Modifying readability, pt. 2: the human study
Validating LLM-modified text excerpts with human ratings.

In February, paying subscribers of the Counterfactual voted for a project exploring whether large language models (LLMs) can modify the readability of texts. This is a multi-part project that I’ll be reporting on in multiple stages; this is part 2, which involves collecting data from human participants. Note that I’ve now written multiple posts about readability, so my introduction is going to be as concise as possible.
The construct of “readability” comes from the observation that some things are easier to read than others (e.g., Finnegans Wake vs. Amelia Bedelia). For decades, Natural Language Processing (NLP) researchers have attempted to operationalize this construct and measure it using various formulas. More recently, the advent of Large Language Models (LLMs) has led to interest in using NLP not only to measure the readability of texts but also to modify their readability.
Last month, I tried this myself: using GPT-4 Turbo, I modified 100 text excerpts to be “easier” or “harder” to read. Then, I used a handful of those readability formulas (as well as Turbo itself) to estimate the readability of those modified texts. According to those metrics, the “easy” texts were indeed easier to read, while the “hard” ones were harder. (If you’re curious about the details, check out the original post.)
But as I wrote before, a glaring issue with this approach is that it relies on proxies for readability. It’s not even clear we know what readability is, let alone how to measure it with a formula. The one source of comfort here is that readability metrics tend to be decently well-correlated with human judgments of readability; and in fact, as I showed in a previous post, Turbo’s estimates of readability are even more correlated with human judgments than other metrics are. Still, a proxy is not the thing itself, and it’s important to validate those results with data from human participants.
Methods: what I did
The high-level
I wanted to know the answer to a very specific question: do human judges actually perceive the “easy” texts as easier than the “hard” ones (and are both of these perceived as differentially readable than the original excerpts)?
From one perspective, this question is pretty straightforward and suggests a straightforward method: show each text excerpt to a bunch of humans, and ask each human judge to rate how readable it is on a scale. Their responses could then be analyzed using a statistical test to determine whether “easy” texts are rated as more readable than the originals, and whether the originals are rated as more readable than the “hard” texts. This is, more or less, exactly what I did.
The details
Recall that I started out with 100 text excerpts from the CLEAR corpus. Each of these had two additional “versions”, modified by Turbo to be easier and harder—a total of 300 passages. 300 passages is too many for any given person to rate, and I also didn’t want people to see multiple versions of the same passage. Thus, I divided these 300 passages among 6 lists using something called a “Latin square” design. Each list had 50 passages, and no list had multiple versions of the same item. Also, each list of 50 items had roughly the same number of “easy”, “hard”, and “original” items.
Then, I designed an experiment using the Gorilla online platform. In the task itself, participants read each passage on a separate browser page, and were (on the same browser page on which the passage was presented) instructed to rate the passage on a scale from 1 (very challenging to understand) to 5 (very easy to understand). Each participant was randomly assigned to one of those six lists, and read a total of 50 passages; they progressed between passages using a “next” button.
I used the Prolific recruiting platform to recruit participants to the study. My goal was that about 10 participants would see each item, which meant that I wanted at least 60 participants (6 lists x 10 participants per list = 60 participants). Because I anticipated needing to exclude some participants from the final analysis, I decided to recruit 70 participants to be on the safe side.
Because each participant rated about 16-17 “original” passages, I could calculate the correlation between their ratings for these passages and the “gold standard” ratings from the CLEAR corpus. I excluded participants whose correlation with the gold standard was below an r of 0.1. In the end, this left me with 59 participants.
(If you’re curious, you can also find the pre-registration for this study on the Open Science Framework.)
The caveats
I also want to note, up front, that an alternative perspective might hold that this research question is actually quite complicated. What exactly is “readability”? How much of what we mean by “readability” depends on our audience or on our goal? Does “readability” mean the same thing when we’re discussing educational texts vs. a training manual? And importantly: can any of these things really be measured on a unidimensional scale?
I think those are all important questions. However, I’m somewhat of a pragmatist by nature, so my tendency is to try to figure out the least-bad solution to answering a question. If none of the solutions are very good, I scope my claims accordingly.
In this case, that means we’ll need to keep in mind that our measure of readability is clearly imperfect. Different participants might interpret “readable” in different ways, and the ways in which they interpret it might not be exactly what I mean by “readable”. That, in turn, limits our ability to draw strong conclusions from any of the results. For example, I would caution against trying to apply any of the findings I mention below, e.g., to curriculum design, building training manuals, measuring the accessibility of web pages, and so on. I view these results—as I view many experiments—as a kind of proof-of-concept, and ideally they’d be supplemented with other measures, including more qualitative approaches.
With all that in mind, let’s take a look at what I found.
Results: what I found
The good news is that the results are numerically very straightforward to interpret.
Specifically, texts that were modified to be “Easier” to read were, indeed, rated as more readable on average (M = 4.48, SD1 = 0.8) than the original texts (M = 3.97, SD = 1.13), which were rated as more readable on average than the “Harder” texts (M = 2.5, SD = 1.25). This is illustrated in both panels of the figure below: the top illustrates the mean (and standard deviation) for each condition, while the bottom shows the raw frequency distribution for each condition.
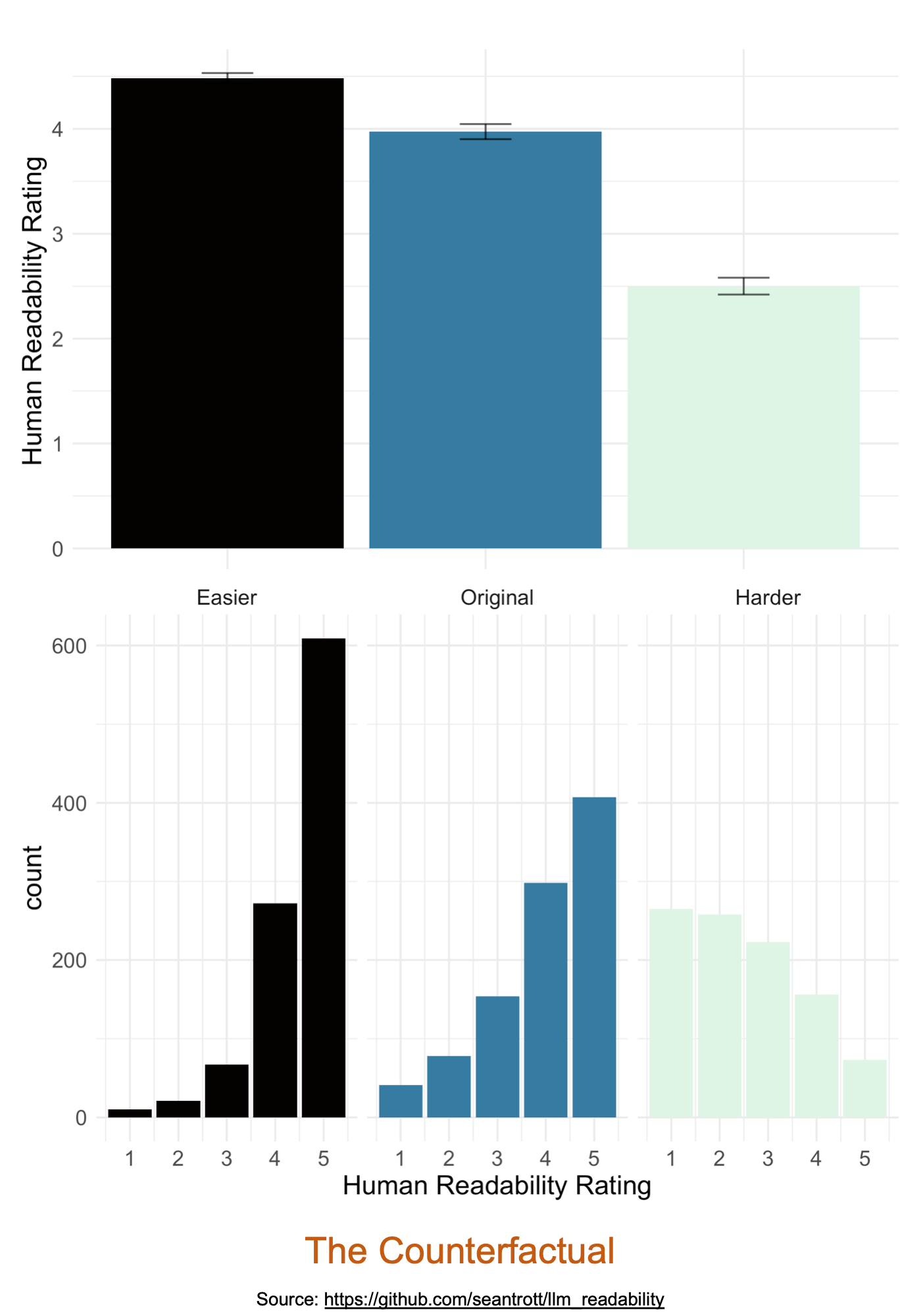
One thing I like about the bottom panel in particular is that it allows us to see the details of what’s going on in each condition. In the “Easier” condition, we see that “5” is the most common rating, with a sharp left skew (i.e., very few “1” ratings). Interestingly, the “Original” condition looks somewhat like a less skewed version of the “Easier” condition, almost as if the “Easier” condition exaggerated the pre-existing skew. The “Harder” condition, by contrast, is inverted, with most of the ratings clustered around “1” or “2”—and a slight right-skew.
As you might expect from these visualizations, statistical tests revealed significant differences in the ratings assigned to texts from each condition. That is, it’s unlikely we’d observe measured differences this large in a world where the true difference really was zero. (Note: that’s not a guarantee that these results are “real”!)
The answer to my main question, then, appears to be yes: Turbo’s modifications consistently elicited human judgments in the right direction (i.e., more readable for “Easier” texts, and less readable for “Harder” texts). As I noted in the previous section, that’s a statement about the measured readability; “readability” is a complex construct and may not be captured by this measure.
I also conducted some exploratory analyses.
Given that I had formula-based ratings for each of the texts, I wanted to know how well each of those predicted human judgments. I built a big correlation matrix, showing the absolute value of the Pearson’s correlation between each readability metric and human ratings.2 As you can see below, all of the metrics were reasonably predictive of human ratings, ranging from 0.51 (for the ARI metric) to 0.64 (for GPT-4 Turbo’s ratings). However, the metrics were all much more predictive of each other. Focusing on Turbo’s ratings specifically, it was more correlated with the other readability metrics (0.76 to 0.88) than it was with human judgments (0.64).

This is exploratory—meaning I didn’t pre-register the analysis ahead of time—but I think the results are interesting. They suggest that even though the metrics are semi-reliable proxies for human ratings, there’s something potentially different (or perhaps simply more variable) about what human ratings measure that none of them really capture.
What we learned
My goal was to validate whether last month’s results held up when using human ratings.
Here’s a quick recap of what that process involved, including last month’s report:
Using a random subset of 100 texts from the CLEAR corpus, I used GPT-4 Turbo to produce an “easy” version and a “hard” version of each text.
I used Turbo (and other readability metrics) to assess the readability of those texts.
I also recruited human participants to judge the readability of those texts on a scale from 1 (very challenging to understand) to 5 (very easy to understand).
According to the readability metrics and the human ratings, the modifications “worked” insofar as easier texts were rated as easier, and harder texts were rated as harder.
The readability metrics were all correlated with human ratings, but were more correlated with each other than they were with the human ratings.
Altogether, this suggests that GPT-4 Turbo is pretty good at modifying texts in ways that make human participants rate them as easier or harder to read. Because this study used human ratings, it addresses at least one concern with last month’s report: namely, that the readability metrics don’t reliably capture what humans perceive as more or less readable.
But construct validity is still—as it always is—a concern. For example, a skeptic looking at these results might observe that perhaps people are essentially “over-fitting” to what the metrics themselves are designed to measure (vocabulary choice, syntactic complexity, and so on). That doesn’t mean the human ratings are useless, but it does mean that there’s still some ambiguity about whether they capture the breadth of what we mean by “readability”. An alternative approach might operationalize “readability” in terms of a comprehension test—how well does someone respond to questions about the content of a text passage? Of course, that assumes the point of reading something is to extract information about it, but lots of people (including me) read things because we find reading enjoyable, which suggests that the “readability” of a text ought to factor in how much pleasure people find in reading it. And crucially, those dimensions probably matter to different degrees depending on whether you’re building a training manual or selecting texts for an elementary school curriculum!
A separate concern is that even if the “easier” texts are in fact more readable, they might also be less informative. That’s yet another reason for caution when it comes to trying to apply this research.
With all these caveats, one might wonder what the purpose of conducting this kind of research is.
I think the answer sort of depends on one’s philosophy of how empirical research is supposed to work and what it’s for. But in my view, no single research study can really “settle the score” on a given research question—let alone provide reliable real-world advice. Instead, these studies can be seen as a proof of concept that LLMs may be useful when it comes to measuring and modifying text readability, at least in terms of how readability is typically operationalized. Because people seem interested in using LLMs in this way, I think a (relatively) rigorous proof-of-concept is an important contribution to the discourse.
Determining whether LLMs actually ought to be used would require additional studies, some of which should probably move away from a quantitative “scale” of readability and towards other measures, such as comprehension questions or even a free response question about why exactly someone found something easy or difficulty to read. And, of course, we’d want a much deeper discussion of what “readability” actually is and how what we mean by “readability” might vary across different groups of people with different goals in mind—not to mention why we want to measure and modify “readability” in the first place!
Related posts:
“SD” stands for “standard deviation”.
I used absolute value because some metrics go in opposite directions, and I wanted to make these numbers more interpretable at face value.
Interesting research, Sean. The question you raise about the mid-level correlations between human and algorithmic measurements of readability in contrast to the higher-level r’s between the algorithmic measurements squares with mainstream readability research in the field of reading. But expert human raters exceed algorithms in predictive value. Huey introduced the first serious study of readability based on quantitative methods in 1935. Since then such methods have been reified and then ultimately discredited, and current methods used to level the demands of texts for use, say, on the ACT tests are of a structured qualitative protocol with more mid-level constructs (experiential demands, prior academic participation cued in text, etc.) than micro-constructs like vocabulary and sentence structure. Pragmatically, the assessors are looking for passages that do a good job of predicting future success in college. Although tests still make use of multiple-choice technology for test items with a loss of validity, they make up for it in better selection of passages representing a range of genres and stances. Commercial publishers of k-12 material may still rely on algorithms like SMOG etc. but there is after all some relationship between average word length and cognitive demands of text. Still, for pragmatic intentions the best reading science suggests weaknesses in quantitative methods which can be improved through expert intersubjective human judgment. It’s very interesting that your raters agreed as much as they did. That in itself is evidence that humans tend to read texts in similar ways. I’m not sure what it means for a bot to rewrite a text at a lower or higher level—in what larger context were the bots instructed to rate the passages? Hard for whom? For an abstract child at a certain grade level? To reduce the average sentence length by a particular percentage?