"Mechanistic interpretability" for LLMs, explained
Trying to peek inside the "black box".

Interest in Large Language Models (LLMs) like ChatGPT continues to grow, ranging from sectors like education to scientific research. But our eagerness to deploy these systems has outpaced our understanding of how they work. LLMs remain, for the most part, “black boxes”. Even when we know what data they’re trained on and how the models have updated their parameters—which isn’t always true, given that state-of-the-art models are mostly closed-source—we lack mechanistic theories granting insight into and (perhaps even more importantly) control over the behavior of an LLM.
Last month, paying subscribers voted for an explainer piece on mechanistic interpretability (“MI” or “mech interp”): a growing research field that aims to understand the inner workings of LLMs. MI asks questions like:
Which representations do LLMs use to produce the behavior we observe?
How are those representations learned?
Which components of an LLM architecture perform which operations?
In this piece, my goal is threefold. First, I want to convince you that LLMs really are black boxes, and that this is a potential concern; you can think of this as the motivation for something like MI. Second, I’ll give an overview of the techniques that MI researchers use, focusing on a few key examples like this high-profile research by the interpretability team at Anthropic; this section will also discuss some potential applications of MI research. And third, I’ll conclude with a discussion about both the feasibility and utility of MI as a discipline.
Two final, preliminary notes:
Although I’ll briefly touch on what LLMs are and how they work in this post, I highly recommend checking out this explainer piece I co-authored with Timothy Lee of Understanding AI if you’re not familiar with concepts like “transformer architecture”, “layer”, “attention”, or “word vector”.
This piece is intended for readers with some interest in LLMs and how they are studied, but is not intended to be a hands-on tutorial for getting started with mechanistic interpretability (i.e., there won’t be any code). I’ll make references to relevant Python libraries and tools throughout, but if you’re looking for a more hands-on guide, I recommend starting with this page by Neel Nanda, as well as the material from this online course.
Part I: The “black box” problem
A question that often comes up when I discuss research on MI is whether LLMs are, in fact, “black boxes”. As I’ve written before, such a statement sometimes seems counterintuitive:
This fact is surprising to newcomers to the field. Surely, the engineers at OpenAI, Google, and other companies must know how their products work. Isn’t it necessary to understand something before we can build it?
But mechanistic understanding doesn’t always precede use. Particularly in the case of LLMs, there’s an explanatory gap between knowing all the details of how an LLM is trained—and even the precise value of that LLM’s weights—and actually understanding how that training procedure and the weight matrices it produces give rise to specific, predictable behaviors.
Let’s make this concrete. Suppose we had access to the entire set of trained parameters for an LLM. These parameters (or “weights”) are essentially a bunch of numbers that define how to transform the input to an LLM into predictions about what word is most likely to come next. Would we therefore understand all there is to understand about how and why that LLM behaves the way it does?
I don’t think so. Out of context, we don’t know how any of those numbers relate to the LLM’s behavior. Access to the weights is certainly helpful for understanding how an LLM works—it might even be necessary—but it’s not sufficient. Ideally, we’d want to measure the effect of those weights on certain kinds of input to the LLM, which means running experiments and interpreting their results.
To draw an analogy, knowing the position and connectivity of every neuron in the human brain would be helpful for understanding how the brain works. But if we want to understand how brain function relates to cognitive function, then we’d need to “probe” neural activity in the context of some kind of cognitive or behavioral task (like listening to language, or solving math problems).
This ultimately comes down to what it means to “understand” a system like an LLM (or the brain). In my view, “understanding” doesn’t just mean knowing how all the components of the system fit together, even if that is a necessary prerequisite. It means knowing how the system behaves in different contexts, and how those components produce that behavior—both of which are also probably important for being able to predict and control the system. That latter goal is especially important to many people in the MI field, who are concerned about LLM-based systems behaving in ways that are misaligned with the goals of their developers or users.
But is interpretability already resolved?
I was surprised when I came across this statement from Andreessen Horowitz (a16z) to the House of Lords Communications and Digital Select Committee Inquiry, which argued (bolding mine):
Although advocates for AI safety guidelines often allude to the "black box" nature of AI models, where the logic behind their conclusions is not transparent, recent advancements in the AI sector have resolved this issue, thereby ensuring the integrity of open-source code models.
My personal sense is that while techniques for interpretability show some promise, we’re still a long way from this issue being “resolved”. But you don’t just have to take it from me: prominent researchers in the field of MI, like Neel Nanda, argued that a16z’s statement is “massively against the scientific consensus”.
And to be fair to a16z, interpretability is actually listed as a “big tech idea of 2024” on their website, with a description that I think summarizes the field pretty fairly at a high-level:
Now, as these models begin to be deployed in real world situations, the big question is: why? Why do these models say the things they do? Why do some prompts produce better results than others? And, perhaps most importantly, how do we control them?
Overall, then, we may all be on the same page. There’s a growing field of researchers dedicated to this problem, and there’s been some real progress on this front in recent months—but there’s still tons of work to do. I also agree that open-source models are an important part of the interpretability research program, since we definitely have less understanding of what’s going on in closed-source models like ChatGPT.
But at this point, many readers likely still don’t have a coherent idea of what a mechanistic answer to these questions means or what it would look like for an LLM like ChatGPT. I’ll discuss this in more detail when I talk about specific mechanistic interpretability techniques, but I want to give a stab at what I mean first to give some context.
A (very brief) primer on transformer language models
Much (though not all) of current mechanistic interpretability research focuses on transformer language models specifically.1 Timothy Lee and I wrote a thorough explainer on how transformers work, but I’ll quickly outline the big ideas here too.
Transformer language models are, at their core, predictive models: they’re trained to predict the next word (or “token”) from words in the context. Consider the sentence:
I like my coffee with cream and ____
Before a transformer is trained, it doesn’t “know” what word is most likely to come next. But by observing lots of sentences like this one, it gets better at making predictions—and eventually, a trained transformer will (hopefully) assign a higher probability to words like “sugar” than words like “mercury”.
Behind the scenes, these predictions are mediated by a vast set of mathematical operations, defined by the parameters or “weights” I mentioned earlier. There are a few important concepts to understand about how this process works:
First, individual words or “tokens” are represented as large vectors of real numbers. The dimensions themselves don’t mean much, but each word’s relative position in vector-space does reflect things like its similarity in meaning or grammatical function to other words.
Second, words mean different things in different contexts. Transformers make use of a mechanism called attention, which allows them to combine information from words in context. As we wrote in our explainer piece, you can think of attention as a “match-making service for words”, figuring out which words are most relevant to which other words. This involves sharing information across the different word vectors in a sentence.
Third, transformers consist of a number of layers. Word vectors are passed from one layer to another, with each layer implementing additional operations and transformations. These operations include the attention mechanism, as well as a feed-forward network that introduces additional non-linearity into the representations for a given word. Altogether, the components of each layer are called a transformer “block”, and transformer models can contain many of these blocks—all stacked on top of each other. Importantly, the representation (vector) for a given word changes as it moves through the network.
Finally, all these transformations and operations result in a prediction. Concretely, this consists of a probability distribution over all the possible words in a model’s vocabulary. Generative systems like ChatGPT typically generate text by “sampling” from this distribution, e.g., selecting the most likely word.2
There’s lots missing from this very brief explanation. But hopefully you now have a better sense of the components involved in transformer language models.
That’s important, because mechanistic interpretability is all about understanding how those components give rise to behavior, i.e., predictions.
What is a “mechanistic answer” anyway?
LLMs at, at their core, predictive models: they’re trained to predict the next word (or “token”) from words in the context. Consider the sentence:
When Mary and John went to the store, John gave a drink to ____
Reading that sentence, it’s pretty clear the correct prediction should be “Mary”. And indeed, most LLMs at or above the level of GPT-23 would give that response. But how exactly does the LLM make that prediction? And how does the LLM “know” to make a different prediction if the sentence were instead:
When Mary and John went to the store, Mary gave a drink to ____
As Timothy Lee and I wrote in that explainer, this exact problem was the subject of a well-known 2022 paper from a Redwood Research.
At a high-level, making a successful prediction here requires tracking the set of names in the discourse ({“John”, “Mary”}), encoding the subject of the current clause (“John” vs. “Mary”), and “copying” over whichever name was not the subject of the current clause. The researchers ran a number of experiments to identify the specific components of GPT-2 responsible for each of these tasks.
Because GPT-2 is a transformer language model, a “mechanistic” answer ought to involve the components of a transformer specifically. The authors focused on the attention heads, which implement the self-attention mechanism at each layer of the network. Attention is central to transformers, so it makes sense to probe these components in particular. Intuitively, attention also seems pretty relevant to the task at hand, which is all about figuring out how different words in the context relate to each other.
Using some of the methods I’ll talk about below, the authors identified specific attention heads in the network that implemented some of the hypothesized functions mentioned above, e.g., tracking different names in the discourse and selecting whichever name was not the subject of the current clause.
Part II: The mechanistic interpretability toolbox
So what are the tools that MI researchers use?
Surveying all the relevant techniques would be beyond the scope of a single article. But I do want to give a sense of the field’s methodological breadth, as well as which methods are best-suited for which kinds of questions. I’ll be drawing primarily from this review paper, which also presents a helpful taxonomy for MI methods. Some of these methods are used to figure out which components of a transformer are responsible for particular behavior (component attribution), and others help decode the representations at each layer of a transformer (information decoding).4
I’ll be discussing three tools in particular:
Classifier probes.
Activation patching.
Sparse auto-encoders (SAEs).
Tool #1: Classifier probe
What kinds of representations does a transformer language model use to get from its input (a sequence of words) to its output (a prediction about the next word)?
One technique for answering this question is called a classifier probe. In this approach, researchers train something called a classifier—a machine learning tool for sorting observations into different categories—on representations from different layers of a network. Crucially, classifiers are a supervised machine learning approach, meaning they need some kind of label, such as a word’s part of speech (e.g., noun vs. verb) or its semantic role in a sentence (e.g., agent vs. patient). Recall that the representation for a given word changes as it moves through the network. Thus, the overall goal is to figure out which parts (e.g., layers) of the network contain the most information about the label in question.
For example: which parts of a transformer language model are most useful for categorizing a word’s part-of-speech? To answer this, we could consider two different sentences, each containing the word water:
He filled the pool with water (noun).
Don’t forget to water (verb) the plants.
“Water” functions as a noun in the first sentence but a verb in the second. If a language model is doing its job well, it will represent “water” differently in those two sentences.
To test whether this is true—and whether those representations reflect different grammatical categories like noun vs. verb—we could give the model a bunch of sentences with the same words occurring in different parts of speech. Then, we could extract the vector representation for the target word (e.g., “water”) in each layer of the network. Finally, we could train a classifier using those representations to predict part-of-speech (e.g., noun vs. verb). A schematic of this process is illustrated in the figure below.
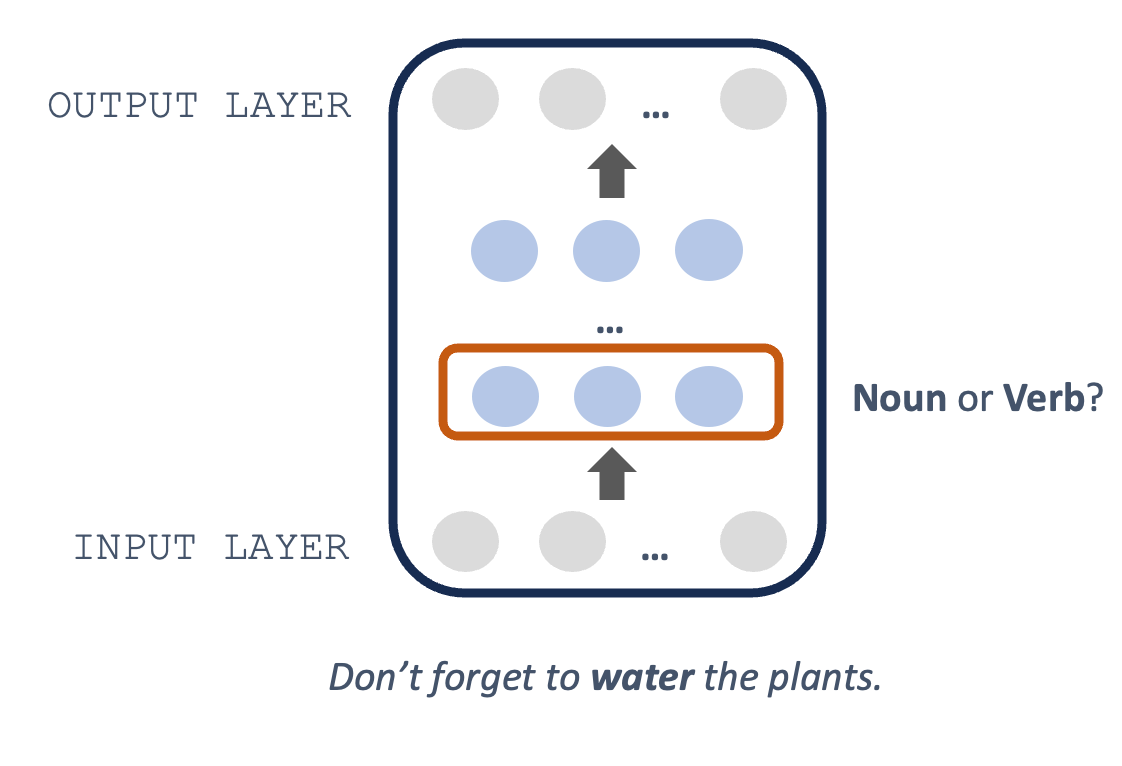
Typically, this process is repeated for each layer of the network. Researchers can then quantify the success of representations from each layer. That is: how much better can you predict a word’s part-of-speech using representations from layer 5 than layer 2? Because performance might improve in general as more information is added across the network, researchers sometimes measure the marginal improvement across layers, as opposed to simply measuring the layer with the best performance.
This technique was used to great effect in a 2019 paper called “BERT Rediscovers the Classical NLP Pipeline”. The authors used classifier probes to figure out which layers of BERT, a popular transformer language model developed by Google, were useful for which tasks. One of the interesting findings of this paper was that in general, earlier layers of the network tended to be more useful for grammatical information like syntax and part-of-speech, and later laters were more useful for semantic information—echoing more traditional, rule-based Natural Language Processing (NLP) systems.
Probing has enjoyed some success and continues to be a useful tool, but as this paper argues, it’s not without its limitations. First, because probing is a supervised approach, researchers need to have fairly explicit hypotheses about which kinds of information the network should be encoding (e.g., part-of-speech or semantic role). Top-down hypotheses are helpful for structuring research, but they can also limit your ability to discover new things. What if the network partitions conceptual space in different ways than we think?
Further, and more importantly, just because the representations at a given layer correlate with supervised labels, it does not mean that the network is actually encoding or using that information. Probing really just tells you about the ability of a probe to learn certain kinds of information—not whether the model uses that information to perform its task. Put another way, correlation does not entail a causal or functional role. This is similar to the inferential challenge with certain cognitive neuroscience tools like fMRI or even single-neuron recording: knowing that a brain region (or neuron) is more or less active during a certain task does not necessarily indicate that this region plays a functional role for that task—and it definitely doesn’t tell you what that function is.
What, then, could tell us something about causal mechanism?
Tool #2: Activation patching
There are a bunch of methods for establishing causal roles, such as ablation (or “knock-out”)—all of which involve some kind of causal intervention—but I want to focus on a specific technique called activation patching. I like activation patching for a couple of reasons:
Unlike probing, it emphasizes the role of particular model components in model predictions, i.e., the thing the model is trained to do.
Proper activation patching requires careful experimental design, like the creation of “minimal pair” sentences, which in my view can benefit from the best parts of psycholinguistics.
Activation patching has been used to understand a number of tasks, including the indirect object identification (IOI) task I mentioned earlier. To illustrate how it works, I’ll use an example from the now-famous ROME paper.
Consider the following two minimal pair sentence fragments:
The Louvre is in ____
The Coliseum is in ____
A good language model—i.e., a model that’s encoded correct associations about landmarks and their locations—should complete the first sentence with “Paris” and the second with “Rome”. We could formalize this intuition by taking the log ratio of probabilities assigned to those words in each sentence by a transformer language model:
Log(P(“Paris”)/P(“Rome”))
In the first sentence, the ratio should be greater than one, and thus the log ratio should be positive; in the second sentence, the ratio should be smaller than one, and thus the log ratio should be negative. Now that we’ve established a metric, we can ask: what components of the language model in question are most responsible for making those predictions?
This is where activation patching comes in. At the highest level, activation patching amounts to copying and pasting activations elicited by Input A to another “run” of the model elicited by Input B. You can think of this as trying to “trick” the model into behaving as if it had seen Input A when really it saw Input B. Concretely: can we make the model think the Coliseum is in Paris?
Here’s how that works in a little more detail (a schematic is also provided below):
First, we run the model (e.g., GPT-2) with each part of a minimal pair and store the activations for each. Let’s call one run (“The Louvre is in ____”) the clean run, and the other (“The Coliseum is in ____”) the corrupted run. We’ll also store the log ratio for our output predictions for each one.
Next, layer-by-layer, we’ll copy activations from the clean run and paste them into the corresponding layer for the corrupted run. (Typically, you’ll be copying/pasting activations for a given token from a given layer component, but more on that in just a moment.) We’ll call this the corrupted-with-restoration run, and we’ll store the modified log ratios for each of those copy/paste actions.
Now we can ask: which of the copy/paste operations produced log ratios that are most similar to the original clean run? That is: even though the model saw “The Coliseum is in ____”, can we get it to assign higher probability to “Paris” than “Rome”?

Activation patching gives us a sense for which parts of a model are most relevant to producing the predictions for the task at hand. Unlike classifier probing, we can be more confident that we’re isolating a causal mechanism here: first, because the minimal pair stimuli are carefully controlled, yet lead to meaningfully different predictions (“Paris” vs. “Rome”); and second, because we’re intervening on the model representations, as opposed to measuring potentially epiphenomenal correlations.
Ultimately, activation patching yields a heat map representing which operations made the biggest difference. One way to do measure this is by dividing the log ratio from the corrupted-with-restoration run (the “patched” run) by the log ratio from the clean run. We want these log ratios to be as similar as possible, so we can look for whichever operations get us closest to 1.
Here’s an example I produced in Python using Neel Nanda’s TransformerLens library and the IOI task, contrasting the following two sentences in GPT-2:
Clean: John and Mary went to the store. John bought a bottle of milk and gave it to ___
Corrupted: John and Mary went to the store. Mary bought a bottle of milk and gave it to ___
For each token at each layer, I copied/pasted the activations from the clean run into the corrupted run (specifically, using the hidden state for that token at that layer). As you can see below, a pretty clear pattern emerges:
At earlier layers, the most effective swaps are at the name token (i.e., the representation for “John” substituted for “Mary”). This makes sense, and is most similar to simply swapping the names out in the original input.
But at later layers, swapping the names doesn’t help so much. Instead, swapping the representations at that critical preposition (“to”) is most effective. This suggests that by later layers in the model, the information that’s most important for making predictions about the next name is stored with that final token.

Of course, patching the hidden states for each token from a given layer isn’t the only way to do activation patching. We could also be more precise, e.g., patching the representations from different attention heads at a given layer. Models tend to have a number of heads at each layer, so this is helpful for isolating more specific components that are relevant to the task at hand.
In this case, for example, we could focus on the attention head outputs for the final token (“to”). This allows us to plot the effect of swapping activations from specific heads, which you can see below. We see there are a couple of heads that make the biggest difference, and in different directions: head 10 at layer 7 exacerbates the corrupted run’s predictions, while head 9 at layer 9 makes the predictions more like the clean run.
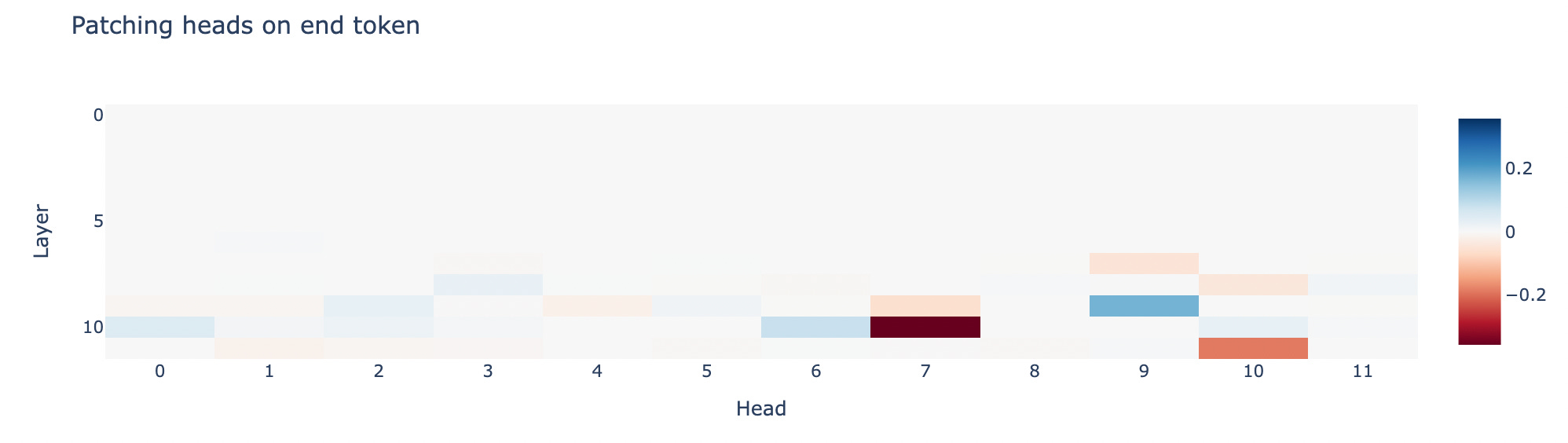
Activation patching is a really powerful tool for figuring out how different components of a transformer model work—but as always, there are limitations. One limitation is interpretive: researchers might be overly hasty to assign a narrow function to specific model components based on their behavior for the task in question, when really those components serve a more general role. This reflects the second, more fundamental limitation, which is that the inferential power of activation patching comes in part from its narrow scope: we limit ourselves to a specific prediction task and use carefully controlled stimuli. Thus, it has many of the same advantages and disadvantages of a psycholinguistics experiment, which is probably why I like it so much.
Tool #3: Sparse auto-encoders
Our third and final tool is something called a sparse auto-encoder (SAE). SAEs have been in the LLM news a lot recently, since they’ve become popular tools among the interpretability teams at major LLM companies like Anthropic. Timothy Lee of Understanding AI already wrote a great article on how Anthropic used SAEs to understand Claude, but I’ll give you the basic intuition here as well.
Suppose you want to understand what all the different neurons—the individual units in each layer—in a transformer language model do. As I’ve written before, this is hard because there are just so many of these neurons: analyzing them one-by-one would be a task of almost Borgesian magnitude, meaning that some kind of automated approach is likely necessary. But a deeper problem is that each of those individual neurons may not map onto human-interpretable concepts or functions in a clear way. Instead, many neurons are polysemantic: that means that the same unit is “active” in a range of different contexts, even entirely unrelated concepts. For example, the same neuron might fire for sentences about cats, linen shirts, and Bayesian inference. Unless I’m missing something, these don’t really fit neatly into a single category.5
As this paper makes clear, polysemanticity is probably a consequence of at least two factors: representations in LLMs are often distributed; and LLMs generally need to represent more concepts (and combinations of concepts) than they have neurons. It’s not necessarily a bad thing—human conceptual representations are likely somewhat distributed too—but it does make interpretability much harder. If a transformer has billions of neurons, and each of those neurons participates in a huge number of distributed representations for different concepts, then figuring out the function of each neuron is going to be challenging and perhaps impossible.
This is where sparse auto-encoders come in. An auto-encoder is a kind of neural network that learns to encode some kind of input into a different representational format, which nonetheless can be decoded back into the original input as cleanly as possible. Often, though not always, the goal is to find a simpler, compressed form of the input representation that still preserves relevant information about the input—as in the example below.
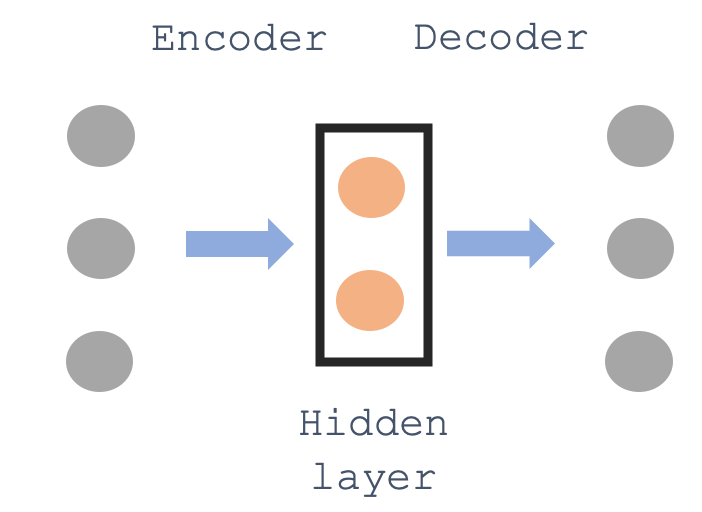
A sparse auto-encoder is a kind of auto-encoder that includes something called a “sparsity penalty”. This means that not only does the auto-encoder need to project the input into some modified-but-analogous representational space, it must do so with a limited “budget”. Specifically, the researchers use something called an “L1 penalty”—a kind of regularization used in statistical models that enforces sparse representations. This means that most neurons in that modified space should be inactive (i.e., set to zero) for any given input. Crucially—and unlike the schematic I included above—this representational space can also be quite large. That gives the sparse auto-encoder plenty of dimensions to work with.
To illustrate how this could work, I’ve created a toy example. Suppose we have a single neuron that responds to a range of words, including: “dog”, “linen”, and “inference”. We can project that neuron into a higher-dimensional space with a sparsity penalty. In the ideal case, the representations in this new space will be both uncorrelated across these different words, and will also be interpretable. That is, a single neuron in that new space will respond to words like “dog”; another neuron will respond to words like “linen”; and yet another neuron will respond to words like “inference”.
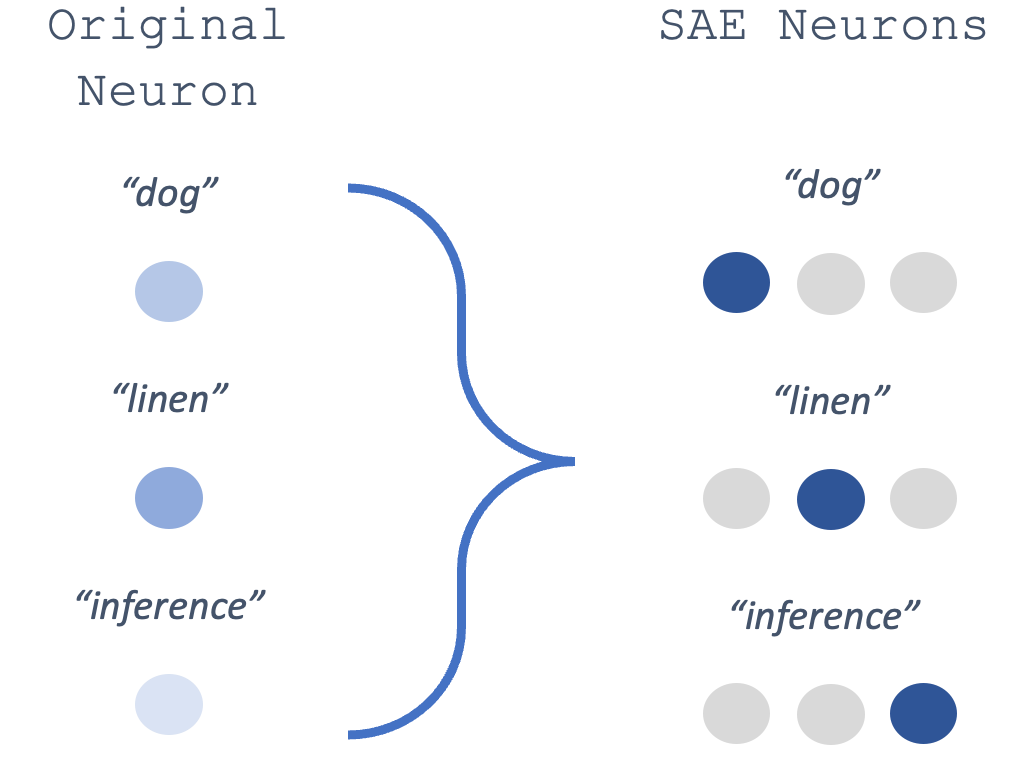
But how do we know whether this new representational space is a fair approximation of the original neural network? To check this, we can calculate something called the “reconstruction loss”. This is a measure of how well we can decode the sparse-auto-encoder’s representation back into the original input format. That is, if we had to “reconstruct” the original input using the modified representation, how much error (loss) would there be?

Why is all this helpful? Remember that the original problem we’re trying to solve is polysemanticity: neurons in an LLM tend to respond to lots of different inputs. Further, any given input tends to result in lots of different neurons firing. With a sparse-autoencoder, we (hopefully) get two things:
Any given input results in a smaller set of active neurons.
Any given neuron tends to be active for a narrower range of inputs.
As I mentioned above, this should make the task of trying to interpret the network much easier. Further, because we know there’s a pretty clean mapping from this sparse auto-encoder space back into the original space—as measured by reconstruction loss—we can be (relatively) confident that we can always “translate” these more interpretable features back into the original space if need be.
Does this actually work? Back in October of 2023, Anthropic put out a really cool report using this approach on a simple transformer model. They were able to find interpretable features that they wouldn’t have been able to discover in the original LLM space, like a representation for Hebrew script. And more recently, they scaled this analysis to Claude 3 Sonnet—a major and important step for the field, as it served as a test of whether this approach works at scale. In their report, they describe in detail a few different kinds of features they discovered:
The Golden Gate Bridge 34M/31164353: Descriptions of or references to the Golden Gate Bridge.
Brain sciences 34M/9493533: discussions of neuroscience and related academic research on brains or minds.
Monuments and popular tourist attractions 1M/887839
Transit infrastructure 1M/3
Of course, simply showing that certain neurons are active for certain inputs is just evidence of correlation. To provide evidence of a causal, functional role, the authors used an approach called “feature steering”, in which they systematically intervened on these features. You can think of this as “turning up (or down) the dial” on a given feature—leading to funny outcomes like “Golden Gate Claude”, a model that turned every conversation back to the Golden Gate Bridge. More relevantly to the goal of AI safety, the authors also found features correlated with more important things, like coding errors or deception. They showed that “steering” these features could also influence Claude’s behavior, e.g., leading Claude to generate false and misleading responses.
Sparse auto-encoders are not a new method—they’ve been used in computational neuroscience for at least a couple decades—but their application to massive language models like Claude represents, in my view, a potentially exciting and promising step for the field of mechanistic interpretability. While there’s still lots of work to do, I think it’s a useful tool in the MI toolbox.
Part III: What’s the point—and will it work?
In Part I, I (hopefully) convinced you that LLMs are “black boxes”, to some extent: we know how to build them but we don’t know exactly how they work. In Part II, I described some of the methods that researchers in the field of mechanistic interpretability use to try to peek inside the black box. But those methods involve a lot of effort, raising the question: what’s the point of all this? And will it even work in the end?
I think there are two main arguments for why mechanistic interpretability research is important. If you’re curious, Anthropic co-founder Chris Olah makes a similar case in this blog post.
Why should we do it?
I’ll start with the less convincing argument, which is that it’s interesting! LLMs are these powerful new systems built on surprisingly simple principles. If you’re like me, you’re at least a little curious about how these systems work. A mechanistic explanation is part of that answer. But I acknowledge that not everyone shares a passion for basic science, or perhaps they think that LLMs aren’t worth devoting resources to studying because they’re not a “natural kind”. I think that’s a fair argument (though I disagree).
The second argument is that it’s important to understand how a system works if we’re going to use that system. I don’t think you have to be concerned about AI and existential risk to worry that it’s potentially dangerous to deploy new systems whose behavior we still don’t entirely understand or control. This is especially true for frameworks in which LLMs are embedded between software modules, replacing traditional APIs (i.e., “text as the universal interface”). Mechanistic interpretability is important for predicting the behavior of these systems and ideally controlling them to avoid behavior we don’t want to see, e.g., mitigating bias or avoiding deception.
With that in mind, let’s turn to two key concerns about the viability of MI as a field.
Is it feasible?
The first concern is that a mechanistic explanation of LLMs simply isn’t possible. We could compare this to a similar concern about the human brain, which is extremely complex and difficult to understand. I think that decades of neuroscience research have given us a better understanding of how the brain works, but maybe we’ll come up against a fundamental limit on what we can learn—especially in terms of relating low-level neural dynamics to abstract constructs like “cognition”.
On the one hand, maybe understanding LLMs will be easier than understanding the human brain: after all, we have greater experimental control. On the other hand, it might be harder: even if relating brain activity to cognition is hard, we can at least try to understand the brain as a hunk of tissue, just like we’d try to understand other organs. Maybe it’s the computational theory of the mind that’s doomed in the end—for both brains and LLMs. If that’s true, it’d suggest that the study of LLMs ought hew as closely as possible to the “raw substrate”: in this case, lots and lots of matrix multiplication.
That could be true. My hope, of course, is that it’s not—that insight, or something like it, will emerge from the study of low-level LLM representations and operations as they relate to observable LLM behavior. Perhaps the strongest argument against this is that LLMs are simply not the “kind of thing” that is usefully studied with these research methods. But as Chris Olah wrote back in late October, mechanistic interpretability may still be in a “pre-paradigmatic” stage: we’re still figuring out what research methods or even research questions are the right ones to ask.
Is it useful?
Not everyone working on AI safety agrees that MI will be among the most useful set of tools for predicting and controlling the behavior of deployed LLMs. A very thorough case against the utility of MI is made in this blog post, and the question is also explored at some length in this discussion between several researchers in MI and AI safety (including Neel Nanda, who I mentioned earlier).
One category of objection is a variant of the “feasibility” concern. For example, this post argues that MI will not be particularly effective for identifying or mitigating deceptive behavior in LLMs. If interpretability is not feasible, then MI will certainly not be very useful.
Yet even if interpretability is feasible, there might be other tools that are easier to use and just as effective. Let’s take the example of “Golden Gate Claude”. It’s cool that this behavior was elicited by “steering feature vectors”, but could the researchers have achieved similar results via clever prompt engineering? If a key argument for MI is that it allows us to control LLM behavior, then it’s important to demonstrate (empirically) that MI guarantees a more precise degree of control than other methods.
What’s next?
Anecdotally, interest in mechanistic interpretability seems to have grown substantially over the last couple of years. I think no small part of that comes from the work of researchers like Neel Nanda creating resources to both broadcast why MI could be important and how others could get started doing MI research of their own. Nanda’s development of open-source tools like TransformerLens has also been incredibly important for helping people (like me) learn MI basics. We’ve also seen the application of methods like sparse auto-encoders to probe state-of-the-art LLMs at scale—an important step in demonstrating the viability of these approaches.
Moving forward, something I hope to see is a greater emphasis on the inferential power (and limits) of any given MI study. As an example, it’s unclear to me whether results obtained on one kind of transformer architecture (e.g., GPT-2) generalize to a different kind of architecture (e.g., BERT). Perhaps even more problematically, most studies that I’m aware of are conducted using models trained primarily (or solely) on English: would the same results hold for models trained on other languages as well? This is an example of external validity, which I’ve written about before, but there are, of course, other ways to evaluate a claim. I don’t want to be unfair here—it’s true that MI is in its early stages, so there are still many epistemic norms to work out. But that’s precisely my point: I’d love to see more and more discussions about that (like this one) and ideally some sort of attempt at systematization.
Related articles:
Thanks to Pam Rivière for reading and editing this post!
This hasn’t always been the case, and may well change if the dominant architecture used in LLMs changes. As recently as 5-6 years ago, for example, most “interpretability” research focused on long short-term memory networks (LSTMs), like this paper from 2019.
Or sampling at a rate proportional to the underlying probability of that word. This is controlled by a temperature parameter.
As the name implies, GPT-2 was a smaller precursor to GPT-3 (and GPT-4). By today’s standards, GPT-2 doesn’t appear that impressive, but at the time it made a big splash.
Another category of approach is called input attribution, which tries to figure out what patterns or properties of the input to a model lead to which kinds of behaviors. This is a really interesting area (especially an area called training data attribution), and I recommend checking out the references in Section 3.1 of this article if you’d like to learn more.
Again, we have a Borgesian problem of category structure!
Awesome post! The figure are gorgeous!
"Maybe it’s the computational theory of the mind that’s doomed in the end—for both brains and LLMs."
Could you explain this in more depth?
Hi Sean,
nice to meet you and thank you for this herculean education on MI, which I had never heard of until I met you.
I am not a coder, just a layman from another time and that was tough work after 4+hrs, but I do have 1 quick question if that's ok.
Do you feel like you've stumbled into: "The Library of Babel" and are now wandering around "The Garden Of Forking Paths"?
After reaching the end, my first thought was, Sean has just opened up the proverbial "Borgesian Can of Infinite Worms" !
Sean, I wish you all the success in your journey, you are a better man than me my friend, and I do hope you find the suitable solution, thank you again for your excellent article and introduction.
Cheers Kev Borg (Kiwi) <3