We should be cautious about LLM-generated benchmarks
Synthetic data has its place, but stimuli are at the heart of how we probe and assess LLMs (and humans)—and that calls for special care.

How do researchers study the capacities and inner workings of large language models (or humans)?
Typically, we select some theoretical construct we’re interested in understanding better, such as Theory of Mind. We try to flesh out how to assess this construct, i.e., how we will operationalize it in an experiment. And then, crucially, we have to come up with the actual content of that experiment—what we usually call “stimuli” (alternatively: “items” or “questions”1).
Each of these steps can be fraught: I’ve written before about how hard it is to operationalize constructs, and also about the challenges involved in crafting good benchmarks more generally. But one aspect that doesn’t always get as much attention is the process of creating the stimuli themselves. This is, in my view, one of the most important steps: the stimuli are what we actually present to a large language model (LLM) or human. They may not be as fun to talk about as abstract theoretical constructs like “Theory of Mind” or “Intelligence”, but they’re as concrete and close to the action as it gets.
Unfortunately, creating stimuli is often seen as a bit of a pain. As someone who’s crafted stimuli for many experiments now, it is challenging—and it’s hard to get right. You need to make sure you’re actually assessing what you think you’re assessing (construct validity), and you need to make sure you eliminate as many confounds as possible (internal validity).

It’s little surprise, then, that some researchers are increasingly turning to LLMs to help generate these stimuli. In the last several months alone, I’ve reviewed dozens of papers doing exactly this. While synthetic data has its place in LLM-ology—something I’ll get into below—I’m concerned about this development. In short: I think we should be really cautious about using LLMs to generate the stimuli we later use to assess LLMs!
My thinking on this has changed, somewhat
Long-time readers might remember a post I wrote back in 2023, which discussed the viability of using LLMs to accelerate various parts of the scientific process, including the creation of experimental stimuli. Looking back at that post, it’s less that I’ve completely changed my mind—and more that I’m simply more cautious and skeptical about the practical viability of creating stimuli with LLMs.
A big part of that evolution has been seeing actual examples of LLM-generated benchmarks in practice. Back then, I was interested in this as an abstract scientific question: how good could LLM-generated stimuli be? Now, I see how LLM-generated stimuli are being used “on the ground” (as opposed to in their ideal, Platonic form) and I’m more concerned about the lack of human oversight in how these benchmarks are being built and deployed.
As I’ll describe below, some of the issues I see in these approaches are not unique to LLM-generated benchmarks: many benchmarks are on shaky ground, epistemologically speaking. But in my limited experience, these LLM-generated benchmarks open up the epistemological gap even wider. My hope with this post is to use some of these problems as a jumping-off point for motivating best practices in creating good experimental stimuli.
Benchmarks already had problems
To be clear: benchmarks have had issues for a long time. One paper I like to recommend on this topic is “AI and the Everything in the Whole Wide World Benchmark” (Raji et al., 2021). This paper highlights a number of deep conceptual problems with benchmarks for language (and vision) systems, but also mentions some specific issues found with benchmark stimuli, such as:
Specifically, a well-critiqued limitation of ImageNet is that the objects tend to be centered within the images, which does not reflect how “natural” images actually appear [Barbu et al., 2019].
Similarly, Joy Buolamwini and Timnit Gebru famously identified disparities in which groups were adequately represented in both the training data and benchmarks used for face recognition models, specifically:
We find that these datasets are overwhelmingly composed of lighter-skinned subjects (79.6% for IJB-A and 86.2% for Adience) and introduce a new facial analysis dataset which is balanced by gender and skin type. We evaluate 3 commercial gender classification systems using our dataset and show that darker-skinned females are the most misclassified group (with error rates of up to 34.7%).
More recently, I came across this post identifying a number of pretty glaring errors in MMLU, a popular benchmark used to assess language understanding in LLMs and other systems. The author looked at some of the questions that LLMs most frequently get wrong and found that many of the questions themselves had errors. I’m not sure where all these errors came from, but presumably the dataset was not adequately validated.
The list could go on. My point is that no benchmark is perfect, and errors are common even in datasets created by humans. But that doesn’t excuse the errors, whether they’re made by humans or by LLMs. As scientists interested in getting the answer right—and, presumably, in taking pride in our work—we should want to make sure our benchmarks are as valid as possible.
That brings me to the problem of LLM-generated benchmarks.
Asking LLMs to assess themselves
The case for using LLMs to help make experimental stimuli or craft benchmark questions is pretty clear. As I mentioned above, this process is really time-consuming. An LLM can create many more questions in 10-20 minutes than a human could create in days. If the goal is scale—benchmarks that are as large as possible—then it stands to reason we’ll need some way to automate the process of creating those benchmarks.
I’ve seen some critics make the case that this amounts to asking LLMs to writing a test for themselves, then taking it. That analogy sounds apt, but I’m not sure it’s necessarily a fair critique: first, because many researchers use a different LLM to design the stimuli than the one(s) they use to take the experiment; and second, because even if the same LLM was used for both, it seems plausible to me that clever prompting could elicit a test that would still be challenging and novel. Unlike humans, it’s not like the LLM “designing” the questions would remember them later (unless the researchers fine-tuned the model on those questions). That’s not to say it wouldn’t constitute a kind of data contamination—just that I think it’s a complicated issue.
But there is a distinct—and, in my view, major—problem with this approach, and it relates to the more general epistemological framework of designing experiments and benchmarks. Earlier, I discussed how designing an experiment involves taking some theoretical construct of interest (e.g., “Theory of Mind”), figuring out how to operationalize that construct, then producing specific experimental stimuli to present to subjects. Assuming each of these steps have been executed with care, researchers can then use the empirical results to draw inferences about that theoretical construct.
But when researchers use LLMs to produce those stimuli without substantial human oversight, there’s a big question mark introduced into this process. If human researchers didn’t author the experimental stimuli, how can we be sure they represent what we think they represent (construct validity)? Further, how can we be sure they’re as free of confounds as they could possibly be (internal validity)? And in the absence of these assurances, can we really draw the same kinds of inferences about the theoretical construct we’re interested in?
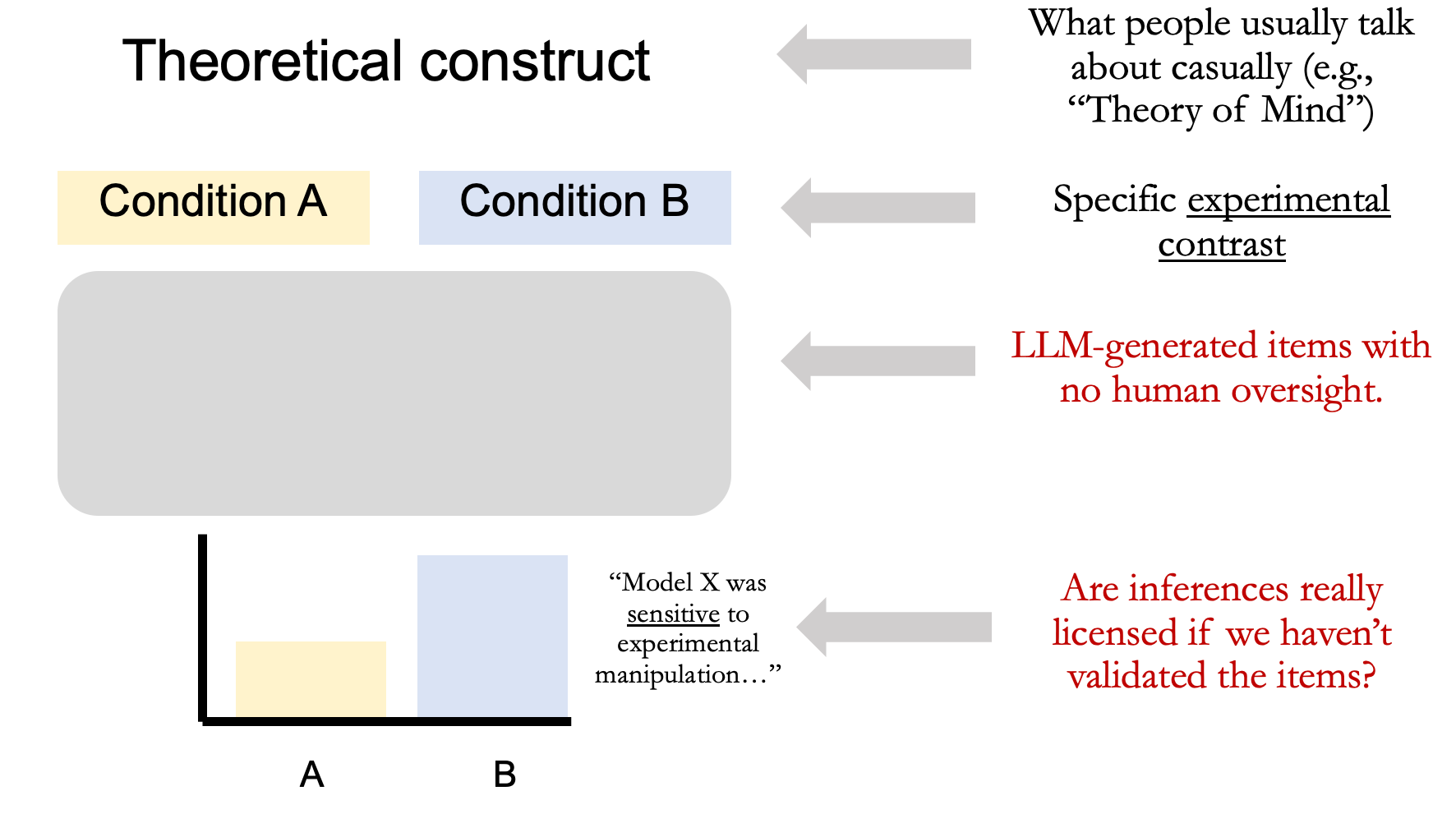
Discussing the use of AI in science more broadly, a recent Nature paper by Lisa Messeri and Molly Crockett argued that excessive reliance on AI systems can create an “illusion of explanatory depth”2 among scientific researchers. That is, a researcher using an AI system might come to believe they (the researcher) understand the scientific phenomenon in question in more detail than they actually do.
That’s more or less the situation I’m referring to: there’s an epistemological gap in the scientific process.
What makes stimuli valid?
One objection I could imagine a reader having at this point is that benchmarks and experiments designed by humans have all sorts of problems too. Is the epistemological gap I’m describing really unique to LLMs?
As I mentioned earlier, my point isn’t that all stimuli designed by humans are perfect and all stimuli designed by LLMs are terrible (though anecdotally, I still don’t think ChatGPT is very good at creating controlled stimuli). If I was designing an experiment that called for carefully controlled minimal pair stimuli—items with only one key difference across conditions—I wouldn’t ask a random person off the street with no knowledge of the subject matter and no experience designing psycholinguistic stimuli to write them for me.
Now, ChatGPT might be better at creating stimuli than a random person off the street, or it might not. The crucial thing is that any process for designing a study needs to have mechanisms for ensuring that study’s validity. There are a number of ways to accomplish this, and ideally a researcher would pursue all of them.
First, if a researcher is a subject matter expert, they will almost certainly have a much better grasp of the theoretical construct they’re trying to assess and how to create stimuli that target that construct. The chance that they’ll produce valid stimuli is even higher if they have experience creating stimuli in the past and know what kinds of issues to look out for. Some of those issues are generalizable (e.g., it’s important to control for word frequency), but some are pretty specific to particular domains and involve a kind of tacit knowledge. I’ve found that there’s a certain craft involved in designing a good experiment that’s hard to learn from a book—the kind of specialized knowledge-from-experience that James Scott calls metis in Seeing Like a State.
Second, a researcher will want to ensure that stimuli across conditions3 are matched for factors other than the key construct that’s being manipulated. Some of these things could be checked automatically (e.g., length), but others (e.g., naturalness or plausibility) might require running a small study of human participants. It’s possible that LLMs could help with this step, and indeed I’ve published some research suggesting that they can, but I’d personally be quite cautious about relying on purely LLM-generated data here: that same paper highlights some systematic biases in synthetic data that aren’t present in human data. In general, I think LLMs could help augment this process (e.g., allowing researchers to collect fewer human samples), but I’d still want humans in the loop somehow given the unpredictability of the kinds of errors I’ve observed with LLMs.
Third, a researcher might also want to norm the stimuli for the key experimental contrast in question. For example, suppose you’ve designed a set of Metaphorical vs. Literal sentences matched for length, and you want to know whether people are faster to read the Metaphorical sentences than the Literal sentences. In addition to controlling for other confounds (e.g., plausibility), you might want to ensure that the metaphorical sentences are, indeed, metaphorical. One straightforward way to do this is (again) to ask a sample of human participants to explicitly rate your stimuli according to the construct in question (e.g., metaphoricity), then ask whether those ratings vary across conditions in the way you intended.
Of course, we’ve been discussing this in the context of evaluating LLMs, not simply running human experiments. That raises a fourth desideratum: a researcher should collect a human baseline against which to compare LLM performance. For example, if the measure of interest is overall accuracy, it is important to know how well on average humans tended to do on the same test; if the measure of interest is sensitivity to some experimental manipulation, it is again critical to know whether humans are also sensitive to that manipulation, and by how much.
At this point, a proponent of LLM-generated benchmarks might note that only the first of these mechanisms involves a human explicitly crafting stimuli. In principle, then, one could create (or augment) the stimuli with an LLM, then attempt to ensure their validity by following these other steps: matching them for known confounds; norming them for the construct of interest; and collecting a human baseline. My response is that I think those things would certainly all be good to do, and that I’d be more confident about an LLM-generated benchmark that was subjected to these tests than one that wasn’t. In fact, I’d probably prefer such a benchmark to one that was created by humans with no relevant expertise or experience and was also not subjected to any of those validation procedures.
Personally, I’d still be pretty cautious about an LLM-generated benchmark. I think a human researcher should at least look at the stimuli—I’m not entirely comfortable with the large epistemological gap that would open up otherwise. That said, I wouldn’t dismiss it if researchers had both looked over the stimuli and done their due diligence to validate the stimuli in other ways.
More generally, though, I do think there’s an emphasis on building big benchmarks that, while understandable and even laudable in cases, sometimes comes at the cost of ensuring their quality. A benchmark with 50K questions isn’t necessarily more useful than a benchmark with 500 questions if those 50K questions are all poorly designed. I understand the push to accelerate this process using LLMs, but at the very least, we should take the opportunity to raise the bar for what we consider a high-quality benchmark, and that means making an effort to validate our stimuli.
Stimuli often aren’t actually questions, which is why I prefer the term “stimulus”, since what we’re creating is, literally, a stimulus to present to the system we’re interested in studying.
As far as I know, this term was introduced in a 2002 paper illustrating the limits of our knowledge about relatively “everyday” objects. We might think we know how a stapler works because most of us have used one, but do we really?
Or correct vs. incorrect response options.