
Generalizing from samples to the broader population of interest is at the heart of scientific research. It’s impossible to exhaustively survey whatever population we’re interested in, so we have to rely on small slices of that population. If those samples are randomly and representatively drawn, we can be more confident that whatever we discover in a sample might apply to the rest of the population.
But at least in Cognitive Science, our human samples are often somewhat biased, which means we have to be careful about how we draw generalizations. Of course, part of the challenge here is that we don’t always know what we don’t know. Unless you’ve systematically studied different parts of the entire population of interest—i.e., “all humans everywhere”—it’s very hard to intuit whether a finding should generalize from one group to another.
Unfortunately, the same is true for LLM-ology. Because the study of LLMs is so new, and because the landscape of LLMs changes so rapidly, we still don’t know exactly how the different factors that go into an LLM’s design—its architecture, its size, its training data—affect both its internal mechanisms and its downstream behavior.

That doesn’t mean we’re completely in the dark! Researchers are very interested in this question, and I discuss some of what they’ve found below. But we lack a systematic theory that connects those constitutive design factors to the properties and behaviors that emerge after training. This is especially true when it comes to measuring more complicated “capabilities” and characterizing the underlying representations and mechanisms subserving those capabilities, as in the field of mechanistic interpretability. The causes are both technical and sociological, and as I discuss below, the sociological challenges may end up being the harder ones to solve—but that doesn’t mean there aren’t solutions.
A theory of scaling
One clear, consistent finding is the impact of scale. Put simply, bigger language models trained on more data tend to be better at doing what they’re trained to do: predict words. All else equal, increasing the number of parameters in the model, the number of tokens in the dataset, and the compute budget will likely result in models with lower loss, which amounts to fewer prediction errors.1 Some describe these findings as “neural scaling laws”: i.e., the idea that we can make systematic predictions about model performance as a function of those three design factors—number of parameters, number of tokens, and compute budget.
Indeed, I’ve noticed evidence of scaling in my own work. In a recent preprint with Pamela Rivière and Anne Beatty-Martínez, we found that Spanish language models with more parameters produced representations that were better at predicting human judgments about the meaning of ambiguous Spanish words. No model was as good at this as individual humans were—but by and large, bigger models did do a better job. (Notably, multilingual models performed relatively poorer given their size, which might relate to the so-called “curse of multilinguality”.)
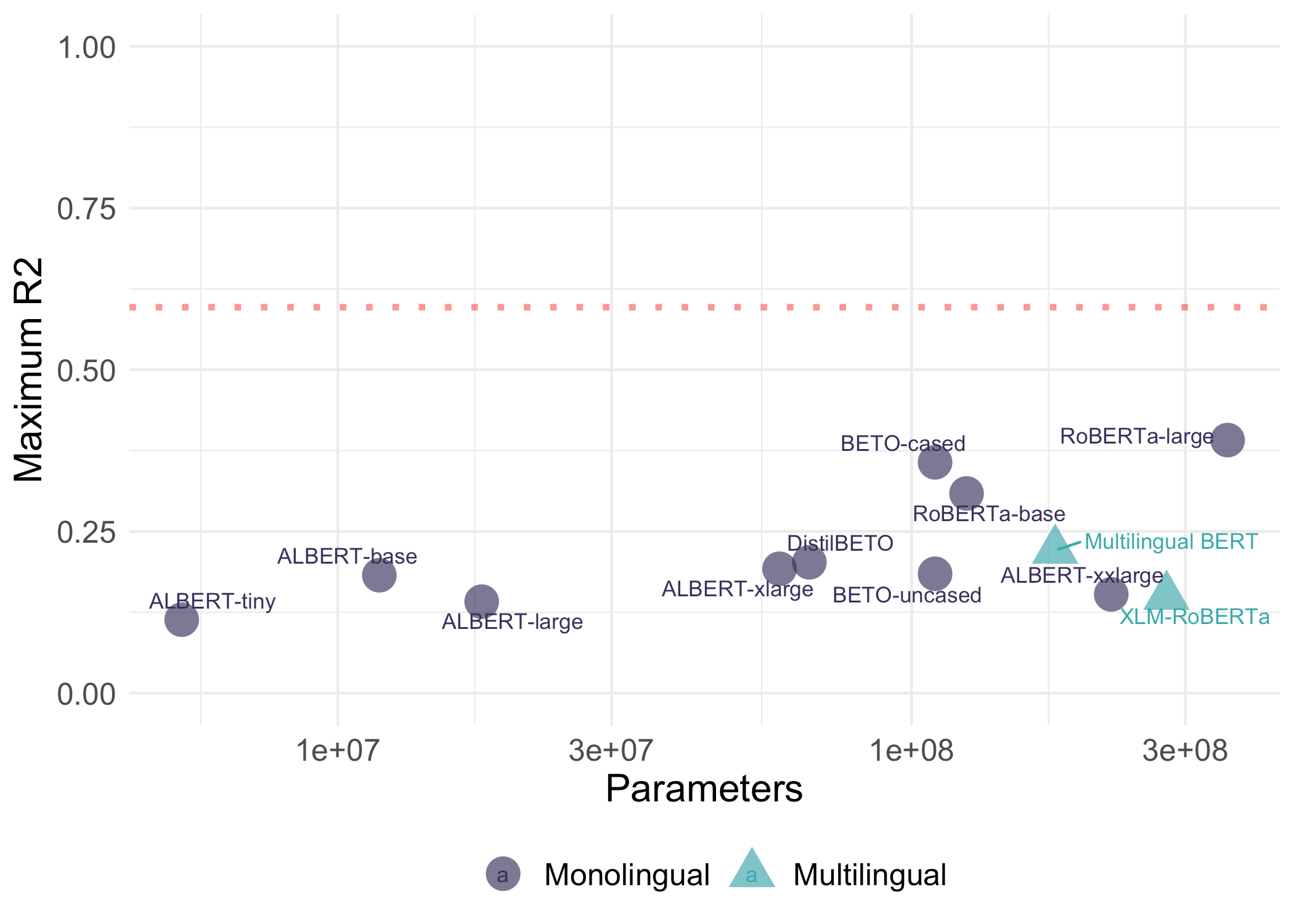
Scaling is a really powerful starting point, and I think it’s a useful null hypothesis for theory development. A good theory of LLMs should ideally explain things that these straightforward assumptions about model scale can’t explain. And when it comes to successful next-word prediction, scaling seems like it’s an important part of the equation.
Of course, a model’s ability to predict the next word is only part of what people care about. Researchers are often interested in characterizing LLM performance on more complex tasks, such as those ostensibly requiring Theory of Mind. Here, scaling still seems to matter a lot: bigger models trained on more data tend to perform better on those tasks as well. But at the same time, the quality and type of data also matters: a big part of what makes ChatGPT so conversant is that it’s been trained specifically to “chat” using reinforcement learning from human feedback (RLHF). Similarly, the performance gains for OpenAI’s o1 model are likely due in part to the use of new training procedures, not simply making a bigger model. The same goes for the rise in more efficient, more compact models: if we can build a smaller model without a drop in performance, it’s good evidence that scale isn’t the only thing that matters.
The explanatory picture is further complicated by the fact that performance on some tasks exhibits apparent discontinuities with respect to model scale—i.e., sudden “jumps” in performance—leading some to argue for the existence of so-called “emergent capabilities”. Clearly, scale matters for these models, but from a scientific perspective, it’s harder to come up with a coherent, comprehensive theory for how exactly it matters.
To wrap up: we have some idea of how certain model properties impact model behavior—scale seems to matter a lot—but there’s still much we can’t account for.
Which mechanisms generalize?
LLM-ology isn’t only interested in quantifying performance gains. A major component of LLM-ology is interpretability: studying the internal representations and mechanisms that give rise to observable LLM behaviors. A good mechanistic theory would deepen our understanding of how LLMs work, and might also help us design LLMs that are safer to use. It might even address some of the knowledge gaps I’ve mentioned above: for example, this recent work by Neel Nanda and others offers a mechanistic explanation for the emergence of particular behaviors at larger model scales.
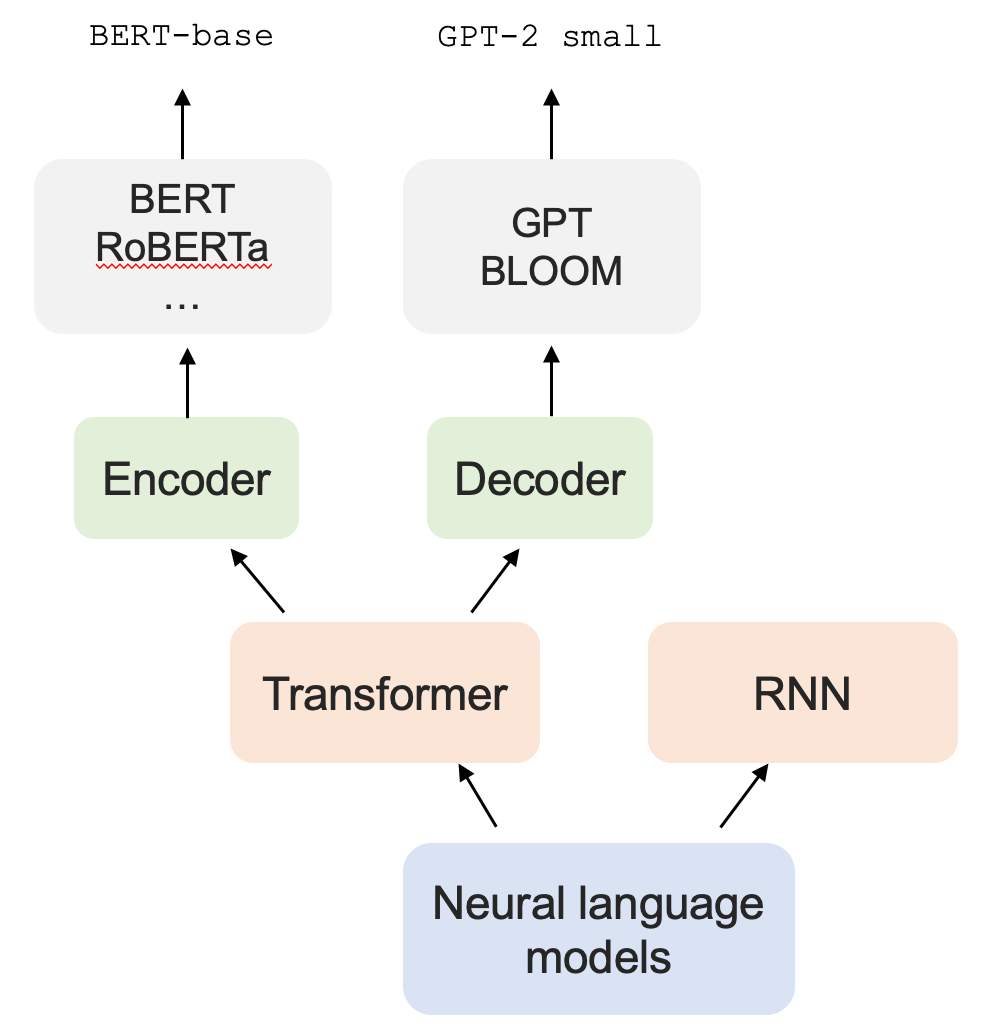
Yet mechanistic interpretability faces its own challenges with generalizability. Interpretability work is often conducted on a small set of models, or even a single model. For example, researchers might focus on uncovering mechanisms in GPT-2 small or BERT-base, both of which represent specific pre-trained models from a given model family (GPT vs. BERT, respectively). As the figure below illustrates, that model family is in turn only a subset of the families available (e.g., all encoder models or all decoder models), which in turn are a subset of all possible language model architectures (e.g., transformers vs. recurrent neural networks).
Of course, it’s entirely reasonable to focus on specific models. Mechanistic interpretability is really hard, and we have to start somewhere. But it does raise the question of whether the mechanisms we uncover in GPT-2 are also present in, say, BERT (or GPT-2 large, for that matter).
And that’s only restricting ourselves to generalization across models and model families! What about different kinds of training data? Different languages are, after all, quite different. Do the mechanisms we identify in a GPT-2 small that’s trained on English Wikipedia generalize to a GPT-2 small that’s trained on Spanish or Chinese Wikipedia? Intuitively, we might expect LLMs trained on more similar languages to exhibit more similar properties than LLMs trained on different languages. But is that true? Could we use our understanding of linguistic typology to guide our generalizations across models trained on different languages?
This comes back to a credit assignment problem. What, ultimately, is responsible for the emergence of specific circuits or behaviors in a given model? Or put another way: under what conditions—architectures, training data, tokenization strategies—would we expect those circuits or behaviors to show up?
I want to emphasize that I’m far from the first person to raise this issue. In a post called “Interpretability Dreams”, Chris Olah—a co-founder of Anthropic and pioneer of mechanistic interpretability research—references the notion of “universality” with respect to the study of vision models:
In the same way, the universality hypothesis determines what form of circuits research makes sense. If it was true in the strongest sense, one could imagine a kind of “periodic table of visual features” which we observe and catalogue across models. On the other hand, if it was mostly false, we would need to focus on a handful of models of particular societal importance and hope they stop changing every year. There might also be in between worlds, where some lessons transfer between models but others need to be learned from scratch.
The same logic applies to the study of LLMs: in the ideal case, we would be able to say with reasonable certainty which models should have which circuits (or behaviors) on the basis of model properties—like size, architecture, training data.
That’s a huge technical challenge. As Olah writes, it could be that we live in a world where there’s very little universality: maybe each model is inscrutable in its own way. Even if there is systematicity, identifying and characterizing it in a formal way is a major obstacle. But I think it’s in principle possible, assuming there’s something there to be characterized.
The bigger challenge, as I wrote earlier, might be sociological.
The sociological challenge ahead
To understand the challenge, we can consider how a field of researchers might begin to make progress in the ideal case.
Recall that our goal is to develop a systematic theory connecting model properties (size, architecture, training data, etc.) to model behaviors (e.g., capabilities) and mechanisms (e.g., specific circuits or representations). In order to do that, we’d need to study a very diverse set of models, which vary along all the dimensions that we think might matter. Further, we’d like those different dimensions to be relatively controlled: to study the impact of model size, we’d want to control for things like architecture and the amount of training data—and perhaps even study how those other properties interact with model size. Finally, we’d need information about those models—such as their training data and internal states—to be relatively transparent.
Unfortunately, we don’t live in that world. First, the state-of-the-art models (like OpenAI’s GPT-4 and Anthropic’s Claude) are mostly proprietary: even if we can elicit behavior from those models, researchers outside the companies don’t know how they were trained or what internal mechanisms give rise to that behavior. Second, open-source models (like those available on HuggingFace) are not a representative sample of either architectures or languages: they’re a contingent sample reflecting the various motivations and constraints that guide the LLM research community. For example, right now there are about ~96K models tagged as “English”, ~5K models tagged as “Spanish”, and ~2.8K models tagged as “Hindi”.
Further, available models are, for the most part, not controlled along the relevant dimensions I mentioned above. There are some exceptions, like the Pythia suite of English-language models developed at EleutherAI. The Pythia suite is a set of models varying systematically in their size, all using the same architecture and open training data—allowing researchers to study the impact of model scale on various downstream properties or behaviors. The Allen Institute for AI has also released a number of open-source models, such as OLMo (Open Language Model), which are invaluable for the study and use of LLMs. But these carefully controlled, open-source models are mostly trained on the English language: as far as I know, there’s no Pythia suite for Spanish. That was a genuine source of frustration when my collaborators and I were studying Spanish language models, as it made it hard to determine which behaviors were due to a model’s size, its architecture, or its amount of training data. And unfortunately, training our own set of models would’ve been very expensive and required infrastructure that wasn’t available to us.
This is why I refer to the generalizability challenge as sociological. It’s a function of the resources available to the research community and how that community currently operates. Many individual research labs simply don’t have the capital to train their own models—certainly not on the same scale as companies like Meta, Anthropic, or OpenAI. Those researchers must rely on the existing landscape of models, which isn’t always well-suited to rigorous science: proprietary models pose problems for reproducibility2, and even open-source models (as I mentioned above) are not necessarily controlled along important dimensions. In principle, researchers could pool their resources across labs, though you’d presumably need many research labs to work together to train something on the scale of OpenAI’s GPT-4 (which supposedly cost more than $100 million), which is a hard coordination problem.
I can imagine a couple kinds of solutions to this sociological challenge.
One kind of solution is technical. For example, as researchers continue to develop more efficient, cost-effective methods for training and deploying LLMs, it will become easier (and cheaper) for researchers to participate in that process. The cutting edge of LLMs might always be out of reach in this scenario, but perhaps that doesn’t matter—if researchers can train compact models that perform at the level of GPT-4, it would open up many new avenues for mechanistic interpretability research.
The second kind of solution is sociological. I mentioned above that coordinating resources across researchers might be hard. But what if there were an institute or “center” that acted as a kind of central executive for this coordination process? The center could train and “host” a range of models that do vary along the dimensions we care about, and researchers could apply (or pay) for access to those models. That’s actually not unlike how the HuggingFace Endpoints API works, in the sense that researchers can pay HuggingFace for access to its models and servers. The difference is that I’m imagining something a little more structured, which makes decisions (perhaps from community input) about which kinds of models should be trained, oversees their training, and then grants access to model behaviors and internal states. It might thus look more like the Allen Institute for AI, but bigger, and with even more of a focus on acting as a “hub” for the LLM research community.
Such an institute would of course be incredibly expensive to operate, and would thus depend either on private philanthropy or state funding. I know next to nothing about particle physics, but naively, it strikes me that a nice model for the latter is something like CERN. This “Organization for Large Language Model Research” could be funded by its member-states, and perhaps all researchers affiliated with the center could even have a say in shaping its direction, e.g., which models are trained and what guardrails are put in place to ensure their safe and equitable use.
There are, presumably, many obstacles to the creation of an intergovernmental organization dedicated to researching LLMs. For one thing, there’s the question of justifying the expense. There are lots of other worthy ways that governments can spend their money: is funding an organization to build and provide LLMs of various sizes and languages the best way to spend those tax dollars? As someone with a personal interest in the burgeoning field of LLM-ology, I’d like to think there’s some value—but honestly I’m not sure, and at any rate that’s not really for me to decide.
Related posts:
“Loss” is often calculated by looking at the negative log probability a trained model assigns to actual sequences of words. The idea is that a good language model should assign high probability to genuine word sequences—whereas a bad model would assign lower probabilities, i.e., higher negative log probabilities or “surprisal” values.
To be clear, I understand entirely why companies like Anthropic and OpenAI would want their products to be proprietary! That’s partly why I think a solution based on state funding might be necessary.
The CERN for AI idea is a good one, and has been percolating for awhile (see e.g. https://garymarcus.substack.com/p/a-cern-for-ai-and-the-global-governance). My guess is that if anything like this happens it'll come out of Europe, which is far more adept at international coordination than we Americans are.