Vision-language models (VLMs), explained (pt. 2)
The view from Cognitive Science.

Vision-language models (VLMs) are trained to associate strings of text with images. Thus, unlike language models trained on text alone, VLMs don’t just learn that the word “apple” co-occurs with words like “red” and “delicious”—they learn to identify which images might be described as containing an “apple”. Conceptually, this is a big advance: it’s a step towards grounding language models with non-linguistic sources of information (like vision).
Last year, I wrote an overview of how these VLMs work, covering topics like the range of architectures and training protocols. This post will approach VLMs from the perspective of LLM-ology (or perhaps “VLM-ology”), discussing their capabilities and limitations, as well as the internal representations and mechanisms they develop throughout training. My goal is for this post to be independent from the explainer, but it might still help to read the explainer first for background information.
A brief caveat: as in the original overview, I’ll be focusing on work done with open-source VLMs (i.e., systems for which we know a decent amount about the training process and architecture). I might reference work done with state-of-the-art multimodal models (like GPT-4o), but because there’s less transparency with those models, it’s harder to draw the kinds of inferences we tend to be interested in with scientific work. In this case, some of the VLMs I’ll discuss might perform poorly on tasks for which state-of-the-art models (again, like GPT-4o) would excel on. Consequently, we should be cautious about extrapolating from the results of these studies to the models people are more familiar with, unless those models are the ones under investigation.1
A separate (but related) caveat is that as is typical with work on LLM-ology, this is very much an evolving space: LLMs and VLMs are a “moving target” and it’s hard to know which findings will generalize to future, better models.
These limitations are part of why it’s taken a while to work on this review: I want the content to be actually informative and not obsolete by the time I press “Publish”. But as long as we keep these caveats in mind, my hope is that this post will give readers a good sense of what kinds of research in Cognitive Science and Artificial Intelligence is being done with VLMs and how researchers learn what they want to know.
Why grounding matters
Unlike text-only language models, humans don’t learn about the world purely through exposure to sequences of words. We’re physical beings that move around in space, experiencing the world through various sensory modalities (e.g., vision, touch, etc.) and even acting on it with different effectors (e.g., our hands, feet, etc.). This sensorimotor grounding is probably crucial for building mental models of the world around us, and it might also be important for reasoning and even learning language.
Within Cognitive Science, researchers have long discussed the so-called “symbol grounding problem”, made most famous in Stevan Harnad’s 1990 paper.2 The core argument is that symbols (like words) derive their meaning in large part from reference to some external source, such as our experience of the physical world. Of course, symbols can also mean things in relation to other symbols: that’s a central part of distributional semantics, a foundation of modern LLMs—you can learn a lot about a word’s meaning by analyzing which words it co-occurs with. But many people (including myself) have the intuition that grounding matters too: my sense of what the word “cat” means is informed by the various cats I’ve interacted with throughout my life. (This is why most contemporary theories of word meaning assume some role from both distributional and experiential input.)
Beyond knowing the meaning of symbols, grounding is probably helpful for reasoning about real-world situations. Through experience in the world, we gain physical intuition, like that a vase will fall (and probably break) when it falls off a table or that a ball will roll down a slope. The idea that grounding can help reasoning was the motivation behind a 2022 paper from a team at Google, which augmented text-only language models with an API to a physics engine. Sure enough, the resulting system (language model + physics engine) was better at answering questions involving physical reasoning than the text-only language model.
Again, many of these associations can probably be learned through large text corpora. Indeed, a dedicated team of researchers could likely fine-tune a text-only language model to achieve comparable performance to the model hooked up with a physics engine—but as I’ve argued before, grounding might lead to more robust, generalizable representations of the world:
One way I think about the utility of multimodal information is as offering a kind of stability to our representations. If you only have one source of information about a particular stimulus, the more prone you are to catastrophic failure––i.e., if that input stream fails in some way, your representation of that stimulus is completely distorted. But multiple sources of information about the world offer redundancy, which could prevent that kind of catastrophic failure. Moreover, the information content of different modalities is also inter-correlated, which means that we can sometimes fill in the gaps of one input using information from another input.
Moreover, it’s pretty clear that humans learn about the world in part through grounded experience, so it seems like a reasonable bet that it could help language models too.
Of course, vision-language models represent a very narrow kind of grounding. For one, their only source of grounded “experience” is vision—which neglects the other important sensory modalities accessible to humans. Perhaps more importantly, they’re passive: with some exceptions (like Google’s PaLM-E), VLMs are usually trained to associate strings of text with images—they don’t actively explore an environment or seek out information, which might be an important part of discovering how the world works.3 But they’re a start.
VLMs and spatial reasoning
Spatial reasoning is the ability to reason about objects (or entities) in space. This could include describing orientations (“what direction is this object facing?”), performing mental operations over object positions (e.g., mental rotations), identifying the relationship between objects (“in this image, is the picture frame above or below the table?”), figuring out directions (“what’s the shortest path from A to B?”), and more.
One early(ish) study in this space asked about the ability of VLMs to understand spatial relations, i.e., the kind often expressed via prepositional phrases (“A is on top of B”). The authors created a custom corpus of images (“What’sUp”) depicting various spatial relationships that also controlled for the objects and entities involved. They then assessed a range of VLMs by asking them to select the correct caption for each image from a set of possible labels. For example, a picture might depict a mug under a table, and a VLM would have to select among: “a mug on a table”, “a mug under a table”, “a mug to the left of a table”, and “a mug to the right of a table”. The VLMs were on the smaller side (<1B parameters), though represented the state of the art for open models at the time. The authors used two different baselines: humans performing the same task (average performance was 100%); and the same models performing a similar task, but with colors instead of spatial concepts (average performance of the models here was again 100%).
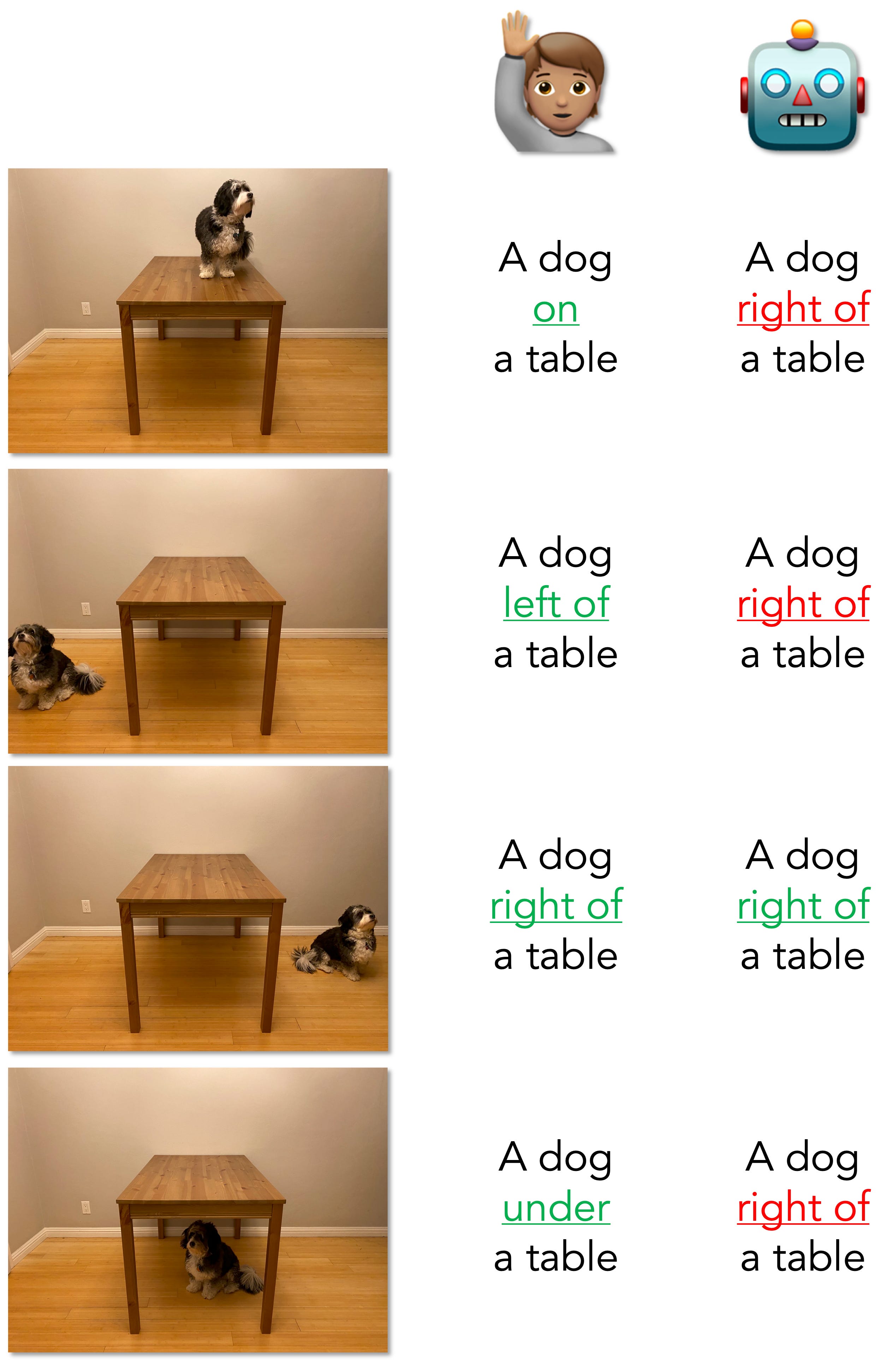
All the VLMs tested performed quite poorly on the What’sUp benchmark. The best-performing model was BLIP-VQA, a model produced by SalesForce that was fine-tuned on a visual question-answering (VQA) task; this model achieved 47.8%, which was better than chance (25%) but well below both baselines. That is, humans did very well on this task, indicating that the poor performance of VLMs is not simply about the task being impossible; and the same models did very well on a task involving color instead of spatial concepts, indicating that it’s not about auxiliary task demands—there really does seem to be something hard about spatial reasoning for these models.
The authors also performed some follow-up studies on select models. In one, they adapted the classic “analogy” tasks from NLP, e.g., king - man + woman = queen. Here, they used spatial concepts:
We now evaluate whether I(mug on table) − I(mug under table) + I(bowl under table) is the closest to I(bowl on table), compared to I(bowl left/right/under table), where I(·) is the image representation.
The idea is that if the model has a stable representation of the depicted spatial concept (on vs. under) that’s also distinct from the objects (e.g., mug), then such an operation should yield a representation that combines the spatial concept from one image (mug on table) with the target object in another image (bowl under table). As a control task, they did the same thing with color.
The models performed even worse on the spatial reasoning task using this approach (9%) compared to the original approach (31%). Moreover, they performed substantially better on the “color analogy” task (61%), illustrating that (again) it’s not simply about the metric being a poor operationalization of their abilities.
A natural question that arises here is why the VLMs all perform so poorly on problems involving spatial reasoning. The authors identified a few candidate explanations. First, captions with prepositions in VLM training data are very rare (~0.2%), possibly because certain spatial relations are obvious or may not seem important to what the caption writer is trying to convey. Second, prepositions are notoriously ambiguous, and often depend on perspective: as they point out, “in front of” could mean closer to the camera’s perspective or ahead of a person facing a certain direction.4 And third, learning how to represent prepositions may actually be unnecessary for satisfying the underlying training objective, i.e., identifying the correct caption for an image:
Given the combinatorial space of all possible sentences, it is unlikely that the exact same description would apply to two images in a batch with the exception of a specific preposition. Furthermore, some preposition-object combinations are much more common, e.g., “dog under table" vs. “dog on table". Thus, we hypothesize that the model can perform well on the contrastive training objective despite ignoring spatial relationships between objects in the image.
If this is true, VLMs may be able to get by on their training simply by learning to represent the relevant objects and entities in an image—not how they relate to each other.
Other work has made similar arguments about VLMs, though more focused on the way they represent text. For instance, this 2022 paper argued that VLMs sometimes treat text like a “bag-of-words”, i.e., disregarding features such as word order. VLMs may disregard this information because it’s possible to pass the benchmarks without it. Indeed, the very training objective of many of these models—contrastive learning—tends to focus on matching images with their text captions, and the datasets simply don’t contain enough examples where successful discrimination or matching depends upon correctly distinguishing captions with the same words in different order.
The authors of that 2022 paper go on to suggest a potential solution to the “bag-of-words” problem, namely introducing more hard negatives into the dataset. Concretely, this means introducing more mismatching text/image with captions that closely mirror a matching text/image pair. They write:
For each image-caption pair, we generate a negative caption by swapping different linguistic elements: noun phrases, nouns, adjectives, adverbs, verb phrases. For example, the caption “The horse is eating the grass and the zebra is drinking the water” either becomes “The zebra is eating the grass and the horse is drinking the water” (noun swapping) or “The horse is drinking the grass and the zebra is eating the water” (verb phrase swapping).
The authors find that fine-tuning CLIP (a VLM) on such an adversarial dataset leads to substantial performance gains, particularly on tasks that depend on understanding subtle differences in word order.
Of course, the examples in that paper focused more on correcting the tendency of VLMs to treat text as a “bag-of-words”, not necessarily their related tendency to treat images as a “bag-of-pixels”. It’s the latter issue that likely leads to the poor spatial reasoning observed in the What’sUp paper.
More recent work has found evidence consistent with the hypothesis that some VLMs (the authors test LLaVa 1.75B) disregard spatial information: in fact, randomly shuffling the order of the position embeddings for the vision encoder led to very little deterioration in performance—suggesting that the model’s behavior is not dependent on tracking relative position. The authors suggest that some of this is caused by how embeddings are normed within the model. Without going into the mathematical details, the gist is that the standard order of operations tends to privilege “global semantic information” over positional information, i.e., which objects or entities are in an image—but not where they are. The authors systematically modify these operations, which actually has the effect of reemphasizing spatial information and improving model performance on tasks requiring spatial reasoning.
Together, this points to a few tentative conclusions. First, many VLMs struggle with what appear to be simple spatial reasoning tasks—despite performing well on other image retrieval tasks. This deficit could be caused both by poor training incentives to learn spatial information and by specific mathematical operations in each transformer block. Encouragingly, fixing both (or either) of these issues does seem to improve things a bit, though (as always) it’s unclear how reliable or generalizable those improvements are.5
Counting
Counting involves enumerating the number of items in a scene. It’s related to, but distinct from, approximate quantity detection, i.e., determining that an image of 400 dots probably has more dots than an image of 100 dots.6
As I’ve written about before, VLMs often don’t do very well on tasks requiring exact counting, even state-of-the-art VLMs like GPT-4o. One recent paper tested this in a clever way by modifying images of objects that are typically associated with specific numbers. For example, a horse typically has four legs while a person typically has two legs. Similarly, a chessboard typically has eight rows.
Presented with an image of a standard chessboard, a state-of-the-art VLM might generally accurately report that it does, in fact, have eight rows. But when the authors modified the image to instead have a different number of rows, that same VLM often answered incorrectly—usually resorting to the default number. In other words, VLMs seem to have “memorized” certain facts about objects and entities (e.g., that horses have four legs)7, and use that information to respond to questions asking them to count. The authors tested five state-of-the-art VLMs, and found that accuracy dropped to an average of ~17.5% on the modified images; moreover, instructing the VLMs to “double-check” their results or “rely only on the image” improved accuracy by only about ~2% on average. In other words, the models are strongly anchored to their default expectations about how many legs a horse or a person has.
One model that does perform relatively well on counting tasks is Molmo, which I did a “deep dive” on here. Notably, Molmo was trained in part using a “pointing” dataset. The authors wrote (bolding mine):
We collected pointing data that achieves three goals: (1) enables the model to point to anything described by text, (2) enables the model to count by pointing, and (3) enables the model to use pointing as a natural form of visual explanation when answering questions.
I think this is potentially promising solution to the challenge of teaching VLMs to count. Asking a VLM to directly estimate the number of items in an image is a hard task: humans are not good at estimating exact numbers directly either, except for numbers that are small enough to be subitizable. Rather, counting is an enactive task. We often things by pointing at them and in some cases vocalizing or sub-vocalizing (“one, two, three…”). Molmo can thus combine its ability to point with an extended chain-of-thought routine that allows us to enumerate all the items in an image with relatively high accuracy. In my view, this makes it a really interesting example of an LLM-equipped software tool.
Another angle I’m interested in with respect to VLMs and counting is the connection between language and number concepts. There’s a prominent idea in Cognitive Science that words help to stabilize our conceptual representations: instead of merely representing the concept DOG as a disparate cloud of perceptual associations (i.e., from every dog we’ve encountered), we can bind those associations together with the common label “dog”. According to this view, language acts as a kind of cognitive technology (or “neuroenhancement”) that helps scaffold our network of concepts. This could be especially important for number, which is, of course, symbolic concept. Does exposure to language help VLMs stabilize their representations of quantity—i.e., above and beyond that of vision-only transformers (ViTs)?
Recently, I tested this idea with some collaborators (Pam Rivière, Cameron Jones, and Oisín Parkinson-Coombs). Using abstract stimuli of dot arrays, we measured the sensitivity of multiple VLMs (trained on both text and images) and ViTs (trained only on images) to quantity differences. That is, given two pictures of a bunch of dots, are VLM representations more sensitive to the quantity differences between those pictures than ViT representations? In this preliminary work, the answer appears to be “yes”: while both types of models displayed some sensitivity, VLM representations were more effective at capturing differences than were ViT representations. That said, the effect was pretty small, and there were other, uncontrolled differences between the VLMs and ViTs we compared. We’re planning to follow up on this work by testing a broader range of models and potentially even training our own—but this initial study will be presented (by Pam) at this summer’s Cognitive Science conference in San Francisco.
Mechanistic interpretability for VLMs
Most of the work I’ve described so far characterizes the behavior of VLMs. But there is a growing body of research applying mechanistic interpretability techniques to VLMs to figure out how they work “under the hood”. Because these models are so new, the space is ripe for exploration. How exactly do VLMs represent their inputs, and how do they learn to integrate them across modalities? How similar are the putative circuits that develop in VLMs to those already identified in LLMs? Are there novel mechanisms emerge in VLMs that don’t show up in LLMs or vision-only models?
One recent preprint led by Zhi Zhang attempted to address the question of multimodal integration: when and how do VLMs combine information about language and vision? The authors focused on a specific kind of task called visual question answering (VQA), in which a VLM is asked to produce an answer in response to an image and a question about that image. These questions could range from asking about the spatial relationships in the image (“is the door to the left or right of the table?”) to the properties of specific objects (“what material is the door made of?”).
Following similar work on interpreting LLM, the authors applied an attention knockout procedure. The conceptual idea of a “knockout” (or ablation) is relatively straightforward: if a model component is functionally involved in a computation, then “knocking out” that component (e.g., setting it to zero or otherwise inhibiting it) should causally affect model behavior. In this case, the authors first identified attention weights that appeared to direct attention from image tokens to text tokens and vice versa. They write:
Intuitively, when blocking the attention edge connecting two hidden representations corresponding to different positions of the input sequence leads to a significant deterioration in model performance, it suggests that there exists functionally important information transfer between these two representations. (pg. 4).
The results point to a few conclusions. First, early layers appear to focus on copying information from image tokens to the question tokens—as evidenced by the fact that blocking this flow in early layers substantially impacts performance. One way to think about this process is that the model is creating a multimodal representation, blending information about the image input and the question input. Second, later layers focus on generating the answer to the question dependent on that new multimodal representation.8 While this work is preliminary—and it’s impossible to know whether it generalizes to other VLMs—it does suggest that systematic application of interpretability techniques can give us insights about how information flows through multimodal networks.
Another, even more recent preprint (from July 2025) out of Ellie Pavlick’s lab again focused on how VLMs integrate information from distinct modalities—but with an emphasis on situations where that information conflicts. For example, a VLM might be presented with text describing “a picture of a dog” when the image is actually of a cat. They find that when VLMs are asked to report on the information from one of the modalities (“what does the caption say?” or “what is in the image?”), VLMs tend to report a “favored modality”, e.g., reporting on the content of the image regardless of what the caption says. Favored modality appeared to differ by model, and for some models it even depended on the dataset: Qwen2.5-VL tended to report on the caption for the CIFAR datasets, but showed a slight bias towards reporting on the image for the ImageNet dataset.
Having established the behavior of VLMs in these situations, the authors then sought to identify the mechanisms underpinning this behavior. They explored a few different hypotheses, including the possibility that VLMs might simply fail to encode different modalities as distinct (this hypothesis was falsified) or the possibility that VLMs were incapable of detecting inconsistencies between figures and captions in the first place (this was also hypothesis). Instead, their results pointed to a third hypothesis: namely, that for a given VLM, certain modalities are represented in a more salient way within the model’s embedding space.9 Moreover, the extent to which a given modality (e.g., vision) was favored over the other (e.g., language) was directly correlated with the model’s error rate on the behavioral task when those modalities came into conflict.
Where do these differences in representational salience come from? To address this question, the authors systematically intervened on specific attention heads and asked how this affected both the salience of different modalities and also the model’s output behavior. This revealed two distinct “types” of attention heads: modality-agnostic router heads, which amplify the salience of the requested modality (e.g., making language more salient if the question asks about the caption); and modality-specific promotion heads, which consistently favor a specific modality (e.g., vision) regardless of what question was asked.
Given that performant VLMs are relatively new, mechanistic interpretability for VLMs is still in its infancy. But as with interpretability with LLMs, the ease of extracting hidden states and intervening on those states makes this a much more tractable challenge than analogous questions one might ask of human cognition. To my mind, some of the biggest problems are epistemological: what are the right questions to ask, what might an “answer” look like, and to which systems might that answer generalize?
VLMs and psychometric predictive power
Cognitive scientists are also turning to VLMs to ask how well they approximate (or even predict) human behavior on psychology tasks. This research can inform two related questions. First, do VLMs acquire human-like conceptual representations? And second, to what extent can we account for human conceptual representations via the kinds of mechanisms that VLMs use—at least in principle? Thus, this approach continues what I’ve previously called the “LLMs as model organisms” approach to Cognitive Science, albeit using VLMs. We might also call it the “psychometric predictive power” (PPP) approach.
One strategy here is to identify some human-generated dependent variable of interest. For example, many researchers are interested in explaining patterns of brain activity (e.g., as recorded by fMRI) in response to linguistic or visual stimuli. There’s already good evidence (e.g., Schrimpf et al., 2021) that variance in brain activity can be accounted for in part using embeddings extracted from a “pure” language model, i.e., a system trained on text alone. You can think of this as a kind of regression problem: given a set of sentences, researchers train a regression model to predict human brain activity (i.e., voxel-wise activations recorded by fMRI) from contextualized embeddings (i.e., extracted from an LLM). The accuracy of such a regression model can be compared to a random baseline (e.g., random embeddings) or to an “inter-human” ceiling: a measure of how well you can predict one person’s brain responses to stimuli from another person’s brain responses to those same stimuli.
More recently, researchers have extended this approach to include VLMs as well. This preprint (Bavaresco et al., 2024) analyzed fMRI responses to individual sentences (e.g., “The bird flew around the cage”), some of which were also presented with an image context (e.g., a picture of a bird). They compared the predictive power of “pure” LLMs (trained on text-alone) to VLMs exposed to images as well. When predicting brain responses to isolated sentences, they found mixed results: VLMs excelled at predicting responses in canonical left-hemisphere language areas, but in right-hemisphere language areas, there were no significant differences between the best-performing LLMs or VLMs. However, when predicting human responses to sentences and images presented together, the VLMs clearly out-performed the text-only models:
…across all three brain networks are that all VLMs are statistically significantly more brain-aligned than their unimodal counterparts (pg. 15).
This latter result isn’t necessarily surprising: it makes sense that a model trained on both images and text would better account for human responses to image/text pairs than a model trained on text alone. More compelling is the fact that in some brain regions, VLMs out-performed text-only models even when predicting responses to text alone. This is consistent with (but obviously doesn’t prove) the idea that humans are activating grounded representations even when processing purely linguistic input.
At the same time, this conclusion is complicated by more recent work from the same authors predicting a different fMRI dataset (responses to individual words). In this study, the authors found that text-only models actually out-performed VLMs on average. The best performance was achieved by semantic vectors derived from explicit human annotation: this dataset, called Exp48, contains judgments about a number of semantic properties including visual properties (brightness, size, motion, etc.), somatic properties (touch, weight, temperature, etc.), social properties (self, human, etc.), and more. Despite the amount of work that goes into training LLMs and VLMs, it’s striking that they are still out-performed by what amounts to well-chosen human judgments.
Another strategy is to replicate Psycholinguistic studies originally designed for humans on VLMs, with the goal of both accounting for human behavior and better understanding how VLMs work. This was the basic idea behind a paper I published last year in Computational Linguistics with Cameron Jones and Ben Bergen, in which we adapted five experiments designed to test the theory of embodied simulation. In each study, humans read and made judgments about a series of sentences, each of which implied (but did not directly state) something about the situation. For example, “The ranger saw the eagle in the nest” implies that the eagle probably has its wings folded, while “The ranger saw the eagle in the sky” implies that the eagle probably has its wings out-stretched.
We selected stimuli from studies that, together, constituted a number of implied semantic feature, including shape, orientation, color, size, and volume (see the figure below for an illustration). In the original studies, humans read a given sentence and then saw a picture that either matched or mismatched the implied feature, at which point they were asked whether the object in the picture was mentioned in the sentence. For all the critical sentences, the correct answer was “yes”—i.e., regardless of whether the eagle’s wings were folded or out-stretched, the sentence did in fact mention an eagle. The studies also contained “filler” stimuli in which the correct answer was “no”. For the critical stimuli, subjects tended to respond more slowly when the implied semantic feature did not match across the sentence and the image. One interpretation of this result is that humans activated a grounded representation of the scene when reading the sentence, which included features that weren’t explicitly mentioned.
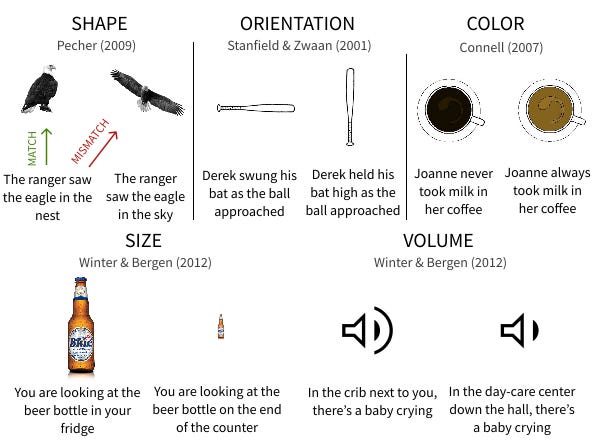
We presented the same critical image/text pairs to a series of multimodal language models, or MLMs (including some trained on audio) (and a model trained on audio as well) and measured whether their representations of matching image/text pairs were closer (i.e., in representational space) than their representations of mismatching pairs. This was true for features like shape and color, but not for size, volume, or orientation. In follow-up analyses, we found that MLMs were sensitive to explicit mentions of orientation, though still not size or volume. Together, these results point to different “bottlenecks” at play. For orientation, MLMs might simply fail to derive the right inferences from a sentence about the implied orientation of an object, even though they could match an explicit description to an image. For size and volume, they fail even with explicit descriptions, suggesting that they are simply less capable at encoding these features in general.
We also asked how well MLM outputs predicted human behavior on the same task. In some cases, the two were correlated—but MLM outputs never fully accounted for the effect of matching vs. mismatching stimuli on human behavior. That is, even where MLMs were sensitive to the experimental manipulation (e.g., for shape and color), they were much less sensitive than humans were.
What should we take away from all this?
Reviewing a research literature is never easy, especially when that research area is so new and fast-paced. To be clear, my goal above was not to provide an exhaustive survey. Even in the somewhat arbitrary categories I focused on—spatial reasoning, counting, interpretability, and predicting human behavior and brain activity—I did not provide a fully comprehensive review.
My goal, rather, was to introduce readers to some of the questions that currently lie at the intersection of technological development (vision-language models) and basic research (Cognitive Science and LLM-ology). In doing so, I hope that readers can walk away with a better sense of how researchers are assessing VLMs, as well as how to think about their limitations when they do arise.
The question of why models like GPT-4o might out-perform these smaller VLMs is a good one. It could be any number of things, such as model size (GPT-4o is bigger), training data (GPT-4o was trained on more data), or even details of the architecture itself. In some cases it might be data contamination, i.e., maybe GPT-4o was just trained on the benchmark! The problem is we really can’t say much for certain because GPT-4o is a closed-source model, so doing LLM-ology (or VLM-ology) with it is much harder.
Also, arguably, the Chinese Room thought experiment.
I expect to see more work on these “active exploration” approaches in the coming years, either in simulated or real environments.
For interested readers, there’s a large body of work in Linguistics and Psychology on different frames of reference for talking about spatial (and temporal) relations within and across languages.
Additional evidence comes from interpretability work on vision transformers (i.e., systems trained only on vision but not language). They find that fine-tuning vision transformers (ViT) to detect object relations produces systems with multiple “stages” of processing, including: first, disentangling and identifying the local objects in a scene; and second, identifying their relations. Breakdowns in either process impair overall relational detection performance.
There’s a very rich literature on exact vs. approximate numerosity detection that I won’t get into here, but if you’re interested, I’d recommend the following papers: Nuñez (2017) on whether there’s really an evolved capacity for number, and Odic & Starr (2018) on the so-called “approximate number system”.
Presumably from the “LLM” portion of the VLM, i.e., from a large text corpus.
The authors also report some other interesting findings, e.g., about the capitalization of answers:
In addition, we find that the answers are initially generated in lowercase form in middle layers and then converted to uppercase for the first letter in higher layers. (pg. 8).
My understanding is that this is roughly analogous to the findings of Qi et al. (2025), which I discussed above, with respect to information about the identity of objects in an image becoming more salient than the relative positions of those objects.
Well researched and clearly articulated article. Thanks for this piece!