairs by the absolute difference between GPT-4’s rating and the human rating, and just scanned the top 20. This ranged from an absolute difference of ~6.7 to a difference of ~4.07.
Here are some of the examples:
wife/husband: GPT-4 says these are similar (9) but humans do not (2.3)
multiply/divide: GPT-4 says these are similar (8) but humans do not (1.75).
south/north: GPT-4 says these are similar (8) but humans do not (2.2).
sunset/sunrise: GPT-4 says these are similar (8) but humans do not (2.47).
dog/cat: GPT-4 says these are similar (7) but humans do not (1.75).
And so on.
Notice a pattern? In all the cases listed, GPT-4 assigned a higher similarity score to a word pair than humans did. And in particular, each of these word pair feels like a set of complementary concepts in some way—in some cases they are antonyms or opposites (e.g., “come” and “go”), and in other cases they are mirrors of the same relation (e.g., “wife” and “husband”).
Of the top 20, 15 word pairs (75%) fall clearly into this pattern. The others (liver/lung, rice/bean, bee/ant, leg/arm, and cow/goat) also feel complementary, though in a way that’s a little more idiosyncratic and harder to categorize—perhaps thematically (rice and beans go together) or taxonomically (cows and goats are both farm animals).
All of them, however, also feel like reasonable answers by GPT-4. It’s true that wife and husband aren’t exactly synonymous—and that was the instruction given to participants—but I also wouldn’t say they’re outright dissimilar. Compared to a random pair of concepts, wife and husband seem very similar, in fact.
I’m not simply trying to root for GPT-4 here. I think this raises some really interesting questions about what exactly, these constructs (like similarity) mean—and how best to go about measuring them. Further: I haven’t tried this, but I suspect that simply seeding GPT-4 with an example suggesting that pairs like “wife” and “husband” are not meant to be rated as similar would greatly improve one’s results. That’s next up on my list.
Dataset #2: RAW-C
About the dataset
RAW-C (“Relatedness of Ambiguous Words—in Context”) was published in 2021 by myself and my former advisor, Benjamin Bergen. Like SimLex999, it contains a series of human judgments about the similarity (or technically, relatedness) of different stimuli.
But unlike SimLex999, each judgment is about the same word in different sentence contexts. Words mean different things in different contexts, and so merely calculating the similarity of two words in isolation doesn’t really take into account the ways in which context modifies the meaning of a word. In particular, many words are ambiguous, i.e., they have more than one meaning.
Sometimes these meanings are completely unrelated. For example, the word “bark” could refer to the bark of a dog or the bark of a tree. In other cases, the meanings are related but distinct. The word “lamb” could refer to the animal (“friendly lamb”) or meat produced from that animal (“marinated lamb”).
This was the impetus behind creating the RAW-C dataset. We first identified 112 ambiguous English words, then created four sentences for each word (two for each of the primary meanings). This means that there were six unique pairings of contexts for each word (12 accounting for order).
We presented each pair of contexts to 77 participants (all UCSD undergraduates and native English speakers) and asked them to rate how related in meaning the ambiguous word was across the sentences, ranging from totally unrelated to same meaning. Each trial looked something like this:

Like the creators of SimLex999, we wanted to know how consistent these ratings were across participants. We used the same measure of leave-one-out correlation:
Using this method, the average correlation was ρ = 0.79, with a median of ρ = 0.81 (SD = .07). The lowest agreement was ρ = 0.55, and the highest was ρ = 0.88.
This was actually higher than the average inter-annotator agreement in SimLex999.
Finally, we averaged the ratings for each context pairing across participants to create a single score. For example, the mean relatedness of “hostile atmosphere” and “gaseous atmosphere” was 1.5 (out of 4), while the mean relatedness of “hostile atmosphere” and “tense atmosphere” was a 4 (out of 4).
How did GPT-4 do?
Eliciting relatedness judgments from GPT-4 was strikingly easily. As with SimLex999, I first prompted GPT-4 with the same instructions that human participants saw—which included a brief description of ambiguity in English—and then asked GPT-4 to provide a relatedness judgment.
As a first pass, I computed the Spearman’s rank correlation coefficient between GPT-4’s relatedness judgments and the mean human judgments. This produced a correlation coefficient of .81. This was lower than GPT-4’s performance with SimLex999, but—notably—higher than the average inter-annotator agreement for humans on the RAW-C dataset.
Once again, it seems like GPT-4 did quite well—at least as well as humans, that is.
Where does GPT-4 go wrong?
I still think it’s instructive to look at where GPT-4’s judgments diverge from human judgments.
Recall that with SimLex999, the greatest divergences were produced by GPT-4 overrating (relative to humans) the similarity of “complementary” items (e.g., wife/husband). With RAW-C, in contrast, the divergences seem more like a failure of GPT-4 to identify the correct meaning in context.
Consider the two sentences:
They toasted the strudel.
They toasted the host.
Unless these sentences are referring to one lucky strudel—or one very unlucky dinner host—it seems clear that “toast” has a different meaning across these contexts.4 Yet GPT-4 rates these meanings as fairly related (3 out of 4), while the average human judgment is a 0.5.
Consider another example:
He crossed a friend.
He crossed a room.
Again, GPT-4 overestimates how related these meanings are: it gives them a 3 (out of 4), while humans give them a 0.6 (out of 4).
A consistent error?
This was interesting to me because it echoed an error we saw in the original RAW-C paper.
At the time, we were using a language model called BERT.5 Although a metric of contextual similarity derived from BERT was relatively correlated with human judgments (0.58)—the biggest “mistakes” BERT made were in overestimating the relatedness of distinct meanings, and underestimating the relatedness of the same meaning. We visualized this by examining the residuals—i.e., the “mistakes”—of a regression model trained to predict human relatedness judgments from metrics of relatedness from two LLMs: BERT and ELMo.6

As we argued in the paper, both LLMs:
tended to underestimate how related humans find same-sense uses to be, and overestimate how related humans find different-senses to be.
This effect was particularly noteworthy for homonyms (words with totally distinct meanings), though it was still present for polysemous meanings (e.g., “marinated lamb” vs. “friendly lamb”).
At the time, we argued that this was preliminary evidence for the idea that human semantic representations include something beyond mere distributional regularities: it’s possible we have something like distinct categories, and that exaggerates pre-existing differences BERT and ELMo were already picking up on.7
Yet this also illustrates that—at least on this task—humans do appear to draw on some manner of (likely fuzzy) categorical representation, such that the difference between two contexts of use is compressed for same-sense meanings, and exaggerated for different-sense meanings (particularly for homonyms).
Of course, that was 2021. It’s mid-2023 now, and the NLP world moves fast. Does GPT-4 still make these errors?
Curious, I decided to run the same analysis, but using GPT-4’s ratings instead. First, I built a linear regression predicting human relatedness judgments from GPT-4’s ratings. The R^2 was ~0.65, indicating that GPT-4’s ratings explain 65% of the variance in human relatedness judgments. (That’s a lot!)
Then, I plotted the residuals of this model. As with the visualization above, a positive value means that GPT-4 underestimated how similar two meanings were; a negative value means that GPT-4 overestimated how similar two meanings were.

Intriguingly, the residuals seem slightly biased, and primarily so for words of different meanings. That is, on average, GPT-4 seems to estimate that words of different meanings are more related than they actually are. This effect isn’t huge—it’s certainly less noticeable than it was for BERT and ELMo—but it does seem present.
What have we learned?
I described the motivation for these studies at the start of the essay:
It’s a useful lens for probing where LLMs converge and diverge from human performance; as I’ve written before, this is important for peeking inside the black box.
If LLMs do a good job, this could revolutionize the field of psycholinguistics—after all, psycholinguists are independently interested in judgments like similarity, concreteness, and so on; if GPT-4 can provide those judgments within a reasonable margin of error, psycholinguists could do their job more cheaply and efficiently.
More theoretically, the success of an LLM in such a task raises the question of whether models like GPT-4 capture something like the wisdom of the crowd.
With those criteria in mind, what have we learned?
First, I do think this has proven useful in terms of peeking inside the black box. For both datasets, we learned that GPT-4 captures human semantic judgments very well, and also that it diverges from human judgments in interesting ways:
GPT-4 considers complementary concepts like “wife” and “husband” to be more similar than humans do. Personally, I think this is a fair judgment by GPT-4, and probably calls into question what exactly it means for two things to be “similar”.
GPT-4 overestimates how related distinct meanings of the same word are, e.g., “toasted the strudel” vs. “toasted the host”. This is in line with previous work showing that LLMs fail to capture certain categorical effects of a so-called “sense boundary”. I was surprised by this given how many other improvements we’ve seen with GPT-4.
Second, does this mean psycholinguists should stop asking humans for semantic judgments and just ask GPT-4 instead? I’m not the first person to ask this question—there’s been a flurry of recent papers suggesting that we ought to replace crowd-sourced human annotators with GPT-4 (1, 2, 3, 4)—and I’m certainly not going to resolve the debate here.
But my two cents would be: I think psycholinguists should seriously consider augmenting their data collection process with GPT-4, but I’m still cautious about replacing crowd-sourced workers with GPT-4 entirely. For now, GPT-4 diverges from human judgments in important enough ways that I think replacing them entirely would risk introducing considerable biases and errors into our datasets. We might even fool ourselves into thinking GPT-4’s judgments are the real deal. But I do think the two annotation sources could be used in tandem, potentially enabling annotation at much larger scales.8
As for the third question: does GPT-4 capture the wisdom of the crowd?
Its performance here is extremely impressive. Notably, GPT-4’s judgments are more correlated with the average human judgments than any particular human!
At first glance, this seems impossible. How could GPT-4 be more human than humans? But I think that’s the wrong interpretation. Remember that we’re comparing GPT-4’s judgments to the aggregate human judgment, which collapses across variability in the individual judgments themselves. If we take this aggregate judgment to reflect something like the “true relatedness”,9 then it’s that any given human judgment is going to diverge from that measure at least a little bit. Some humans will overrate relatedness, and some will underrate it; this difference is called sampling error. Now, we also know that collecting a larger sample tends to reduce sampling error. This is exemplified by “wisdom of the crowd” experiments, wherein the average of multiple bets tends to be closer to the true value than any particular bet.
For me, this raises an interesting possibility about how to interpret GPT-4’s role here. Perhaps, in some cases, GPT-4’s judgments can be seen as already averaging across multiple judgments—i.e., GPT-4 represents a “larger sample” than any given human judgment. This isn’t entirely implausible: GPT-4, after all, is trained on much more linguistic input than any human sees in a lifetime; that input also represents language that was produced by many different human speakers and writers. Thus, GPT-4’s “guesses” about the next word may reflect something like the average guess. In limited cases, then, these guesses may already incorporate the wisdom of the crowd, which would explain why GPT-4’s judgments are more correlated with the human average than most individual human judgments are.
This also has deep connections to statistical concepts like the Central Limit Theorem, which I may delve into in more detail in another post.
I’m hoping to have all this code and data up on GitHub soon; if you’d like to see it before then, let me know and I’ll make an effort to speed up this process. Also, note that the analyses described here were not pre-registered; they were pretty straightforward and didn’t leave much room for researcher degrees of freedom, but I do think pre-registration is important. Moving forward, I aim to pre-register all work in this vein.
As far as I can tell, the paper doesn’t say how much each person was paid. The reason this is relevant is if GPT-4 could be used to provide similarity judgments, it may be cheaper than recruiting, say, 500 participants on Amazon Mechanical Turk.
It’s also possible, in principle, that “host” is referring to the sacramental bread. The fun thing about language is that it’s actually very difficult to definitively rule out a given interpretation. The point is that some interpretations are more salient than others, and that’s what we wanted to test with humans.
BERT used to be “state of the art” but has now been far outstripped by LLMs like GPT-3 and GPT-4
ELMo was another popular LLM at the time.
For interested readers, we’ve since followed up on this work in a series of psycholinguistic experiments that were recently published in Psychological Review: paper here.
There’s a separate (and important) question about the ethics of doing this. Personally, I’m not really sure how to compare the ethical harms or benefits of replacing human labor—which is mostly crowd-sourced for very low wages through Amazon Mechanical Turk—with an LLM. In isolation, it’s of course harmful for anyone’s job to be automated. But there were already real, serious concerns about exploitation of human labor on the Mechanical Turk platform. If researchers are concerned about this—and I think it’s fair to be—then they could also consider the fact that because GPT-4 is considerably cheaper than (already cheap) human annotators, researchers could donate some percentage of that savings to an effective charity of their choice.
This might sound like a stretch to some, but I don’t think it is: remember that the whole point of collecting multiple judgments is to produce some average judgment, which is used as a kind of gold standard. There are certainly conceptual issues with doing so when it comes to constructs that display considerable individual variance, but this has been the paradigm in NLP and psycholinguistics for some time now.