Newsletter updates
Papers, projects, and a new newsletter.

Every so often, I like to give a general update: typically around the midpoint and end of the year. As we’re now halfway through 2025, I wanted to give a “state of the newsletter” and let readers know what to expect in the latter half of the year. That includes a few different announcements.
The Leaky Margin
The first big announcement is that my wife and I have started a new newsletter called The Leaky Margin, which will be home to reviews of books and, in select cases, other forms of media. The newsletter’s name comes from William James’s Varieties of Religious Experience, in which James at one point describes the borders of conscious experience and attention as a kind of “leaky margin”, the porousness of which may play some role in events such as religious conversion.
We’ve published a few reviews there so far, including one on the evolutionary history of cooking (which I also published here), one on the short fiction of Lydia Davis, and one on Martha Nussbaum’s theory of emotions. We also have a number of other planned essays in the works, with topics ranging from parenting guides to political philosophy. It’s a fun outlet for writing that doesn’t fit squarely within the wheelhouse of the Counterfactual, and I hope some readers will enjoy it—some essays may be posted here as well, provided there’s a good enough fit to the kinds of topics I usually cover.
Upcoming Counterfactual projects
So far this year, I’ve been pleased to hit my target of an average of two posts per month. As per usual, many of these posts have focused on ongoing methodological issues in the field of LLM-ology, such as using LLMs to create benchmarks and the the “moving target” problem presented by the fact that new LLMs are constantly being trained and released. I also published some novel empirical work here trying to identify statistical signatures of LLM-generated text, a topic selected by paid subscribers in a past poll.
Moving forward, I have a number of different posts planned. Here are a few of them:
First, I’m hoping to publish a comprehensive review of research on vision-language models (VLMs) from a Cognitive Science perspective later this month or early August. It’s taken a while in part because (as noted above) new VLMs (and thus new research on VLMs) keep coming out; additionally, many of the “best” VLMs in this space aren’t open-source and so it’s more difficult to study them in a reproducible way. I’d like the review to be relatively current, but I also want it to include studies that are reproducible and pertain to Cognitive Science.
Second, I’ll be writing a series of posts about the philosophy of mechanistic interpretability, largely inspired by some papers I read by Kola Ayronrinde, a researcher at the UK AI Safety Institute (and reader of the Counterfactual). I’ve been moving more and more towards the epistemological foundations of LLM-ology, and Kola’s papers do a great job charting some of the difficulties and goals in mechanistic interpretability research specifically.
Third, I’m working on an essay about AI and education. This is one that’s been knocking around in my head for a while. It’s obviously a hotly discussed topic right now, and periodically a piece (like Everyone is cheating their way through college) will make the rounds and inspire a series of response pieces and so on. As someone who studies LLMs and teaches college courses, I’d like to think I have something useful to say here, but I’d also like to avoid simply repeating what many other people have already pointed out—and it’s hard to talk about any of it without talking about higher education more broadly. Nevertheless, I’m going to do my best and hopefully it’ll be interesting.
I’ll also be posting some new polls for post topics (including “explainers” and novel empirical projects) soon, which will be available to paid subscribers.
A new dataset for probing Spanish language models
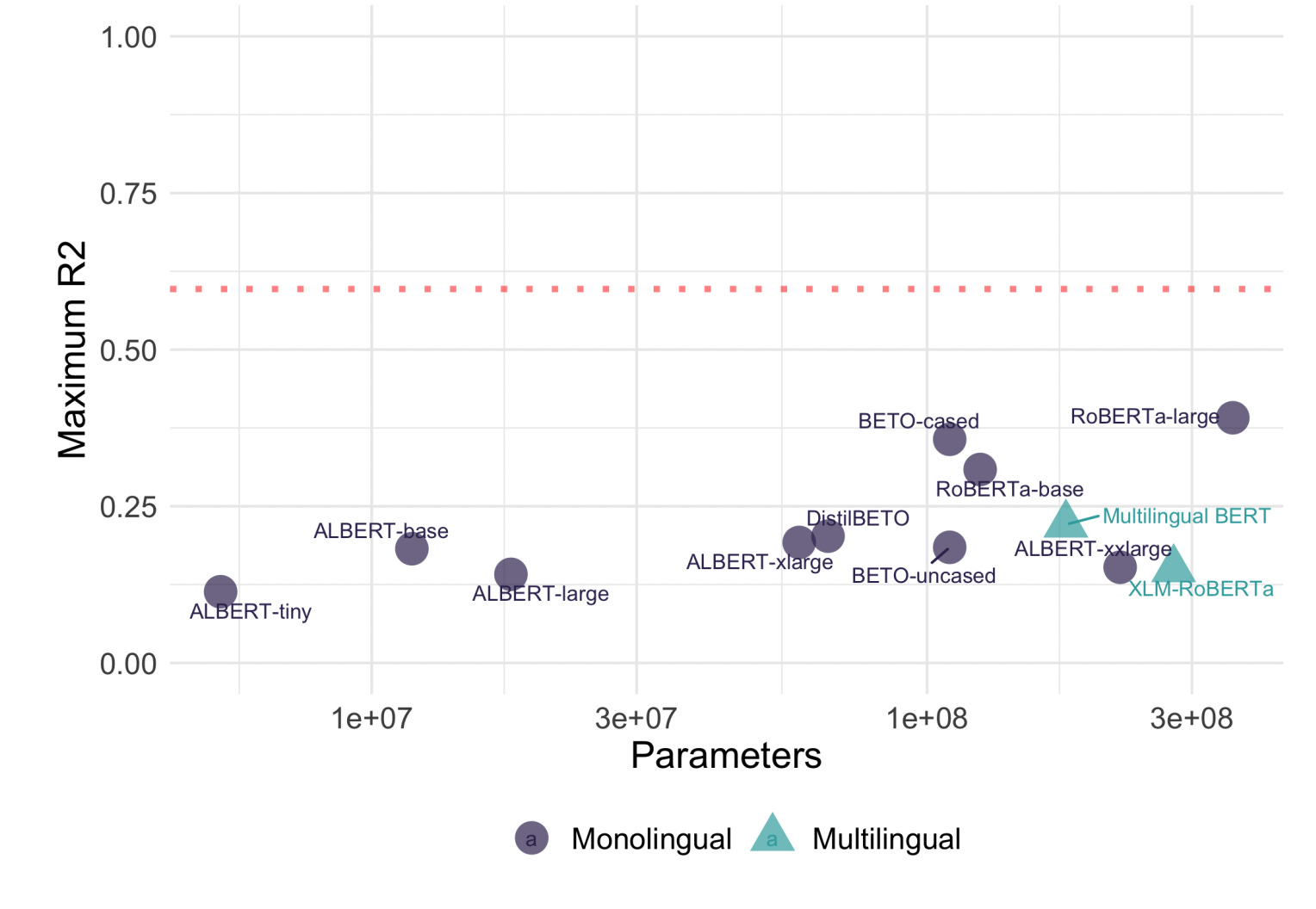
Recently, Pam and I (as well as our co-author, Anne Beatty-Martínez) published a paper describing a new dataset of relatedness norms about Spanish ambiguous words—in context (SAW-C) at NAACL 2025. The dataset is conceptually very similar to one I published a few years back for English ambiguous words. Of course, there are many English-language benchmarks; Spanish, in contrast, has relatively few models and benchmarks given that there are almost 500M native speakers in the world.
The dataset contains minimal pair sentence frames, each containing the same ambiguous word. For example, “clase” is a polysemous word (as in English) that could refer to a school class (“una clase aburrida”) or a socioeconomic class (“una clase media”). The dataset’s not huge: there are 102 words and 812 sentence pairs total. But it was also created and annotated by humans (i.e., not LLM-generated), and subject to pretty extensive validation procedures. Moreover, the stimuli have been carefully designed to eliminate as many confounds as possible, which makes the dataset useful for probing Spanish language models (or multilingual models).
That’s exactly what we did in the paper, which you can find here. In one analysis, we found (unsurprisingly) that larger Spanish language models (LMs) produced representations that better matched human judgments. More intriguing was the finding for multilingual models tested in Spanish, which tended to slightly under-perform what we’d expect, given their size. We’ve since replicated this finding with a larger number of monolingual and multilingual LMs (including on an English dataset), and we’re investigating possible explanations for this “curse of multilinguality”. The reason I mention it here is to point out that novel datasets—especially ones subject to careful human curation and annotation—can hopefully help to advance our understanding of LLMs.
An upcoming change
In a recent post, I alluded to a cross-country move. That’s because my wife, daughter, and I are all moving from California to New Jersey later this year. My wife and I were fortunate enough to procure positions at Rutgers University, and I’ll be joining the Psychology department at the Newark campus as an Assistant Professor. I’m really excited to start my own lab studying the intersection of human and machine cognition, with a focus on the epistemological foundations of that work.
These all sound like great directions, and excited to have you over on the East Coast!
Looking forward to your thoughts on LLMs and education, Sean. There's a long history connecting AI and education. Shayan Doroudi's Intertwined Histories of AI and Education is fascinating and aligns with my own memories of that history. https://sites.google.com/uci.edu/shayan-doroudi/publications/history-ai-ed?authuser=0