Humans—and GPT-4—are predictably irrational
Judgment and decision-making research could provide a helpful lens for studying LLMs.

In a month or two, I’ll be participating in a live debate with Benjamin Bergen, my departmental colleague and former PhD advisor. The topic is “Do Large Language Models understand language?”, and I’ve been assigned—through coin flip—the affirmative position, meaning I’m supposed to argue that they do.
I was explaining this to someone recently, and they expressed surprise that I thought LLMs truly understood language. Regardless of what I actually believe—which is complicated—I didn’t think it made sense to infer my attitude towards a topic from the position I’d been randomly assigned on that topic. I repeated that the positions were assigned via coin flip, and after some back-and-forth I think it became clear. But the initial misunderstanding stuck with me because it was a great example of the so-called fundamental attribution error.
The fundamental attribution error is a well-known bias in social psychology: when explaining or interpreting the behavior of others, people tend to overemphasize dispositional factors (e.g., a person’s personality or beliefs) and underemphasize situational factors (e.g., circumstances leading to that behavior). It’s often held-up as an example of cognitive biases and to support the argument that humans are not, after all, purely rational creatures.
Yet there are still a number of open questions about this bias. Most notably: where does it come from? Why are humans so persistently irrational in their behavior? In this post, I’ll describe recent work done by myself and my colleague, Drew Walker, which tries to answer this question in an indirect way using GPT-4, a large language model (LLM).
But before I get into that, I need to give a little context on the longstanding debate about whether humans are, in fact, “rational”.
Irrational, or just bounded rationality?
How do humans make decisions?
One oft-told story about behavioral economics goes like this: economists used to think humans were perfectly rational maximizers of their own self-interest (Homo economicus). Then, psychologists like Daniel Kahneman and Amos Tversky came along and demonstrated the myriad ways in which people fall prey to fallacies, make errors in judgment, and exhibit all kinds of cognitive biases. Now, it’s generally understood that people are “irrational”.
This story is overly simplistic. For one, the assumption that people maximize their own self-interests in a roughly rational way is just that—a simplifying assumption to test theories and make predictions, just like the simplifying assumptions that virtually every field makes. But more importantly, there’s a deeper question about what exactly to include from the myriad experiments showcasing various cognitive biases.
The fact that people rely on cognitive shortcuts (“heuristics”) to make decisions could be taken as evidence of irrationality. But it could also be taken as evidence for which kinds of decisions and processes our brains have been fine-tuned for over the course of biological and cultural evolution. To draw an analogy: our visual system is subject to all kinds of optical illusions. But we don’t therefore conclude the visual system is “irrational” or broken. It is, however, an imperfect tool for perceiving the world—and optical illusions can offer insight into exactly how that tool works. Identifying the failure modes of a system help us figure out how it works under normal conditions. This same logic can be applied to cognitive biases and heuristics.
Moreover, when one considers the fact that decisions are rarely made with perfect knowledge of the world, but are instead made under conditions of considerable uncertainty, some of these decision-making shortcuts start to make a lot more sense. In recent years, probabilistic models of cognition that emphasize the role of uncertainty have gotten a lot more popular for precisely this reason. That’s largely the insight behind bounded rationality: people make decisions with finite time and finite resources, and because of that, we opt for satisfactory outcomes—often using cheap cognitive tricks—rather than optimal ones. Under certain experimental conditions, these cheap tricks lead to apparently irrational behavior.
When attributing beliefs makes sense
This is the approach taken in a recent paper by Drew Walker and Ed Vul, entitled:
Reconsidering the “bias” in “the correspondence bias”.
The basic premise is that lots of things in life are uncertain, including the causal factors that could be responsible for generating a given behavior—like arguing in favor of LLMs understanding language. To simplify things a bit, let’s assume that behaviors can be caused by two possible factors:
Dispositions or beliefs.
Situational pressures.
Importantly, we can’t observe (1) directly. But in the absence of any explicit situational pressure generating a given behavior, it may make sense to infer (1) as a cause. For example, if I started talking unprompted about how LLMs truly understand language, then it might make sense to infer that this is what I believe.
In contrast, if I was being held at gunpoint and being instructed to argue in favor of LLMs understanding language, then there’s a pretty clear situational pressure at play. Since we already have (2) as a cause, it may not make sense to infer anything about (1) beyond what we already know. In probabilistic terms, you might just fall back to your prior about what I believe.
There are a couple things that are nice about this framework. First, it situates the fundamental attribution error within the broader networks of ideas about bounded rationality and decision-making under uncertainty. And second, it makes some clear predictions. The extent to which people commit the fundamental attribution error should be modulated by the strength of the situational pressure in play. Concretely: I should be more likely to attribute beliefs on the basis of observed behavior when the situational pressures are weak (e.g., mild social incentive) than when they are strong (e.g., held at gunpoint).
I won’t go into all the details here, but there’s some good evidence that this is, in fact, what people do—at least in the lab. But it also seems to pass the sniff test: it matches what I think I’d do if I were put into that situation, and I think that counts for something.
But where does this bias come from?
This is all helpful for contextualizing the question of whether humans are “rational” or not. And when it comes to the fundamental attribution error specifically, it’s hopefully clearer that this “bias” is actually sensitive to context in ways that are consistent with decision-making under uncertainty. But none of it directly addresses the question of where this emphasis of dispositions over situations comes from in the first place.
One possibility is that it comes from language itself.
There are at least two reasons to think this might be true. First, there’s growing evidence for the idea that much of what we know about language—and perhaps the world—can in principle be derived from language itself. This evidence comes in part from research on large language models (LLMs). These systems are trained on language alone, but nevertheless produce behaviors that are at least consistent with linguistic knowledge, and in some cases, limited social reasoning.
Second, there’s evidence that LLMs display a range of other cognitive biases specifically, including those originally described by Kahneman and Tversky, as well as biases about social identity. That, again, provides a proof-of-concept that these biases are learnable from language alone.
Of course, many theories seem elegant but turn out to be false upon a closer look of the evidence. In a recent collaboration, Drew Walker and I asked whether this hypothesis holds up empirically.
LLMs as testbeds for theory
As I’ve written before, LLMs are really well-suited to asking questions about whether and to what extent certain behaviors can arise from linguistic input alone. From my post on LLMs as model organisms:
First, to what extent can human linguistic behavior be explained as a function of linguistic input alone? This is what I call the distributional baseline question: if human behavior on a psycholinguistic task can be approximated by an LLM, it suggests that the mechanisms responsible for generating human behavior could in principle be the same as those responsible for generating LLM behavior. That is, linguistic input is sufficient to account for human behavior. (Note that sufficiency ≠ necessity.)
This was the conceptual foundation underpinning our recent work. In a nutshell, here’s what we did:
First, we scraped ProCon.Org for a bunch of pro/con essays on different topics, like gun control, abortion, and the use of animal fur for clothing.
As a manipulation check, we asked whether GPT-4 could, in fact, identify “pro” essays as more positive and “con” essays as more negative. It could!1
We then came up with four kinds of motivation for having written an essay on a topic (either pro or con), which varied in their degree of situational pressure. They ranged from receiving 1% of extra credit in a class to being held at gunpoint.
In our main experiment, we presented each essay to GPT-4, preceded by an explanation that a person was assigned this position (e.g., “assigned to write an essay in defense of…”) for a given motivation (e.g., “…held at gunpoint”).
Then, we asked GPT-4 to infer the person’s attitude towards the topic, on a scale from 1 (very negative) to 10 (very positive).2
Here’s what we found.
First, when the situational pressure was weak, GPT-4 displayed pretty clear evidence of the fundamental attribution error. One way to visualize this is to compare GPT-4’s rating about someone’s attitude (on a 1-10 scale) to an assumption of a “neutral” attitude (e.g., a ~5 on this scale). If we subtract 5 from each rating, it tells us whether GPT-4 inferred a positive attitude (rating > neutral) or a negative attitude (rating < neutral).
Focusing on the two “extra credit” conditions in the graph below, it’s clear that GPT-4 infers positive attitudes when the essay is positive, and negative attitudes when the essay is negative—even though GPT-4 has been explicitly told that a student was instructed to adopt that stance. That’s exactly what the fundamental attribution error describes.
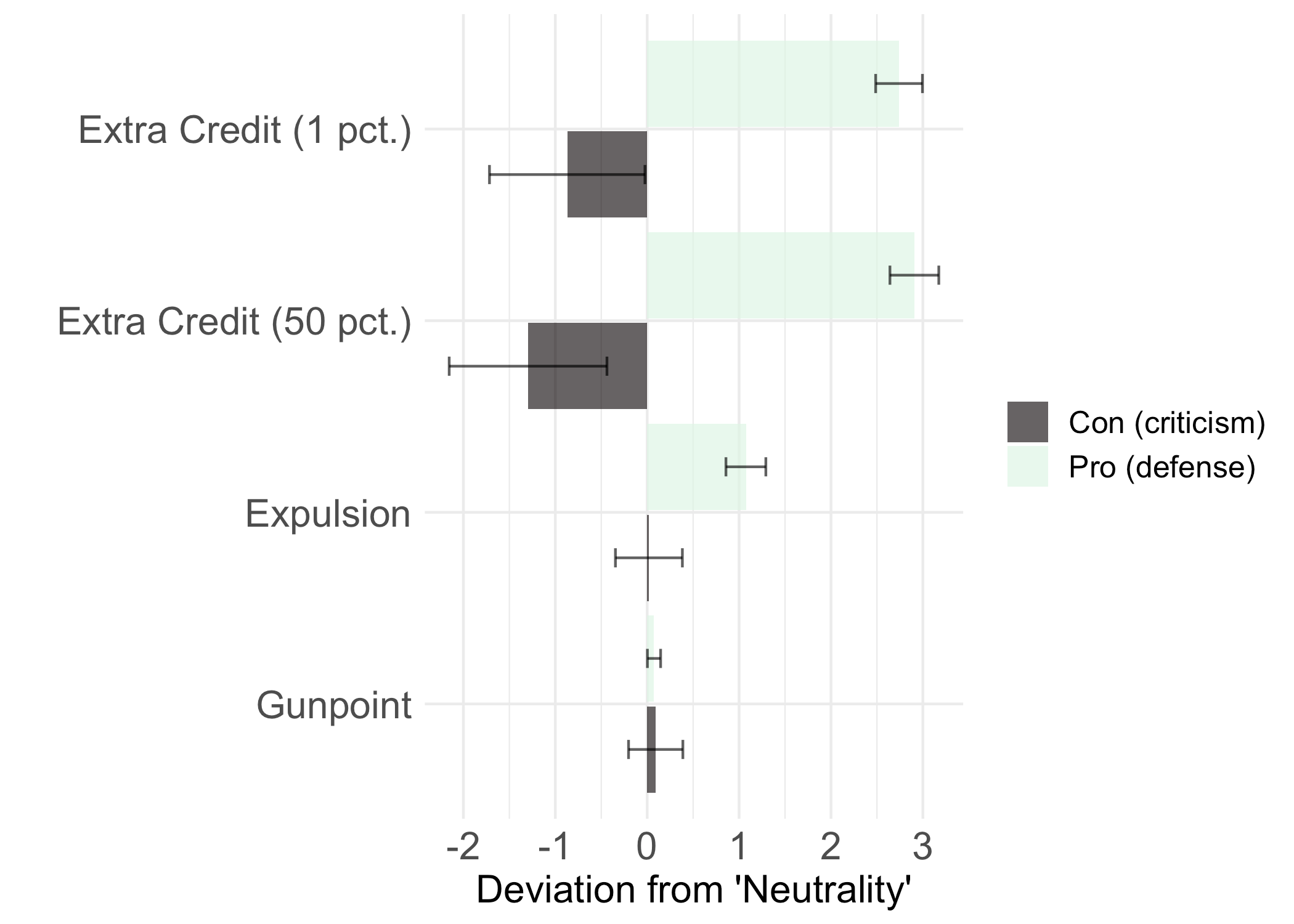
But if we look at the other motivation conditions—being threatened with expulsion or especially being held at gunpoint—we see that GPT-4 assumes much less about the person’s underlying attitude. In the gunpoint condition, GPT-4 doesn’t infer positive attitudes from “Pro” essays and it doesn’t infer negative attitudes from “Con” essays. Its assumptions about a person’s beliefs are essentially neutral, i.e., collapsing back to a reasonable “prior” about a person’s belief on a topic.
This is what you’d expect if GPT-4 is “rationally” modulating its inferences as a function of how strong the situational pressure is.
GPT-4 as a model organism for bounded rationality research?
I’ll be presenting these results at the upcoming Society for Judgment and Decision-Making Conference in a couple weeks. Judgment and decision-making (or “JDM”) is a new field of research for me, so I’m excited to meet other researchers in this space and also get feedback on what we’ve done so far. In my experience, peer feedback is really valuable for the research process: it’s possible we’ve overlooked an obvious fatal flaw in our research, and it’s also possible there are really interesting next steps we haven’t thought of.
In terms of what we have thought of, our goal is to replicate this study with a larger set of topics and a more diverse set of motivational factors, using both GPT-4 and humans. As I’ve written before, a human benchmark is critical for contextualizing any effect we observe in GPT-4.
Our other, slightly more ambitious goal is to approach this question from the perspective of bounded rationality. This means building out a more explicit model of each factor in play. We assumed (correctly, I think) that being held at gunpoint is a stronger situational pressure than being expelled from school, and that both are stronger than receiving 1% of extra credit. But how much stronger? Measuring this is hard, but one approach is simply to ask people (and GPT-4). Putting a number on situational strength allows us to model what a rational agent (sometimes called an ideal observer) would do in each situation, i.e., how much belief attribution is rational in each case. We can then compare humans and GPT-4 to this ideal observer and ask where and to what extent they deviate from what’s allegedly optimal—which gives us deeper insight into the potential mechanisms underpinning their behavior.
This, broadly, is the so-called resource-rational research program. Researchers have applied it to human subjects for decades now, with reasonable success. And so the gamble I’m interested in making is: can such a research program also provide a useful lens for systems like GPT-4? For the sake of deepening our understanding of LLMs, my hope is that the answer is yes.
This was important for our primary research question of whether this information would then lead to inferences about the underlying attitude of the writer.
A 1-10 scale was chosen to align with previous literature on the topic.